十 MHA高可用及读写分离
Posted chenmiao531759321
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了十 MHA高可用及读写分离相关的知识,希望对你有一定的参考价值。
- 一.MHA简介
- 二.工作流程
- 三.MHA架构图
- 四.MHA工具介绍
- 五.基于GTID的主从复制
- 六.部署MHA
- 七.配置VIP漂移
- 八.配置binlog-server
- 九.mysql中间件Atlas
一.MHA简介

作者简介
松信嘉範:
MySQL/Linux专家
2001年索尼公司入职
2001年开始使用oracle
2004年开始使用MySQL
2006年9月-2010年8月MySQL从事顾问
2010年-2012年 DeNA
2012年~至今 Facebook
软件简介
MHA能够在较短的时间内实现自动故障检测和故障转移,通常在10-30秒以内;在复制框架中,MHA能够很好地解决复制过程中的数据一致性问题,由于不需要在现有的replication中添加额外的服务器,仅需要一个manager节点,而一个Manager能管理多套复制,所以能大大地节约服务器的数量;另外,安装简单,无性能损耗,以及不需要修改现有的复制部署也是它的优势之处。
MHA还提供在线主库切换的功能,能够安全地切换当前运行的主库到一个新的主库中(通过将从库提升为主库),大概0.5-2秒内即可完成。
MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以独立部署在一台独立的机器上管理多个Master-Slave集群,也可以部署在一台Slave上。当Master出现故障时,它可以自动将最新数据的Slave提升为新的Master,然后将所有其他的Slave重新指向新的Master。整个故障转移过程对应用程序是完全透明的。
二.工作流程
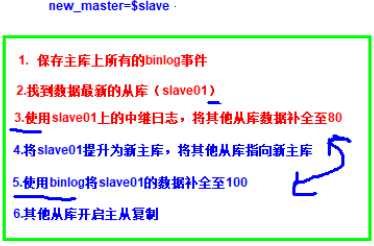
1)把宕机的master二进制日志保存下来。
2)找到binlog位置点最新的slave。
3)在binlog位置点最新的slave上用relay log(差异日志)修复其它slave。
4)将宕机的master上保存下来的二进制日志恢复到含有最新位置点的slave上。
5)将含有最新位置点binlog所在的slave提升为master。
6)将其它slave重新指向新提升的master,并开启主从复制。
三.MHA架构图
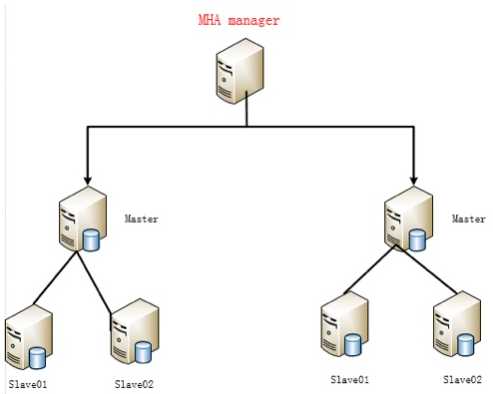
1.MHA是一个C/S结构的服务
2.MHA可以安装在任意一台服务器上
3.一个MHA管理节点可以管理上百套replication
4.MHA管理节点,尽量避免装在主库上(避免断电,断网)
如果装在slave02上,slave02被提升为主库?
不让slave02提升为主库(no master)
5.MHA是由manager和node组成,manager是服务端,node是客户端
四.MHA工具介绍
MHA软件由两部分组成,Manager工具包和Node工具包,具体的说明如下:
Manager工具包主要包括以下几个工具:
[root@db01 ~]# tar xf mha4mysql-manager-0.56.tar.gz
[root@db01 bin]# pwd
/root/mha4mysql-manager-0.56/bin
[root@db01 bin]# ll
masterha_check_ssh #检查MHA的ssh-key免密登录
masterha_check_repl #检查主从复制情况
masterha_manger #启动MHA
masterha_check_status #检测MHA的运行状态
masterha_master_monitor #检测master是否宕机
masterha_master_switch #手动故障转移
masterha_conf_host #手动添加server信息
masterha_secondary_check #建立TCP连接从远程服务器
masterha_stop #停止MHANode工具包主要包括以下几个工具:
[root@db01 ~]# tar xf mha4mysql-node-0.56.tar.gz
[root@db01 bin]# pwd
/root/mha4mysql-node-0.56/bin
[root@db01 bin]# ll
save_binary_logs #保存宕机的master的binlog
apply_diff_relay_logs #识别relay log的差异
filter_mysqlbinlog #截取binlog
purge_relay_logs #删除relay-logMHA优点总结
1)Masterfailover and slave promotion can be done very quickly
自动故障转移快 0-30
2)Mastercrash does not result in data inconsistency
主库崩溃不存在数据一致性问题
3)Noneed to modify current MySQL settings (MHA works with regular MySQL)
不需要对当前mysql环境做重大修改
4)Noneed to increase lots of servers
不需要添加额外的服务器(仅一台manager就可管理上百个replication)
5)Noperformance penalty
性能优秀,可工作在半同步复制和异步复制,当监控mysql状态时,仅需要每隔N秒向master发送ping包(默认3秒),所以对性能无影响。你可以理解为MHA的性能和简单的主从复制框架性能一样。
6)Works with any storage engine
只要replication支持的存储引擎,MHA都支持,不会局限于innodb
MySQL环境准备
1)环境检查
#mysql版本
mysql:5.6.44
#mysql配置文件
[root@db01 ~]# vim /etc/my.cnf
[mysqld]
#db01、db02安装目录为/application
#db03、db04安装目录为/optmysql-db01
#系统版本
[root@mysql-db01 ~]# cat /etc/redhat-release
CentOS Linux release 7.6.1810 (Core)
#内核版本
[root@mysql-db01 ~]# uname -r
3.10.0-957.el7.x86_64
#IP地址
[root@mysql-db01 ~]# hostname -I
10.0.0.51 172.16.1.51 mysql-db02
#系统版本
[root@mysql-db02 ~]# cat /etc/redhat-release
CentOS Linux release 7.6.1810 (Core)
#内核版本
[root@mysql-db02 ~]# uname -r
3.10.0-957.el7.x86_64
#IP地址
[root@mysql-db02 ~]# hostname -I
10.0.0.52 172.16.1.52mysql-db03
#系统版本
[root@mysql-db03 ~]# cat /etc/redhat-release
CentOS Linux release 7.6.1810 (Core)
#内核版本
[root@mysql-db03 ~]# uname -r
3.10.0-957.el7.x86_64
#IP地址
[root@mysql-db03 ~]# hostname -I
10.0.0.53 172.16.1.53安装MySQL
1)安装包准备
#创建安装包存放目录
[root@mysql-db01 ~]# mkdir /home/oldboy/tools -p
#进入目录
[root@mysql-db01 ~]# cd /home/oldboy/tools/
#上传mysql安装包(mysql-5.6.16-linux-glibc2.5-x86_64.tar.gz)
[root@mysql-db01 tools]# rz -be2)安装
#创建安装目录
[root@mysql-db01 tools]# mkdir /application
#解压mysql二进制包
[root@mysql-db01 tools]# tar xf mysql-5.6.16-linux-glibc2.5-x86_64.tar.gz
#移动安装包
[root@mysql-db01 tools]# mv mysql-5.6.16-linux-glibc2.5-x86_64 /application/mysql-5.6.16
#做软链接
[root@mysql-db01 tools]# ln -s /application/mysql-5.6.16/ /application/mysql
#创建mysql用户
[root@mysql-db01 tools]# useradd mysql -s /sbin/nologin -M
#进入mysql初始化目录
[root@mysql-db01 tools]# cd /application/mysql/scripts/
#初始化mysql
[root@mysql-db01 scripts]# ./mysql_install_db --user=mysql --datadir=/application/mysql/data/ --basedir=/application/mysql/
#注解
--user: 指定mysql用户
--datadir:指定mysql数据存放目录
--basedir:指定mysql base目录
#拷贝mysql配置文件
[root@mysql-db01 ~]# cp /application/mysql/support-files/my-default.cnf /etc/my.cnf
#拷贝mysql启动脚本
[root@mysql-db01 ~]# cp /application/mysql/support-files/mysql.server /etc/init.d/mysqld
#修改mysql默认安装目录(否则无法启动)
[root@mysql-db01 ~]# sed -i 's#/usr/local#/application#g' /etc/init.d/mysqld
[root@mysql-db01 ~]# sed -i 's#/usr/local#/application#g' /application/mysql/bin/mysqld_safe
#配置mysql环境变量
[root@mysql-db01 ~]# echo 'export PATH="/application/mysql/bin:$PATH"' >> /etc/profile.d/mysql.sh
#刷新环境变量
[root@mysql-db01 ~]# source /etc/profile
2.2.3启动
#加入开机自启
[root@mysql-db01 ~]# chkconfig mysqld on
#启动mysql
[root@mysql-db01 ~]# /etc/init.d/mysqld start
Starting MySQL........... SUCCESS! #启动成功
2.2.4配置密码
#配置mysql密码为oldboy123
[root@mysql-db01 ~]# mysqladmin -uroot password oldboy123五.基于GTID的主从复制
1)什么是GTID?
GTID(Global Transaction ID)全局事务标识符:是一个唯一标识符,它创建并与源服务器(主) 上提交的每个事务相关联。
此标识符不仅对其发起的服务器是唯一的,而且在给定复制设置中的所有服务器上都是唯一的。所有交易和所有GTID之间都有1对1的映射。
GTID实际上是由UUID+TID组成的。其中UUID是一个MySQl 实例的唯一标识。 TID代表 了该实例上已经提交的事务数量,并且随着事务提交单调递增。
下面是一个GTID的具体形式:
342a3b8f-0d8e-11ea-8095-000c29c7dac3:1
342a3b8f-0d8e-11ea-8095-000c29c7dac3:2
342a3b8f-0d8e-11ea-8095-000c29c7dac3:3
2)GTID新特性
(1).支持多线程复制:事实上是针对每个database开启相应的独立线程,即每个库有一个单独的(sql thread).
(2).支持启用GTID,在配置主从复制,传统的方式里,你需要找到binlog和POS点,然后change master to指向.
在mysql5.6里,无须再知道binlog和POS点,只需要知道master的IP/端口/账号密码即可,因为同步复制是自动的,MySQL通过内部机制GTID自动找点同步.(show master status)
(3).基于Row复制只保存改变的列,大大节省Disk Space/Network resources和Memory usage.
(4).支持把Master 和Slave的相关信息记录在Table中
原来是记录在文件里,记录在表里,增强可用性
(5).支持延迟复制
先决条件
1)主库和从库都要开启binlog
2)主库和从库server-id不同
3)要有主从复制用户
主库操作
修改配置文件
#编辑mysql配置文件
[root@mysql-db01 ~]# vim /etc/my.cnf
[mysqld] #在mysqld标签下配置
server_id =1 #主库server-id为1,从库不等于1
log_bin=mysql-bin #开启binlog日志创建主从复制用户
#登录数据库
[root@mysql-db01 ~]# mysql -uroot -p123
#创建主从复制用户rep用户
mysql> grant replication slave on *.* to rep@'10.0.0.%' identified by '123';从库操作
修改配置文件
#修改mysql-db02配置文件
[root@mysql-db02 ~]# vim /etc/my.cnf
[mysqld] #在mysqld标签下配置
server_id =2 #主库server-id为1,从库必须不为1
log_bin=mysql-bin #开启binlog日志
#重启mysql
[root@mysql-db02 ~]# /etc/init.d/mysqld restart
#修改mysql-db03配置文件
[root@mysql-db03 ~]# vim /etc/my.cnf
[mysqld] #在mysqld标签下配置
server_id =3 #主库server-id为1,从库必须不为1
log_bin=mysql-bin #开启binlog日志
#重启mysql
[root@mysql-db03 ~]# /etc/init.d/mysqld restart
#修改mysql-db04配置文件
[root@db04 ~]# vim /etc/my.cnf
[mysqld]
server_id=4
log_bin=mysql-bin
#重启mysql
[root@mysql-db04 ~]# /etc/init.d/mysqld restart注:在以往如果是基于binlog日志的主从复制,则必须要记住主库的master状态信息。
mysql> show master status;
+------------------+----------+
| File | Position |
+------------------+----------+
| mysql-bin.000002 | 120 |
+------------------+----------+开启GTID
#没开启之前先看一下GTID的状态
mysql> show variables like '%gtid%';
+---------------------------------+-----------+
| Variable_name | Value |
+---------------------------------+-----------+
| binlog_gtid_simple_recovery | OFF |
| enforce_gtid_consistency | OFF |
| gtid_executed | |
| gtid_mode | OFF |
| gtid_next | AUTOMATIC |
| gtid_owned | |
| gtid_purged | |
| simplified_binlog_gtid_recovery | OFF |
+---------------------------------+-----------+
8 rows in set (0.01 sec)
#编辑mysql配置文件(主库从库都需要修改)
[root@mysql-db01 ~]# vim /etc/my.cnf
[mysqld] #在[mysqld]标签下添加
gtid_mode=ON
log_slave_updates
enforce_gtid_consistency
#重启数据库
[root@mysql-db01 ~]# /etc/init.d/mysqld restart
#检查GTID状态
mysql> show global variables like '%gtid%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| enforce_gtid_consistency | ON | #执行GTID一致
| gtid_executed | |
| gtid_mode | ON | #开启GTID模块
| gtid_owned | |
| gtid_purged | |
+--------------------------+-------+注:主库从库都需要开启GTID否则在做主从复制的时候就会报错:
[root@mysql-db02 ~]# mysql -uroot -p123
mysql> change master to
master_host='10.0.0.51',
master_user='rep',
master_password='123',
master_auto_position=1;
ERROR 1777 (HY000): CHANGE MASTER TO MASTER_AUTO_POSITION = 1 can only be executed when @@GLOBAL.GTID_MODE = ON.log-slave-updates:都什么时候会用到这个参数?
答:1.双主模式
? 2.级联复制
? 3.GTID
配置主从复制
#登录数据库
[root@mysql-db02 ~]# mysql -uroot -p123
#配置复制主机信息
mysql> change master to
#主库IP
-> master_host='10.0.0.51',
#主库复制用户
-> master_user='rep',
#主库复制用户的密码
-> master_password='123',
#GTID位置点
-> master_auto_position=1;
#开启slave
mysql> start slave;
#查看slave状态
mysql> show slave statusG
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.51
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
Read_Master_Log_Pos: 403
Relay_Log_File: mysql-db02-relay-bin.000002
Relay_Log_Pos: 613
Relay_Master_Log_File: mysql-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 403
Relay_Log_Space: 822
Until_Condition: None从库设置
#登录从库
[root@mysql-db02 ~]# mysql -uroot -p123
#禁用自动删除relay log 功能(主库和从库)
mysql> set global relay_log_purge = 0;
#设置只读
mysql> set global read_only=1;
#编辑配置文件
[root@mysql-db02 ~]# vim /etc/my.cnf
[mysqld] #在mysqld标签下添加
relay_log_purge = 0 #禁用自动删除relay log 永久生效(主库和从库)1.主库:开启binlog和server_id
2.从库:不开启binlog,server_id可以相同
如果要做MHA:从库必须开启binlog,server_id必须不相同
六.部署MHA
环境准备(所有节点)
# 安装node和manager,必须要有epel
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
# 安装node节点(有几台数据库就装几个node节点)
[root@db01 ~]# yum localinstall -y mha4mysql-node-0.56-0.el6.noarch.rpm
# 每台数据库上都要创建 mha 管理用户(主库执行从库会复制)
mysql> grant all on *.* to mha@'%' identified by 'mha';
#查看是否添加成功
mysql> select user,host from mysql.user;
#主库上创建,从库会自动复制(在从库上查看)
mysql> select user,host from mysql.user;命令软连接(所有节点)
#如果不创建命令软连接,检测mha复制情况的时候会报错
[root@mysql-db01 ~]# ln -s /application/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
[root@mysql-db03 ~]# ln -s /opt/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
[root@mysql-db01 ~]# ln -s /application/mysql/bin/mysql /usr/bin/mysql
[root@mysql-db03 ~]# ln -s /opt/mysql/bin/mysql /usr/bin/mysql部署管理节点(mha-manager:mysql-db04)
# 安装manager
[root@db04 ~]# yum localinstall -y mha4mysql-manager-0.56-0.el6.noarch.rpm编辑配置文件
#创建配置文件目录
[root@mysql-db04 ~]# mkdir -p /etc/mha
#编辑mha配置文件
[root@mysql-db04 ~]# vim /etc/mha/app1.cnf
[server default]
manager_log=/etc/mha/manager.log
manager_workdir=/etc/mha/app1
master_binlog_dir=/application/mysql/data
user=mha
password=mha
ping_interval=2
repl_password=123
repl_user=rep
ssh_user=root
[server1]
hostname=10.0.0.51
port=3306
[server2]
#candidate_master=1
#check_repl_delay=0
hostname=10.0.0.52
port=3306
[server3]
master_binlog_dir=/opt/mysql/data
hostname=10.0.0.53
port=3306
[server4]
master_binlog_dir=/opt/mysql/data
hostname=10.0.0.54
port=3306配置文件详解
[server default]
#设置manager的工作目录
manager_workdir=/etc/mha/app1
#设置manager的日志
manager_log=/etc/mha/manager.log
#设置master 保存binlog的位置,以便MHA可以找到master的日志,我这里的也就是mysql的数据目录
master_binlog_dir=/application/mysql/data
#设置自动failover时候的切换脚本
master_ip_failover_script= /usr/local/bin/master_ip_failover
#设置手动切换时候的切换脚本
master_ip_online_change_script= /usr/local/bin/master_ip_online_change
#设置mysql中root用户的密码,这个密码是前文中创建监控用户的那个密码
password=123
#设置监控用户root
user=root
#设置监控主库,发送ping包的时间间隔,尝试三次没有回应的时候自动进行failover
ping_interval=1
#设置远端mysql在发生切换时binlog的保存位置
remote_workdir=/tmp
#设置复制用户的密码
repl_password=123
#设置复制环境中的复制用户名
repl_user=rep
#设置发生切换后发送的报警的脚本
report_script=/usr/local/send_report
#一旦MHA到server02的监控之间出现问题,MHA Manager将会尝试从server03登录到server02
secondary_check_script= /usr/local/bin/masterha_secondary_check -s server03 -s server02 --user=root --master_host=server02 --master_ip=192.168.0.50 --master_port=3306
#设置故障发生后关闭故障主机脚本(该脚本的主要作用是关闭主机放在发生脑裂,这里没有使用)
shutdown_script=""
#设置ssh的登录用户名
ssh_user=root
[server1]
hostname=10.0.0.51
port=3306
[server2]
hostname=10.0.0.52
port=3306
#设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave。
candidate_master=1
#默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
check_repl_delay=0推送公钥(所有节点)
#创建秘钥对
[root@mysql-db01 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1
#发送公钥,包括自己
[root@mysql-db01 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@10.0.0.51
[root@mysql-db01 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@10.0.0.52
[root@mysql-db01 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@10.0.0.53
[root@mysql-db01 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@10.0.0.54
[root@db02 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1
[root@db02 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub root@10.0.0.51
[root@db02 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub root@10.0.0.52
[root@db02 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub root@10.0.0.53
[root@db02 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub root@10.0.0.54
[root@db03 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1
[root@db03 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub root@10.0.0.51
[root@db03 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub root@10.0.0.52
[root@db03 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub root@10.0.0.53
[root@db03 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub root@10.0.0.54
[root@db04 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1
[root@db04 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub root@10.0.0.51
[root@db04 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub root@10.0.0.52
[root@db04 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub root@10.0.0.53
[root@db04 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub root@10.0.0.54启动测试
#测试ssh
[root@mysql-db04 ~]# masterha_check_ssh --conf=/etc/mha/app1.cnf
#看到如下字样,则测试成功
Tue Nov 19 20:25:11 2019 - [info] All SSH connection tests passed successfully.
#测试复制
[root@mysql-db04 ~]# masterha_check_repl --conf=/etc/mha/app1.cnf
#看到如下字样,则测试成功
MySQL Replication Health is OK.启动MHA
#启动
[root@mysql-db04 ~]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /etc/mha/manager.log 2>&1 &
#查看
[root@db04 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:12000) is running(0:PING_OK), master:10.0.0.51切换master测试
#登录数据库(db02)
[root@mysql-db02 ~]# mysql -uroot -poldboy123
#检查复制情况
mysql> show slave statusG
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.51
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000006
Read_Master_Log_Pos: 191
Relay_Log_File: mysql-db02-relay-bin.000002
Relay_Log_Pos: 361
Relay_Master_Log_File: mysql-bin.000006
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
#登录数据库(db03)
[root@mysql-db03 ~]# mysql -uroot -p123
#检查复制情况
mysql> show slave statusG
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.51
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000006
Read_Master_Log_Pos: 191
Relay_Log_File: mysql-db03-relay-bin.000002
Relay_Log_Pos: 361
Relay_Master_Log_File: mysql-bin.000006
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
#停掉主库
[root@mysql-db01 ~]# /etc/init.d/mysqld stop
Shutting down MySQL..... SUCCESS!
#登录数据库(db02)
[root@mysql-db02 ~]# mysql -uroot -p123
#查看slave状态
mysql> show slave statusG
#db02的slave已经为空
Empty set (0.00 sec)
#登录数据库(db03)
[root@mysql-db03 ~]# mysql -uroot -py123
#查看slave状态
mysql> show slave statusG
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.52
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000006
Read_Master_Log_Pos: 191
Relay_Log_File: mysql-db03-relay-bin.000002
Relay_Log_Pos: 361
Relay_Master_Log_File: mysql-bin.000006
Slave_IO_Running: Yes
Slave_SQL_Running: Yes恢复MHA集群
# 1.修复旧主库
[root@db01 ~]# /etc/init.d/mysqld start
# 2.在mha日志中找到change master语句
[root@db04 ~]# grep -i 'change master to' /etc/mha/manager.log
Tue Nov 19 20:49:31 2019 - [info] All other slaves should start replication from here.
Statement should be: CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=3306,
MASTER_AUTO_POSITION=1, MASTER_USER='slave', MASTER_PASSWORD='123';
# 3.在旧主库中执行change master语句
CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1,
MASTER_USER='slave', MASTER_PASSWORD='123';
# 4.将mha配置文件修复
[server1]
hostname=10.0.0.51
port=3306
# 5.启动mha
[root@db04 ~]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /etc/mha/manager.log 2>&1 &
##### MHA启动命令 详解
nohup masterha_manager
--conf=/etc/mha/app1.cnf
#从配置文件中移除旧主库
--remove_dead_master_conf
#忽略上一次切换
--ignore_last_failover
## mha工作机制:在mha一次切换后,会在mha的工作目录下生成一个lock,锁文件MHA切换
如果在数据量相同的情况下,根据配置文件中的server标签,越小优先级越高。
七.配置VIP漂移
VIP漂移的两种方式
1)通过keepalived的方式,管理虚拟IP的漂移
2)通过MHA自带脚本方式,管理虚拟IP的漂移
MHA脚本方式
修改配置文件
#编辑配置文件
[root@mysql-db04 ~]# vim /etc/mha/app1.cnf
#在[server default]标签下添加
[server default]
#使用MHA自带脚本
master_ip_failover_script=/etc/mha/master_ip_failover编辑脚本
#根据配置文件中脚本路径编辑
[root@mysql-db04 ~]# vim /etc/mha/master_ip_failover
#修改以下几行内容
my $vip = '10.0.0.55/24';
my $key = '0';
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
#添加执行权限,否则mha无法启动
[root@mysql-db04 ~]# chmod +x /etc/mha/master_ip_failover
# 1.权限问题
[root@db04 mha]# chmod +x master_ip_failover
# 2.语法问题
# 3.格式问题
[root@db04 mha]# dos2unix master_ip_failover
dos2unix: converting file master_ip_failover to Unix format ...手动绑定VIP
#绑定vip(手动绑定vip在主库上)
[root@mysql-db01 ~]# ifconfig eth0:0 10.0.0.55/24
#查看vip
[root@mysql-db01 ~]# ip a |grep eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
inet 10.0.0.51/24 brd 10.0.0.255 scope global eth0
inet 10.0.0.55/24 brd 10.0.0.255 scope global secondary eth0:0测试ip漂移
#登录db02
[root@mysql-db02 ~]# mysql -uroot -p123
#查看slave信息
mysql> show slave statusG
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.51
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000007
Read_Master_Log_Pos: 191
Relay_Log_File: mysql-db02-relay-bin.000002
Relay_Log_Pos: 361
Relay_Master_Log_File: mysql-bin.000007
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
#停掉主库
[root@mysql-db01 ~]# /etc/init.d/mysqld stop
Shutting down MySQL..... SUCCESS!
#在db03上查看从库slave信息
mysql> show slave statusG
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.52
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000006
Read_Master_Log_Pos: 191
Relay_Log_File: mysql-db03-relay-bin.000002
Relay_Log_Pos: 361
Relay_Master_Log_File: mysql-bin.000006
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
#在db01上查看vip信息
[root@mysql-db01 ~]# ip a |grep eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
inet 10.0.0.51/24 brd 10.0.0.255 scope global eth0
#在db02上查看vip信息
[root@mysql-db02 ~]# ip a |grep eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
inet 10.0.0.52/24 brd 10.0.0.255 scope global eth0
inet 10.0.0.55/24 brd 10.0.0.255 scope global secondary eth0:0八.配置binlog-server
修改mha配置文件
[root@mysql-db04 ~]# vim /etc/mha/app1.cnf
[binlog1]
no_master=1
hostname=10.0.0.54
master_binlog_dir=/data/mysql/binlog/备份binlog
#创建备份binlog目录
[root@mysql-db04 ~]# mkdir -p /data/mysql/binlog/
#进入该目录
[root@mysql-db04 ~]# cd /data/mysql/binlog/
#备份binlog
[root@mysql-db04 binlog]# mysqlbinlog -R --host=10.0.0.55 --user=mha --password=123 --raw --stop-never mysql-bin.000001 &
#启动mha
[root@mysql-db04 binlog]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /etc/mha/manager.log 2>&1 &测试binlog备份
#查看binlog目录中的binlog
[root@mysql-db04 binlog]# ll
total 44
-rw-r--r-- 1 root root 285 Mar 8 03:11 mysql-bin.000001
#登录主库
[root@mysql-db01 ~]# mysql -uroot -p123
#刷新binlog
mysql> flush logs;
#再次查看binlog目录
[root@mysql-db04 binlog]# ll
total 48
-rw-r--r-- 1 root root 285 Mar 8 03:11 mysql-bin.000001
-rw-r--r-- 1 root root 143 Mar 8 04:00 mysql-bin.000002九.MySQL中间件Atlas
Atlas简介
Atlas是由 Qihoo 360公司Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。它在MySQL官方推出的MySQL-Proxy 0.8.2版本的基础上,修改了大量bug,添加了很多功能特性。
Atlas主要功能
- 1.读写分离(atlas mycat mysql-proxy)
- 2.从库负载均衡
- 3.IP过滤
- 4.自动分表
- 5.DBA可平滑上下线DB
- 6.自动摘除宕机的DB
Atlas相对于官方MySQL-Proxy的优势
- 1.将主流程中所有Lua代码用C重写,Lua仅用于管理接口
- 2.重写网络模型、线程模型
- 3.实现了真正意义上的连接池
- 4.优化了锁机制,性能提高数十倍
安装Atlas
同学们有福了,安装Atlas真的是炒鸡简单,官方提供的Atlas有两种:
1)Atlas (普通) : Atlas-2.2.1.el6.x86_64.rpm
2)Atlas (分表) : Atlas-sharding_1.0.1-el6.x86_64.rpm
这里我们只需要下载普通的即可。
#下载Atlas
[root@mysql-db04 tools]#
wget httpss://github.com/Qihoo360/Atlas/releases/download/2.2.1/Atlas-2.2.1.el6.x86_64.rpm
#安装
[root@mysql-db04 tools]# rpm -ivh Atlas-2.2.1.el6.x86_64.rpm
Preparing... ########################################### [100%]
1:Atlas ########################################### [100%]编辑配置文件
[root@db04 ~]# cd /usr/local/mysql-proxy/
total 0
drwxr-xr-x 2 root root 75 Nov 21 10:43 bin
drwxr-xr-x 2 root root 22 Nov 21 11:00 conf
drwxr-xr-x 3 root root 331 Nov 21 10:43 lib
drwxr-xr-x 2 root root 58 Nov 21 11:01 log
#进入Atlas工具目录
[root@mysql-db04 ~]# cd bin/
#生成密码
[root@mysql-db04 bin]# ./encrypt 123
#修改Atlas配置文件
[root@mysql-db04 ~]# vim /usr/local/mysql-proxy/conf/test.cnf
#Atlas后端连接的MySQL主库的IP和端口,可设置多项,用逗号分隔
proxy-backend-addresses = 10.0.0.51:3306
#Atlas后端连接的MySQL从库的IP和端口
proxy-read-only-backend-addresses = 10.0.0.52:3306,10.0.0.53:3306,10.0.0.54:3306
#用户名与其对应的加密过的MySQL密码
pwds = root:3yb5jEku5h4=
#SQL日志的开关
sql-log = ON
#Atlas监听的工作接口IP和端口
proxy-address = 0.0.0.0:3307
#默认字符集,设置该项后客户端不再需要执行SET NAMES语句
charset = utf8启动Atlas
[root@mysql-db01 ~]# /usr/local/mysql-proxy/bin/mysql-proxyd test start
OK: MySQL-Proxy of test is startedAtlas管理操作
#用atlas管理用户登录
[root@mysql-db01 ~]# mysql -uuser -ppwd -h127.0.0.1 -P2345
#查看可用命令帮助
mysql> select * from help;
+----------------------------+----------------------------------------------------+
| 命令 | 描述 |
+----------------------------+----------------------------------------------------+
| SELECT * FROM help | 查看help帮助 |
| SELECT * FROM backends | 查看后端的服务器状态 |
| SET OFFLINE $backend_id | 平滑下线数据库:set offline 2; |
| SET ONLINE $backend_id | 平滑上线数据库:set online 2; |
| ADD MASTER $backend | 添加一个主库:add master 10.0.0.55:3306; |
| ADD SLAVE $backend | 添加一个从库:add slave 10.0.0.56:3306; |
| REMOVE BACKEND $backend_id | 删除后端节点:remove backend 1; |
| SELECT * FROM clients | 查看可连接的客户端IP |
| ADD CLIENT $client | 添加一个客户端:add client 10.0.0.51; |
| REMOVE CLIENT $client | 删除一个客户端:REMOVE CLIENT 10.0.0.51; |
| SELECT * FROM pwds | 查看后端数据库的用户名和密码 |
| ADD PWD $pwd | 添加用户(自动加密):add pwd root:123; |
| ADD ENPWD $pwd | 添加用户(需要加密后的密码):add enpwd ljk:3yb5jEku5h4= |
| REMOVE PWD $pwd | 删除用户:remove pwd ljk; |
| SAVE CONFIG | 保存到配置文件 |
| SELECT VERSION | 查看版本信息 |
+----------------------------+---------------------------------------------------+
#查看后端代理的库
mysql> SELECT * FROM backends;
+-------------+----------------+-------+------+
| backend_ndx | address | state | type |
+-------------+----------------+-------+------+
| 1 | 10.0.0.51:3306 | up | rw |
| 2 | 10.0.0.52:3306 | up | ro |
| 3 | 10.0.0.53:3306 | up | ro |
| 4 | 10.0.0.54:3306 | up | ro |
+-------------+----------------+-------+------+
mysql> set offline 2;
+-------------+----------------+---------+------+
| backend_ndx | address | state | type |
+-------------+----------------+---------+------+
| 2 | 10.0.0.51:3306 | offline | ro |
+-------------+----------------+---------+------+
mysql> set online 2;
+-------------+----------------+---------+------+
| backend_ndx | address | state | type |
+-------------+----------------+---------+------+
| 2 | 10.0.0.51:3306 | unknown | ro |
+-------------+----------------+---------+------+
#平滑摘除mysql
mysql> REMOVE BACKEND 2;
Empty set (0.00 sec)
#检查是否摘除成功
mysql> SELECT * FROM backends;
+-------------+----------------+-------+------+
| backend_ndx | address | state | type |
+-------------+----------------+-------+------+
| 1 | 10.0.0.51:3306 | up | rw |
| 2 | 10.0.0.53:3306 | up | ro |
| 3 | 10.0.0.54:3306 | up | ro |
+-------------+----------------+-------+------+
#保存到配置文件中
mysql> SAVE CONFIG;
Empty set (0.06 sec)以上是关于十 MHA高可用及读写分离的主要内容,如果未能解决你的问题,请参考以下文章