spark框架体系及spark和MR的区别
Posted yumengfei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark框架体系及spark和MR的区别相关的知识,希望对你有一定的参考价值。
2019-12-11
Spark的框架体系
三个核心组件:SparkCore SparkSQL SparkStreaming
Spark有三种部署模式:Stanalone Yarn Messos
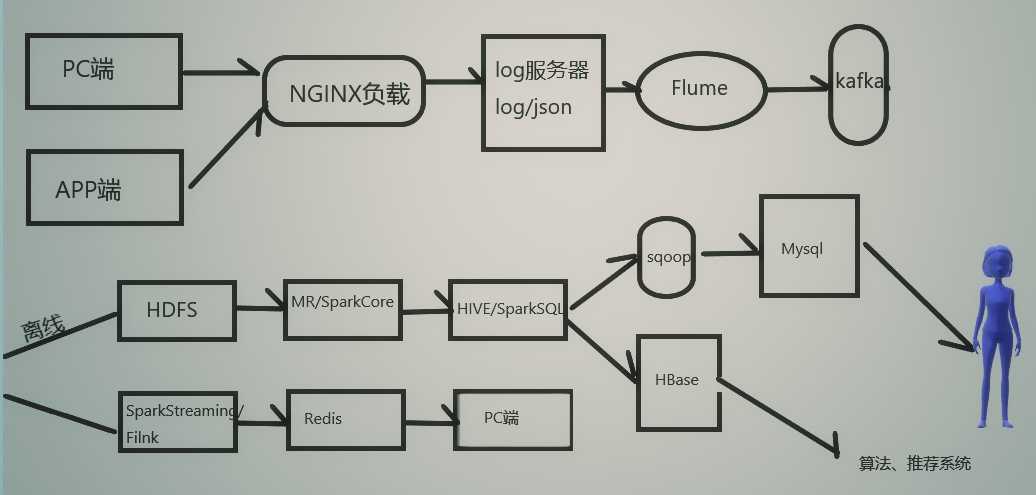
Spark和MapReduce之间区别 *****
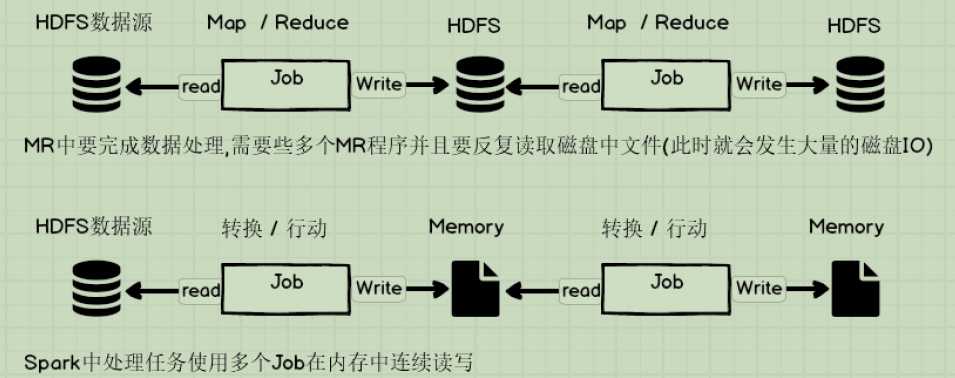
1.Spark把运算中数据放到内存中,迭代计算效率会更高;MR的中间结果需要落地磁盘,所以大量的磁盘IO操作,会影响性能
2.Spark容错性高,它通过弹性分布数据集RDD来实现高容错,RDD是一组分布式存在节点内存中只读性的数据,这些集合是弹性,某一部分数据丢失或出错,可以通过整个数据集的计算流程的血缘来实现重建;MR的容错需要重新计算,成本高。
3.Spark更加通用,Spark提供了transformation和action这两大类多功能API,另外还有流式处理SparkStreaming模块,机器学习、图计算;MR只提供Map和Reduce方法,没有其他模块,MR其实是有机器学习的基本上没有人使用。
4.Spark框架的生态更加丰富,首先由RDD、血缘Lineage,执行时有有向无环图DAG,Stage划分等等,很多时候Spark作业需要在不同场景上运行,此时可以根据不同场景进行调优;MR计算框架相对简单,对性能也相对较弱,单运行稳定,适合长时间在后台运行。
以上是关于spark框架体系及spark和MR的区别的主要内容,如果未能解决你的问题,请参考以下文章