dataframe常用操作
Posted pandas-blue
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了dataframe常用操作相关的知识,希望对你有一定的参考价值。
一、创建、取某列某行、删除某列
import pandas as pd lst=[2,3,5] #表示df的一行 df=pd.DataFrame(data=[lst,lst],columns=[‘col1‘,‘col2‘,‘col3‘]) #从列表生成DF df=pd.DataFrame(data={‘col1‘:[2]*2,‘col2‘:[3]*2,‘col3‘:[5]*2})#字典生成DF
df[[‘col1‘,‘col2‘]]#可以取出对第一、二列的数据
df[2:][[‘col1‘,‘col2‘]] #可以取出第2行到最后一行的第1、2列的数据
df.drop(‘col1‘,axis=1)#删除第1列
df.drop([‘col1‘,‘col2‘,axis=1])
二、对一列或者多列作运算
1. 利用map对一列作运算
df[‘col‘] = df[‘col1‘].map(lambda x: x**2) #生成一列,是第1列的平方
2.利用apply对一列或多列作运算
df.index = pd.date_range(‘20190101‘,periods=5) #将原来的index改成以日期为index df[‘col‘] = df.apply(lambda x:x[‘col1‘]*x[‘col2‘], axis=1) #对‘col‘列改写成‘col1‘列的对应行乘以‘col2‘列的对应行
三、求滑动平均
df[‘MA‘] = df[‘col‘].rolling(window=3, center=False).mean()
四、对列作向上或向下的平移变换
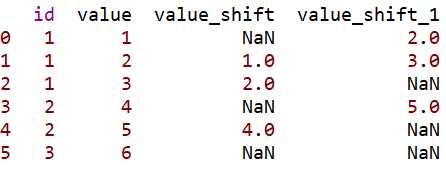
df = pd.DataFrame({‘id‘:[1,1,1,2,2,3],‘value‘:[1,2,3,4,5,6]})
df[‘value_shift‘] = df.groupby(‘id‘)[‘value‘].shift(1) #按id列分组,对value列进行平移变换,即都向下移动1行
df[‘value_shift_1‘] = df.groupby(‘id‘)[‘value‘].shift(-1) #按id列分组,对value列进行平移变换,即都向上移动1行
五、对列作标准化处理:
from sklearn import preprocessing df = pd.DataFrame({‘id‘:[1,1,1,2,2,3],‘value1‘:[1,2,3,4,5,6],‘value2‘:[1,3,4,3,7,2]}) value=df[[‘value1‘,‘value2‘]] value_T=value.transpose() #value_T是array类型 scaler=preprocessing.StandardScaler().fit(value_T) #scaler是对行数据作标准化,所以对df的列数据应该将其转置 value_T_scale = scaler.transform(value_T) value_scale = value_T_scale.transpose() #有时需要用到np.array的reshape: y=df[[‘value‘]] #y.shape=(6,1) y=y.reshape(1,-1) #y.shape=(1,6) y=y.reshape(-1,1) #y.shape=(6,1)
y=np.repeat(0,len(y)) #生成零矩阵
六、对某列赋值
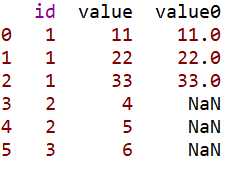
df = pd.DataFrame({‘id‘:[1,1,1,2,2,3],‘value‘:[1,2,3,4,5,6]})
value=[11,22,33]
df.loc[df.index[0:3],‘value‘]=value
df.loc[df.index[0:3], ‘value0‘]=value
七、 对list中多个重复的字符作频数统计
lst=[‘a‘,‘a‘,‘a‘,‘b‘,‘c‘,‘c‘,‘b‘,‘e‘,‘f‘,‘a‘,‘a‘,‘c‘] cnt = pd.Series(lst).value_counts()
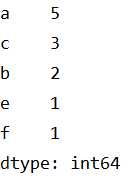
参考:
后续再补充。
以上是关于dataframe常用操作的主要内容,如果未能解决你的问题,请参考以下文章