定位元素split截取
Posted test-hui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了定位元素split截取相关的知识,希望对你有一定的参考价值。
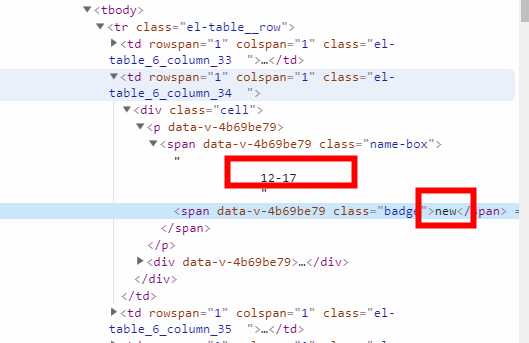
这边直接获取改元素的信息的话会把new也带上去所以我们截取
for i in range(1, rowCount):
a = obtener_elemeentos(‘project‘, "指定的项目", 1)
b = obtener_elemeentos(‘project‘, "指定的项目", 2)
tables = login.browser.find_element(a, b % i).text
#[0]表示只取截取后的前段
table = tables.split(‘new‘)[0]
print(table)
还可以用来复用
比如我这个元素需要统计该元素
if isElementExist(a,b.split("//tbody/tr[%s]//p")[0]):
rowCount = len(login.browser.find_elements(a, b.split("[%s]//p")[0]))
if rowCount == 1:
rowCount=rowCount+1
for i in range(1, rowCount):
a = obtener_elemeentos(‘project‘, "指定的招标项目", 1)
b = obtener_elemeentos(‘project‘, "指定的招标项目", 2)
te=login.browser.find_element(a,b%i).text
if te == name:
login.browser.find_element(element_type, elements%i).click()
break
else:以上是关于定位元素split截取的主要内容,如果未能解决你的问题,请参考以下文章
Selenium Xpath元素无法定位 NoSuchElementException: Message: no such element: Unable to locate element(代码片段