2019数据智能算法大赛赛后复盘
Posted lvpengbo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2019数据智能算法大赛赛后复盘相关的知识,希望对你有一定的参考价值。
趁着刚开学这段时间参加了一个比赛《2019数据智能算法大赛》,最终结果:26/694
赛题:商家客户购买转化率预测
购买转化率是品牌商家在电商平台运营时最关注的指标之一,本次大赛中云积互动提供了品牌商家的历史订单数据,参赛选手通过人工智能技术构建预测模型,预估用户人群在规定时间内产生购买行为的概率。
数据格式:
具体说明如下: 1. 训练集:round2_diac2019_train.csv ,每行数据代表一个训练样本,各字段之间由逗号分隔,包含一次购买行为中的基础信息与上下文信息。 2. 测试集: round2_diac2019_test.csv ,每行数据代表一个测试样本,格式为“customer_id, result”,代表用户ID和预测结果。 3. 各类字段数据的描述如下:
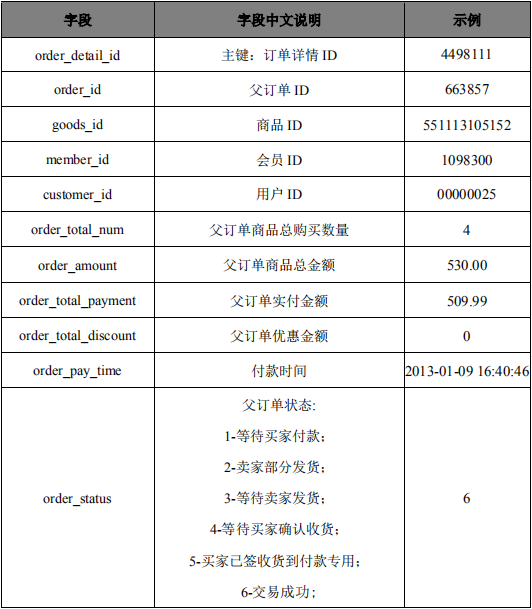
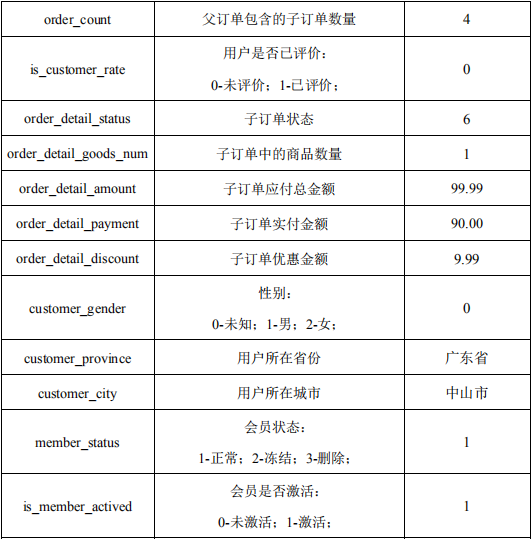
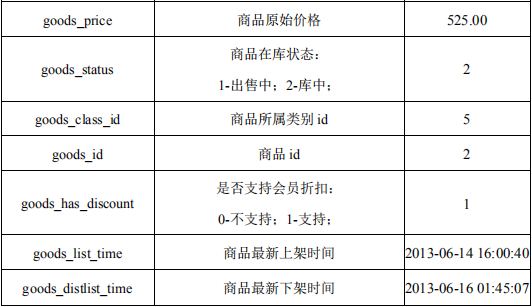
评分标准:
评分标准
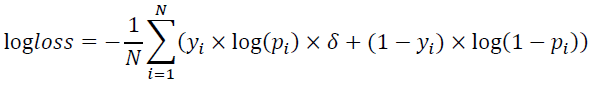
其中N表示测试集样本数量,yi表示测试集中第i个样本的真实标签,pi表示第 i个样本的预估转化率, δ为惩罚系数。
AB榜的划分方式和比例:
【1】评分采用AB榜形式。排行榜显示A榜成绩,竞赛结束后2小时切换成B榜单。B榜成绩以选定的两次提交或者默认的最后两次提交的最高分为准,最终比赛成绩以B榜单为准。
【2】此题目的AB榜数据采用同时段数据是随机划分,A榜为随机抽样测试集50%数据,B榜为其余50%的数据。
我们的思路:
根据划分时间段,将数据划分为训练集和测试集,根据给的信息进行groupby和聚合操作,利用Xgboost算法,最终结果未进复赛:
先放上我们的代码:


1 ‘‘‘ 2 数据预处理 3 ‘‘‘ 4 import pandas as pd 5 import numpy as np 6 from xgboost import plot_importance 7 import xgboost as xgb 8 from matplotlib import pyplot as plt 9 from sklearn.model_selection import train_test_split 10 import datetime 11 import warnings 12 warnings.filterwarnings(‘ignore‘) 13 # 读取原始数据 14 15 train = pd.read_csv(‘./round1_diac2019_train.csv‘,low_memory=False) 16 17 all_customer = pd.DataFrame(train[[‘customer_id‘]]).drop_duplicates([‘customer_id‘]).dropna() 18 19 train[‘order_pay_time‘] = pd.to_datetime(train[‘order_pay_time‘]) 20 train[‘order_pay_date‘] = train[‘order_pay_time‘].dt.date #取日期 生成一个新的列 order_pay_date 21 off_train = train[(train[‘order_pay_date‘].astype(str)<=‘2013-07-03‘)] #用于预测 22 off_test = train[(train.order_pay_date.astype(str)>‘2013-07-03‘)&(train.order_pay_date !=‘null‘)] #用作上半年的标签 23 online_train = train 24 25 26 27 28 29 def feature_and_label(train_data,test_data,islabel): 30 ‘‘‘ 31 提取特征,构建特征集和标签 32 ‘‘‘ 33 # t1 代表用户购买同种货物的次数 34 t1 = train_data[[‘customer_id‘,‘goods_id‘,‘order_pay_date‘,‘order_detail_goods_num‘]] 35 t1 = t1[t1.order_pay_date !=‘null‘] 36 t1 = t1.groupby([‘customer_id‘,‘goods_id‘])[‘order_detail_goods_num‘].agg(‘sum‘).reset_index() 37 t1 = t1.groupby(‘customer_id‘)[‘goods_id‘,‘order_detail_goods_num‘].agg(‘max‘) 38 t1.rename(columns={‘goods_id‘:‘customer_max_goods‘},inplace=True) 39 # t2 代表用户下单数 40 t2 = train_data[[‘customer_id‘,‘order_id‘,‘order_pay_date‘]] 41 t2 = t2[t2.order_pay_date !=‘null‘] 42 t2[‘user_order_num‘] = 1 43 t2 = t2.groupby(‘customer_id‘).agg(‘sum‘).reset_index() 44 # t3 代表商品价格 45 t3 = train_data[[‘customer_id‘,‘goods_price‘,‘order_pay_date‘]] 46 t3 = t3[t3.order_pay_date !=‘null‘] 47 t3 = t3.groupby(‘customer_id‘)[‘goods_price‘].agg({‘price_mean‘:‘mean‘,‘price_max‘:‘max‘,‘price_min‘:‘min‘}) 48 # t4 代表用户的订单购买时间 49 t4 = train_data[[‘customer_id‘,‘order_pay_date‘]] 50 t4 = t4[t4.order_pay_date != ‘null‘] 51 t4 = t4.groupby([‘customer_id‘],as_index=False)[‘order_pay_date‘].agg({‘order_pay_date_first‘:‘min‘,‘order_pay_date_last‘:‘max‘}) 52 t4[‘long_time‘] = pd.to_datetime(t4[‘order_pay_date_last‘]) - pd.to_datetime(t4[‘order_pay_date_first‘]) 53 t4[‘long_time‘] = t4[‘long_time‘].dt.days + 1 54 # t5 代表用户是否喜欢参与评价 55 t5 = train_data[[‘customer_id‘,‘is_customer_rate‘]] 56 t5 = t5.replace(np.nan,0) 57 t5 = t5.groupby(‘customer_id‘)[‘is_customer_rate‘].agg(‘sum‘).reset_index() 58 # t6 代表父订单商品购买数量 59 t6 = train_data[[‘customer_id‘,‘order_total_num‘,‘order_pay_date‘]] 60 t6 = t6[t6.order_pay_date != ‘null‘] 61 t6 = t6.groupby(‘customer_id‘)[‘order_total_num‘].agg({‘order_num_mean‘:‘mean‘}) 62 # t7 代表父订单商品购买数量 63 t7 = train_data[[‘customer_id‘,‘order_total_payment‘]] 64 t7 = t7.groupby(‘customer_id‘)[‘order_total_payment‘].agg({‘order_pay_mean‘:‘mean‘}) 65 # t8 代表父订单优惠金额 66 t8 = train_data[[‘customer_id‘,‘order_total_discount‘]] 67 t8 = t8.groupby(‘customer_id‘)[‘order_total_discount‘].agg({‘order_discount_mean‘:‘mean‘}) 68 # t9 代表子订单商品购买数量 69 t9 = train_data[[‘customer_id‘,‘order_detail_amount‘]] 70 t9 = t9.groupby(‘customer_id‘)[‘order_detail_amount‘].agg({‘order_amount_mean‘:‘mean‘}) 71 72 # t10 代表子订单应付总金额 73 t10 = train_data[[‘customer_id‘,‘order_detail_payment‘]] 74 t10 = t10.groupby(‘customer_id‘)[‘order_detail_payment‘].agg({‘detail_pay_mean‘:‘mean‘}) 75 # t11 代表是否支持会员折扣 76 t11 = train_data[[‘customer_id‘,‘goods_has_discount‘]] 77 t11 = t11.groupby(‘customer_id‘)[‘goods_has_discount‘].agg({‘goods_discount_mean‘:‘mean‘}) 78 # t12 代表 79 t12 = train_data[[‘customer_id‘,‘customer_gender‘,‘member_status‘]].drop_duplicates([‘customer_id‘]) 80 t12 = t12.fillna(0) 81 # t13 82 t13 = train_data[[‘customer_id‘,‘order_count‘]] 83 t13 = t13.groupby(‘customer_id‘)[‘order_count‘].agg({‘order_count_mean‘:‘mean‘}) 84 # t14 85 t14 = train_data[[‘customer_id‘,‘order_status‘]] 86 t14 = t14.groupby(‘customer_id‘)[‘order_status‘].agg({‘order_status_mean‘:‘mean‘}) 87 88 # 特征组合 89 feature_set = pd.merge(t1,t2,on=‘customer_id‘,how=‘left‘) 90 feature_set = pd.merge(feature_set,t3,on=‘customer_id‘,how=‘left‘) 91 feature_set = pd.merge(feature_set,t4,on=‘customer_id‘,how=‘left‘) 92 feature_set = pd.merge(feature_set,t5,on=‘customer_id‘,how=‘left‘) 93 feature_set = pd.merge(feature_set,t6,on=‘customer_id‘,how=‘left‘) 94 feature_set = pd.merge(feature_set,t7,on=‘customer_id‘,how=‘left‘) 95 feature_set = pd.merge(feature_set,t8,on=‘customer_id‘,how=‘left‘) 96 feature_set = pd.merge(feature_set,t9,on=‘customer_id‘,how=‘left‘) 97 feature_set = pd.merge(feature_set,t10,on=‘customer_id‘,how=‘left‘) 98 feature_set = pd.merge(feature_set,t11,on=‘customer_id‘,how=‘left‘) 99 feature_set = pd.merge(feature_set,t12,on=‘customer_id‘,how=‘left‘) 100 feature_set = pd.merge(feature_set,t13,on=‘customer_id‘,how=‘left‘) 101 feature_set = pd.merge(feature_set,t14,on=‘customer_id‘,how=‘left‘) 102 feature_set.drop_duplicates([‘customer_id‘]) 103 del feature_set[‘order_pay_date_first‘] 104 # 构建标签 105 if islabel==False: 106 feature_set[‘order_pay_date_last‘] = pd.to_datetime(test_data[‘order_pay_date‘].min()) - pd.to_datetime(feature_set[‘order_pay_date_last‘]) 107 feature_set[‘order_pay_date_last‘] = feature_set[‘order_pay_date_last‘].dt.days + 1 108 feature_set[‘label‘] = 0 109 feature_set.loc[feature_set[‘customer_id‘].isin(list(test_data[‘customer_id‘].unique())),‘label‘] = 1 110 else: 111 feature_set[‘order_pay_date_last‘] = pd.to_datetime(‘2013-12-31‘) - pd.to_datetime(feature_set[‘order_pay_date_last‘]) 112 feature_set[‘order_pay_date_last‘] = feature_set[‘order_pay_date_last‘].dt.days + 1 113 114 return feature_set 115 116 ‘‘‘ 117 数据抽取 118 ‘‘‘ 119 train_cup = feature_and_label(off_train,off_test,False) 120 submit = feature_and_label(online_train,None,True) 121 y = train_cup.pop(‘label‘) 122 feature = [x for x in train_cup.columns if x not in [‘customer_id‘]] 123 X = train_cup[feature] 124 125 ‘‘‘ 126 分割+算法实践 127 128 ‘‘‘ 129 X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.35, random_state=42,stratify=y) 130 131 submit_df = submit[[‘customer_id‘]] 132 X_submit = submit[feature] 133 134 params ={‘learning_rate‘: 0.1, 135 ‘max_depth‘: 6, 136 ‘num_boost_round‘:3000, 137 ‘objective‘: ‘binary:logistic‘, 138 ‘random_state‘: 7, 139 ‘silent‘:0, 140 ‘eta‘:0.8, 141 ‘eval_metric‘:‘auc‘ 142 } 143 dtrain = xgb.DMatrix(X_train, y_train) 144 dvalid = xgb.DMatrix(X_valid, y_valid) 145 dtest = xgb.DMatrix(X_submit) 146 evallist = [(dtrain,"train"),(dvalid,"valid")] 147 bst = xgb.train(params, dtrain, evals=evallist, early_stopping_rounds=30) 148 y_submit = bst.predict(dtest, ntree_limit = bst.best_ntree_limit) 149 submit_df[‘result‘] = y_submit 150 151 submit_df 152 153 # 写入最终数据 154 submit_df = submit_df.drop(0) 155 submit_df.to_csv(‘xgboost_simple.csv‘,index=False) 156 157 158 feature_score = bst.get_fscore() 159 feature_score = sorted(feature_score.items(), key=lambda x:x[1],reverse=True) 160 fs = [] 161 for (key,value) in feature_score: 162 fs.append("{0},{1} ".format(key,value)) 163 164 with open(‘result/xgb_feature_score.txt‘,‘w‘) as f: 165 f.writelines("feature,score ") 166 f.writelines(fs)
反思问题:
1、对数据竞赛的认识不够充分,未能充分与其他参赛选手沟通,参赛经验太少,都是自己在闭门造车,以后如果要参加的话,需要多看看大佬的分享,积累些经验;
2、找好队友很重要,本次队友之前并未接触过此类比赛,导致主要工作都是自己在做,未能有效发挥团队的优势,与队友未能有效沟通,导致队友的工作主要集中在调参;
3、通过这次比赛真正认识到了,打比赛是真的累,每天睁眼闭眼想的都是特征的构建,然后构建出来,发现效果反而下降,搞得人心累,特征这块真的有种炼丹的感觉,只能去试试,自己感觉没有一套所谓的逻辑在背后(也可能是自己认识太短浅);
4、自己python功底还是不好,代码量不够,以后需要对深度学习框架进行学习,多敲代码,积累代码量。
最后:
有个好队友真的很重要,很重要很重要很重要,多沟通;
数据特征很重要,算法是其次,在做的过程中,先调好算法,写出Baseline,再根据其进行优化特征,会好很多,此次想用多个算法融合进行优化,但发现结果更差了,还是对这些算法框架的使用不是很熟悉。
接下来,估计没那么多时间做比赛咯,期末了,准备六级+考试,哈哈哈!
以上是关于2019数据智能算法大赛赛后复盘的主要内容,如果未能解决你的问题,请参考以下文章