自考数据结构中的线性表,期末不挂科指南,第2篇
Posted happymeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自考数据结构中的线性表,期末不挂科指南,第2篇相关的知识,希望对你有一定的参考价值。
线性表
这篇博客写的是线性表相关的内容,包括如下部分,先看下有木有期待
- 啥是线性表
- 线性表的顺序存储
- 线性表的基本运算在顺序表上的实现
- 线性表的链式存储
- 线性表的基本运算在单链表上的实现
- 循环链表与双向循环链表
Over,内容还蛮多的!~  ̄□ ̄||,头大了...
首先明确一个非常重要的点
线性表是一个线性结构,注意上篇博客提过线性结构是数据的逻辑结构中的一种
基本概念
线性表是由n(n≥0)个数据元素组成的有穷序列
大白话:在内存上一个个排着,找到一个,剩下的挨着找就行
数据元素又称作结点
吐槽:人类在创造术语的路上就是这么带劲,上节课刚说数据元素又称元素,这又来一个结点,得,记住吧
结点个数叫做表长,那么我们用一张完整的图来说明一下
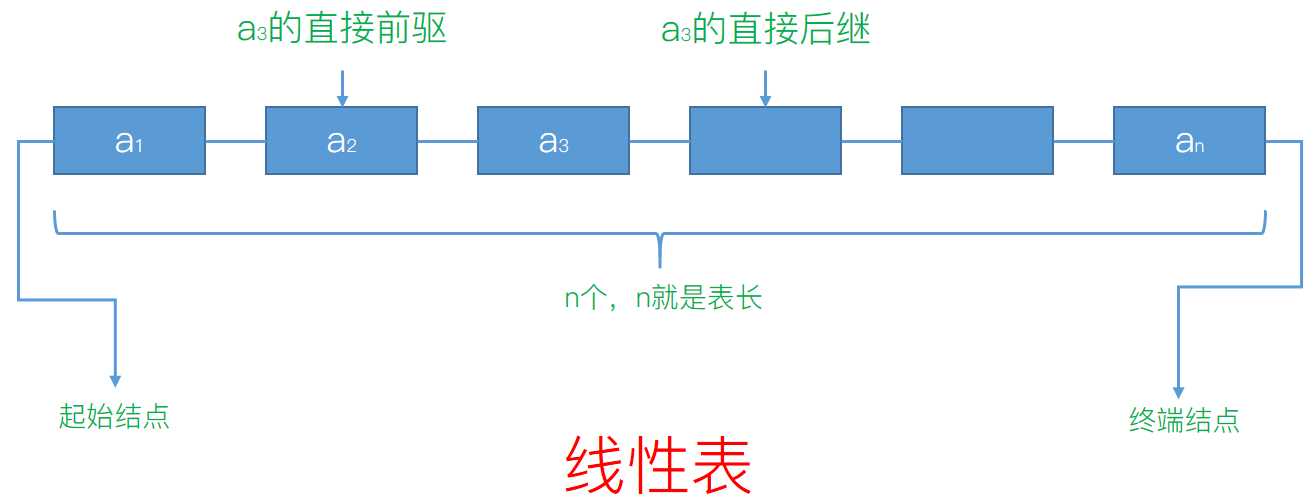
线性表的基本运算,需要了解一下
- 初始化 Initiate(L)
- 求表长 Length(L)
- 读表元素 Get(L,i)
- 定位 Locate(L,i)
- 插入Insert(L,x,i)
- 删除Delete(L,i)
线性表的顺序存储
用顺序存储实现的线性表称为顺序表。一般使用数组来表示顺序表
接下就是刺激的时刻了,比较难的部分来了,因为要用C来实现线性表的基本运算
首先假定线性表的数据元素的类型为DataType ,这个DataType 可以是自定义的,也可以是默认的int,char等类型
const int Maxsize = 100 ; // 预先定义一个足够大的常数
typedef struct{
DataType data[Maxsize]; // 存放数据的数组
int length ; // 顺序表的实际长度
} SeqList; // 顺序表类型名为SeqList
SeqList L ; // 定义一个L为顺序表
实现插入操作,函数名字为InsertSeqList(SeqList L,DataType x,int i) 表示在顺序表第i(1≤i≤n+1)个元素之前,插入一个新元素。使得线性表长度加1。
上面是逻辑上的C语言实现,接下来咱们先引用一个图,说明一下如何用C语言在内存上开辟一块空间,并且向里面存数据
#include <stdio.h>
#include <stdlib.h>
const int Maxsize = 10;
typedef struct SeqList{
int *data; //一个int指针,后面用来初始化数组用
int length;
} seq;
// 顺序表的初始化函数
seq init(){
seq s;
s.data = (int*)malloc(Maxsize*sizeof(int)); // 构造一个空的顺序表,动态申请存储空间
if(!s.data) // 如果申请失败,退出程序
{
printf("初始化失败");
exit(0);
}
s.length = 0; // 空表的长度初始化为0
return s;
}
上述代码,相当于在内存上做了图示的操作
开辟空间之后,向每个小格子里面添加数字
void display(seq s){
for(int i=0;i<s.length;i++){
printf("%d",s.data[i]);
}
printf("
");
}
int main()
{
seq s = init();
//添加一个元素进入
for(int i=1;i<=5;i++){
s.data[i-1] = i;
s.length++;
}
printf("初始化之后,表的数据为:
");
display(s);
return 0;
}可以看动画理解
添加元素完成之后,就是删除元素了
删除的基本步骤
- 结点a~i+1~,....a~n~依次向左移动一个元素位置
- 表长度减1
看一下代码吧
seq delete_seq(seq s,int i){
if(i<1||i>s.length){
printf("位置错误");
exit(0);
}
// 第i个元素下标修改为i-1
for(int j=i;j<s.length;j++){
s.data[j-1] = s.data[j];
}
s.length--;
return s;
}
接下来实现定位的算法,说白了,就是判断一个值(x)的位置(i)
C语言的代码如下
// 注意,这个地方需要返回的为int了,也就是位置
int locate(seq s,int x){
int i =0;
while((i<s.length)&&(s.data[i]!=x)){
i++;
}
if(i<s.length) return i+1;
else return -1;
}
线性表的顺序存储的时间复杂度
| 运算 | 插入 | 删除 | 定位 | 求表长 | 读取元素 |
|---|---|---|---|---|---|
| 时间复杂度 | O(n) | O(n) | O(n) | O(1) | O(1) |
具体是怎么来的,需要你自己看看算法的实现喽,通过上述表格知道
顺序表的插入、删除算法在时间性能方面不是很理想,接下来我们就采用线性表的链接存储来看一下,是否存在优化。
线性表的链接存储
链式存储结构,上来需要记住有三种常见的 单链表、循环链表、双向循环链表
首先明确,单链表中每个结点由两部分组成

- data表示==数据域==
- next表示==指针域==或==链域==
一些简单的结点概念
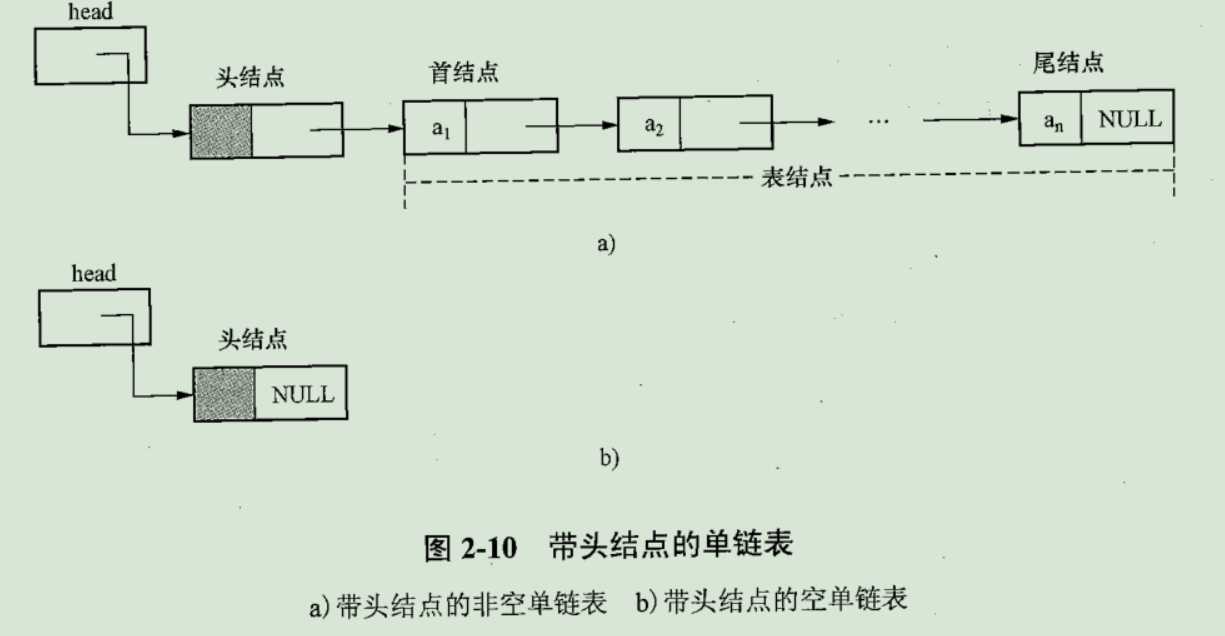
线性表在单链表上实现基本运算
接下来重头戏来了,我们要用代码实现一个简单的单链表
空的单链表由一个头指针和一个头结点组成
初始化
初始化之前,我们需要先用C语言定义一个新的结构体
//链表中的每个结点的实现
//包含数据域与指针域
typedef struct node{
int data;// 数据域,为了计算方便,类型设置为数字
struct node *next; // 指针域,指向后继元素
} Node,*LinkList;结构体定义好了之后,就可以开始初始化操作了
头结点初始化其实就是在内存上开辟一块空间,然后将指针域指向NULL
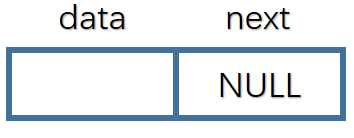
请看代码,注意返回的是一个指针类型,说白了就是头结点的地址
// 初始化
LinkList init(){
Node *L; // 定义一个头结点
L =(LinkList)malloc(sizeof(Node)); //头结点申请地址
if(L == NULL){
printf("初始化失败!
");
exit(0);
}
L->next =NULL;
return L;
}初始化成功,开始插入元素
插入元素,有头插入、尾插、任意插
先说一下头插,当头结点初始化完毕之后,第一个元素插入进来就比较简单了,看动图

这是插入一个元素,在用头插法插入第二个元素呢?
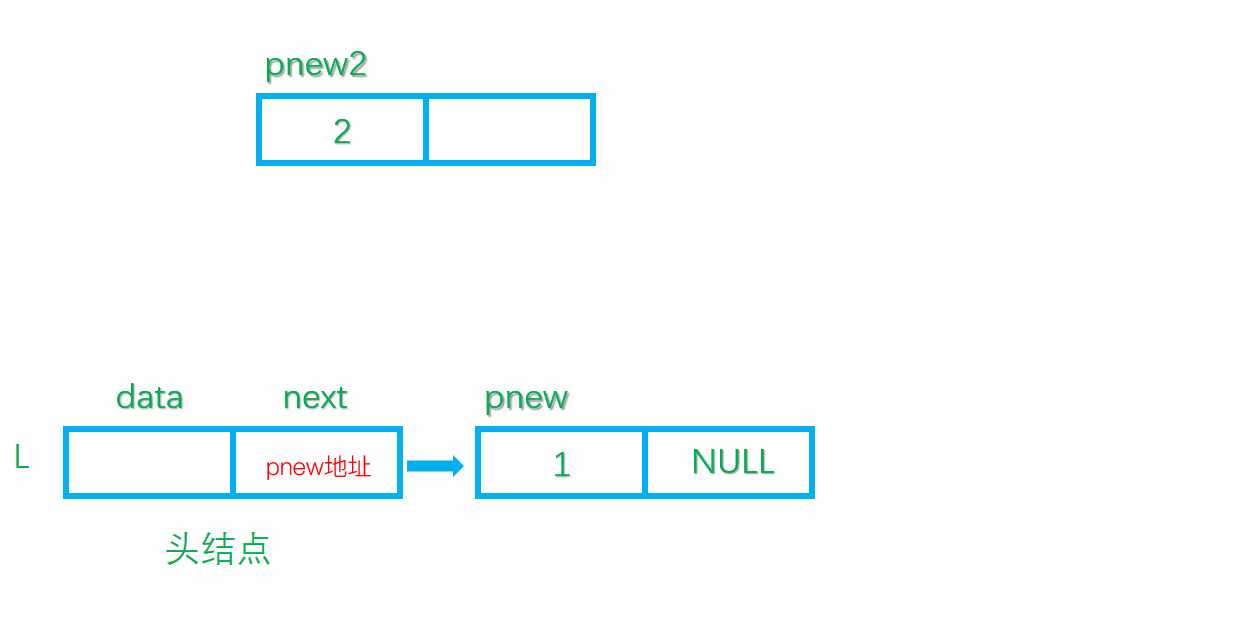
新生成的pnew2首先将自己的指针域指向头结点的指针域pnew2->next = L.next,然后L.next = pnew2 即可
上述的逻辑写成代码如下
// 头插入法
void insert_head(Node *L){
int i,n,num; // n表示元素的个数
Node *pnew;
printf("请输入要插入的元素个数:n = ");
scanf("%d",&n);
for(i=0;i<n;i++){
printf("请输入第%d个元素: ",i+1);
scanf("%d",&num);
pnew = (LinkList)malloc(sizeof(Node));
pnew->data = num; // 将数字存储到数据域
pnew->next = L->next; // 指针域指向L(头结点)的指针域
L->next = pnew; // 头结点指针域指向新结点地址
}
}
接下来看一下尾插法,其实理解起来也不难,说白了就是在链表后面追加元素即可

代码如下,这个地方看一下里面有一个p=L请问直接使用L可以吗?为什么不直接用,搞清楚了,你也就明白了
// 尾插法
void insert_tail(Node *L){
int i,n,num;
Node *p,*pnew;
p = L;
printf("要输入元素的个数:n = ");
scanf("%d",&n);
for(i=0;i<n;i++){
printf("请输入第%d个元素:",i+1);
scanf("%d",&num);
pnew = (LinkList)malloc(sizeof(Node));
if(pnew == NULL){
printf("初始化失败");
exit(0);
}
pnew->data = num;
p->next = pnew;
p = pnew;
}
p->next = NULL;
}剩下的算法实现就比较简单了,例如求表长,通过循环的方式,计算一下即可
//求表长
int get_length(LinkList L){
LinkList p;
int length = 0;
p = L->next; // p 指向第一个结点
while(p){
printf("单链表的数据为%d
",p->data);
length++;
p = p->next;
}
return length;
}读表中的元素
// 读表中的元素
LinkList get_element(LinkList L,int i){
// 在单链表L中查找第i个结点,若找到,则返回指向该结点的指针,否则返回NULL
Node *p;
p = L->next;
int position = 1;
while((position<i)&&(p!=NULL)){ // 当未到第i结点且未到尾结点时继续后移
p = p->next;
position++;
}
if(i==position) return p; //找到第i个结点
else return NULL; // 查找失败
}读取表的元素,还可以按照值去找,返回位置,尝试一下吧,写起来都是比较容易的
int get_element_by_data(LinkList L,int x){
Node *p;
p = L->next;
int i = 0;
while(p!=NULL && p->data == x){
p = p->next;
i++;
}
if (p!=NULL) return i+1;
else return 0;
}
写个复杂点的,在任意位置插入一个元素,这个还是好玩一些的
/在任意位置插入元素,x为要插入的内容,i为插入的位置
void insert(LinkList L,int x,int i){
Node *p,*q; //p表示要插入的元素,q表示要被插入的元素
if(i==1) q = L; //如果i==1,那么p=L进行初始化操作
else q = get_element(L,i-1); // 找到第i-1个元素
if(q==NULL){
printf("找不到位置");
exit(0);
}
else{
p =(LinkList)malloc(sizeof(Node));
p->data = x;
p->next = q->next; // 新生成的p指向q的下一个结点
q->next = p;//q的指针域指向新生成的p
}
}
简单说明一下吧
大白话为 要在第i个位置插入一个元素x,那么需要找到i-1位置的元素,这个元素叫做 q
让新元素p(数据域为x,指针域为空)的指针域指向第i 元素,也就是q原先的指针域,==防止丢失掉==
然后在叫q的指针域指向p的地址即可,如果还不明白,看图
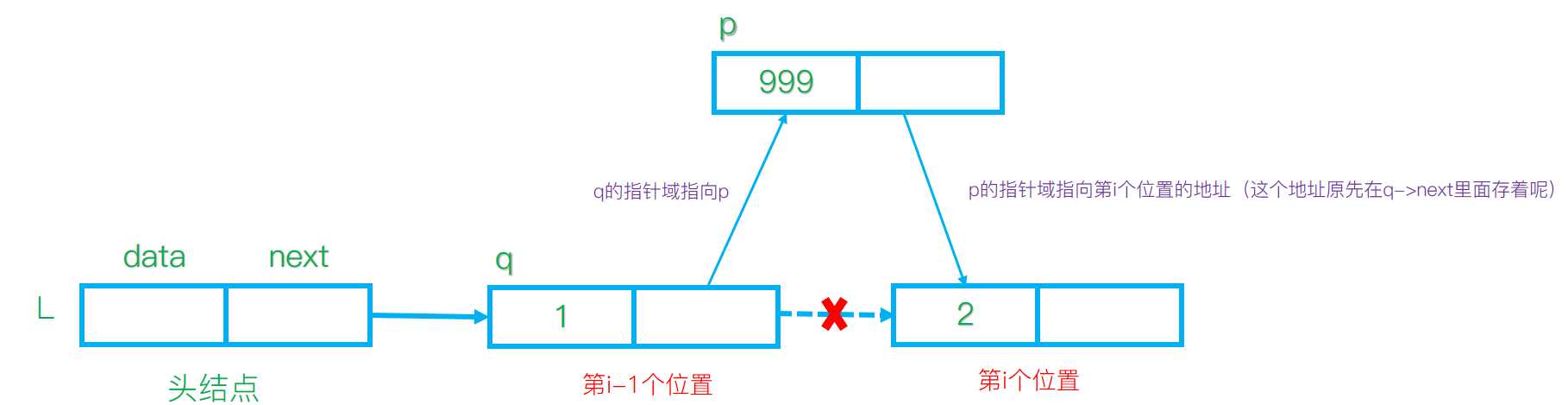
对于删除任意位置的节点,这个就要留给你自己了
如果将a~i~移除链表,需要找到直接前驱,让直接前驱的指针域指向a~i+1~的地址就可以了
记得,通过free(p)释放结点
删除全部结点也需要自己完成一下,尽量把代码写完哦~~~
单链表的时间复杂度
- insert(LinkList L,int x,int i) 时间复杂度为O(n^2^)
- 头插法和尾插法时间复杂度为O(n)
循环链表
环状链表只需要将表中最后一个结点的指针指向头结点,链表就形成了一个环
如图

循环链表如何想研究一下可以去实现约瑟夫环,由于本教材中不是重点,所以选修即可
双向循环链表
双向循环链表就是在单链表中的每个结点在增加一个指向直接前驱的指针域prior ,这样每个结点就有两个指针了

注意点
- 双向循环链表是一种对称结构,即可以直接访问前驱结点又可以直接访问后继结点,所以找前驱和后继结点的时间复杂度都是O(1),也可以得到结论双向循环链表适合应用在需要经常查找结点的前驱和后继场合
- p = p->prior->next = p->next->prior
教材中重点给出了删除和插入的两个逻辑,我们看一下
// p表示的是待删除的结点
p->prior->next = p->next;
p->next->prior = p->prior;
free(p)图示如下
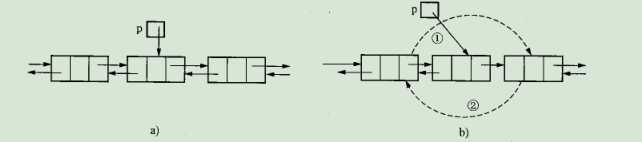
大白话
先让p等于要删除的结点,然后把p删除前,需要将p的前驱和后继结点连接起来,刚才的代码干的就是这个事情!
插入逻辑
在p所指的结点后面插入一个新结点*t,需要修改四个指针:
t->prior = p;
p->next = t; // 这两个步骤将t和p连接起来了
t->next = p->next;
p->next->prior = t; //这两个步骤将t和p后继结点连接起来了
期末考试
这章是期末考试或者自考的一个比较重要的考试章节,一般会出现算法设计题,难度系数挺高的
建议,在能力范围内用C语言实现顺序表的基本运算,实现单链表的基本运算
懵了吧,嘿嘿~,多看几遍,多看几遍,看图,看图,写代码,运行,运行
欢迎关注,梦想橡皮擦公众号哦~

以上是关于自考数据结构中的线性表,期末不挂科指南,第2篇的主要内容,如果未能解决你的问题,请参考以下文章