大数据应用测试经验总结
Posted pengpp
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据应用测试经验总结相关的知识,希望对你有一定的参考价值。
大数据应用测试过程与传统的web系统有较大的不同,大数据应用测试通常会分为web侧和ETL侧测试,web侧基本就是功能测试,而ETL(Extracting-Transfroming-Loading)测试主要指从任何外部系统提取、转换、载入数据到目标地。从底层数据采集、数据处理、到上层应用展现。
一、从技术架构设计上,分为以下几块:
- 数据采集:采集使用java和python程序从文件服务器下载文件,并把文件写入kafka、Hbase和Hive、mysql中;
- 计算引擎:使用Hive on Tez计算引擎实现ETL跑批任务;使用spark streaming实现实时计算;使用Phoenix做前台交互式查询。
- 数据存储:使用Kafka、Hive、Hbase、MySQL满足各层次存储技术需求。
- 任务调度:使用Quartz实现作业调度及管理。
- 监控接口:使用Kafka、文件接口对接统一监控平台。
- 数据可视化:使用JQuery、Echarts、Easy UI等技术实现图表、表格展示;使用Apache POI实现excel、CSV的导入导出;使用Log4J记录日志;使用Spring框架实现页面、服务、数据的集成管理;使用DBCP实现数据库连接池。
- 数据模型层次说明
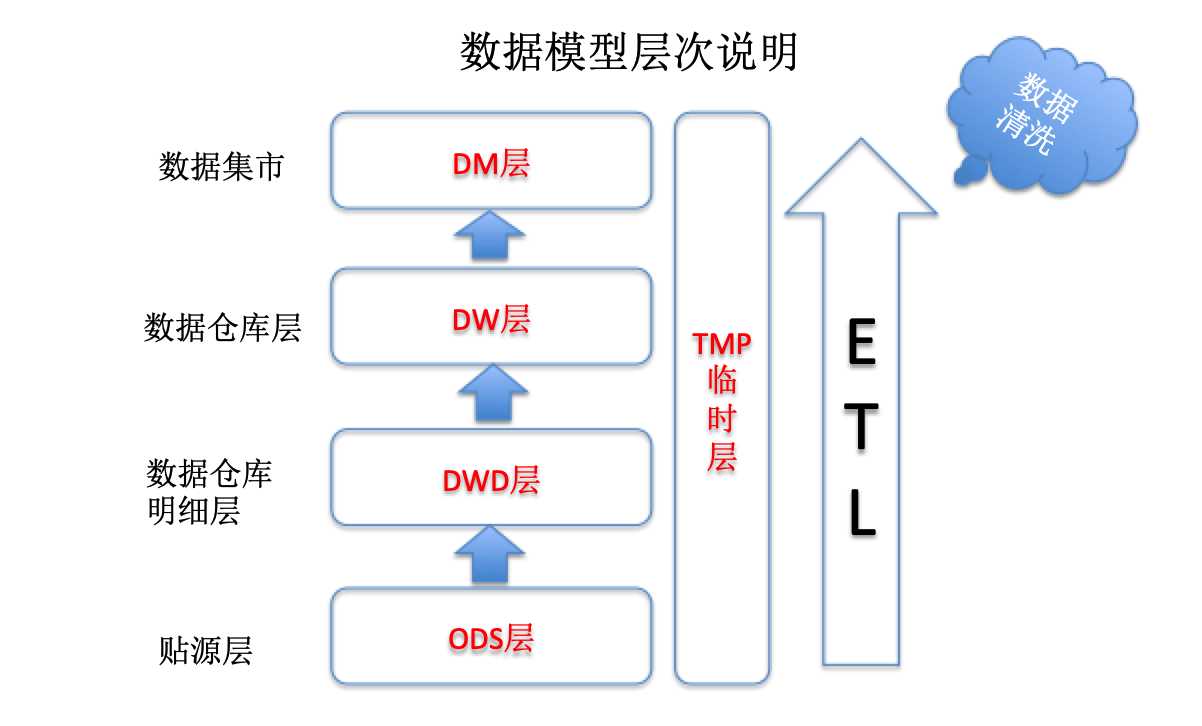
ODS:贴源层,存储原始数据,数据采集直接写入;
DWD:数据仓库明细层,存储从源数据抽去过来的明细数据;
DW:数据仓库层,保存经过数据降维汇聚的计算后生成的汇总数据;
DM:数据集市层,满足特定功能而建立的各种数据集市。
- 数据处理过程说明
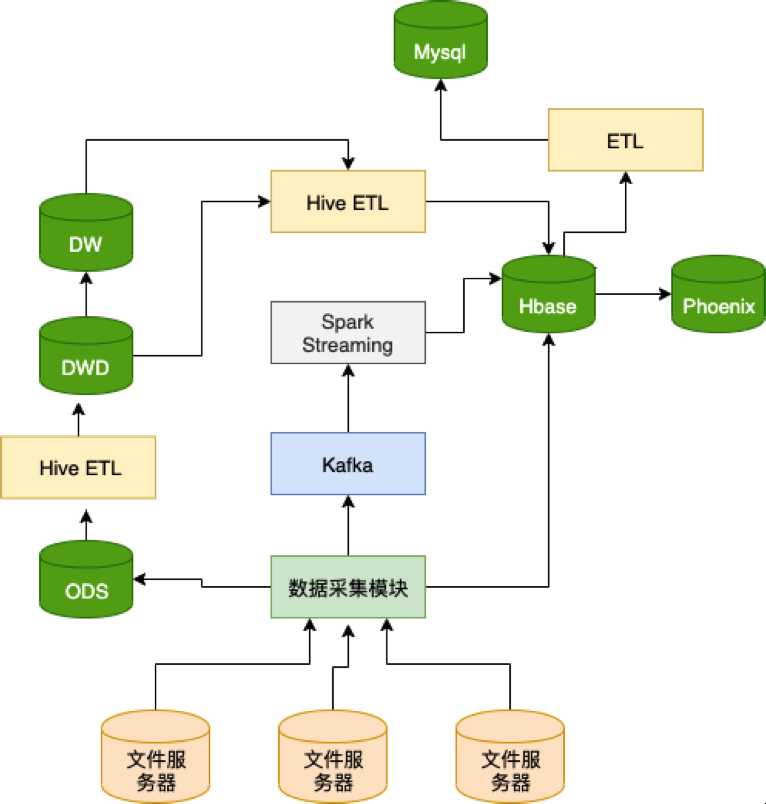
- 数据采集模块从采集机采集相关业务数据;
- 数据采集模块定期把原始数据导入Hive库中的ODS层相关表中;实时数据及时写入kafka提供给spark streaming处理;公参数据写入mysql中。
- ETL模块从ODS层相关表中抽取数据到DWD层;
- ETL模块根据轻度汇总要求进行数据轻度汇总操作,并把汇总后的数据放到DW层中;
- 一些功能所需数据无法从轻度汇总表计算出来,需要从DWD中原始表进行汇总;
- ETL模块从DW层获取轻度汇总数据,根据各业务功能要求进一步汇总数据,形成DM层数据;
- 即席查询数据从Hive关联到Hbase中;
- Phoenix关联到HBase中,供页面查询使用;
- 部分ETL模块数据把Hive中汇总后数据导入MySQL中,供模型建模使用;
二、Hadoop运行:
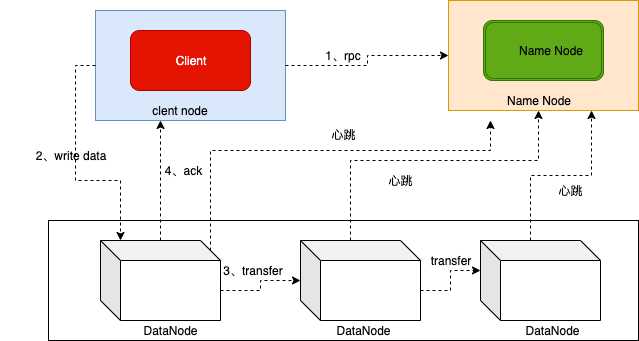
mapreduce机制:
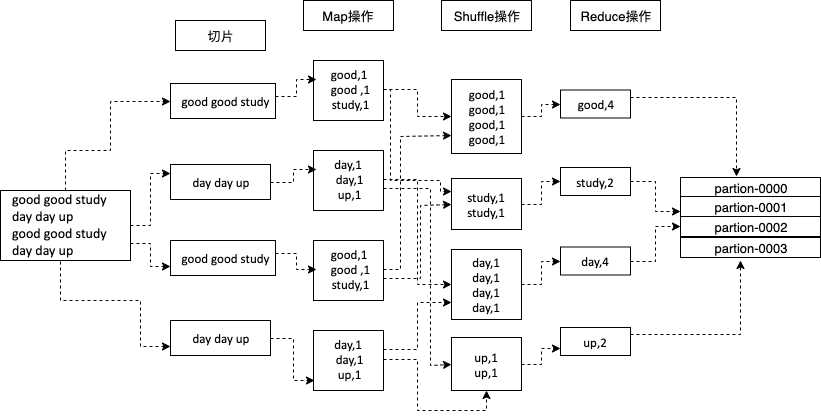
常用命令:
| 功能 | 命令 |
|---|---|
| 查看目录 |
|
| 上传文件 |
|
| 创建目录 | hadoop fs -mkdir ${dirname} |
| 获取文件 |
|
| 删除多个文件或目录 |
|
| 复制文件 |
|
| 移动文件 |
|
三、hive和hbase比较:
|
Hive(非数据库) |
Hbase(数据库) |
|
|
适用场景 |
用于对一段时间内的数据进行分析查询,离线批处理 |
大数据的实时查询 |
|
特点 |
1、一种类SQL的引擎,运行MapReduce任务; 2、查询一般是全量查询,时间较长,可通过分区来优化; 3、基于行查询,定义时每行有固定列数据,每列数据固定大小; 4、操作:不支持更新操作 |
1、一种在Hadoop之上的NoSQL型Key/Value数据库; 2、查询是通过特定语言编写,可通过Phonenix实现类SQL功能; 3、基于列查询,可定义各种不同的列,每列数据大小不固定; |
四、hive常用操作
| hive | 基础操作 | 说明 |
|---|---|---|
| 查看数据库 | show databases | |
| 使用数据库 | use DbName | |
| 删除数据库 | drop database if exists DbName CASCADE | 如果数据库不为空,删除会报错,加上cascade可忽略 |
| 查看表 | show tables in DbName ; show tables like ‘h*’ | |
| 创建表 |
内部表:CREATE TABLE page_view if not exists(viewTime INT, userid BIGINT, |
外部表: CREATE EXTERNAL TABLE page_view(viewTime INT, userid BIGINT, |
| 加载表 |
LOAD DATA LOCAL INPATH `/tmp/pv_2013-06-08_us.txt` INTO TABLE c02 PARTITION(date=‘2013-06-08‘, country=‘US‘) |
注:
存储格式有四种种:textfile、sequencefile(二进制文件)、RCFfile(行列存储相结合)、ORC
只有TEXTFILE表能直接加载数据,必须本地load数据和external外部表直接加载运路径数据,都只能用TEXTFILE表。更深一步,hive默认支持的压缩文件(hadoop默认支持的压缩格式)也只能用TEXTFILE表直接读取。其他格式不行。可以通过TEXTFILE表加载后insert到其他表中。
内外部表区别:
创建内部表时,会将数据移动到数据仓库指向的路径,存储在hive.metastore.warehouse.dir路径属性下,默认情况下位于/user/hive/warehouse/databasename.db/tablename/ 文件夹路径中,删除内部表会将元数据和数据同步删除。创建外部表时,仅记录数据所在的路径(location),不对数据的位置做任何变化,外部表文件可以由Hive外部的进程访问和管理。外部表可以访问存储在Azure Storage Volumes(ASV)或远程HDFS位置等源中的数据,删除外部表时,只删除元数据,不删除文件中数据。
五、HBase Shell的一些基本操作命令,列出了几个常用的HBase Shell命令,如下:
| 查看存在哪些表 | list |
| 创建表 | create ‘表名称‘, ‘列名称1‘,‘列名称2‘,‘列名称N‘ |
| 添加记录 | put ‘表名称‘, ‘行名称‘, ‘列名称:‘, ‘值‘ |
| 查看记录 | get ‘表名称‘, ‘行名称‘ |
| 查看表中的记录总数 | count ‘表名称‘ |
| 删除记录 | delete ‘表名‘ ,‘行名称‘ , ‘列名称‘ |
| 删除一张表 | 先要屏蔽该表,才能对该表进行删除,第一步 disable ‘表名称‘ 第二步 drop ‘表名称‘ |
| 查看所有记录 | scan "表名称" |
| 查看某个表某个列中所有数据 | scan "表名称" , [‘列名称:‘] |
| 更新记录 | 就是重写一遍进行覆 |
以上是关于大数据应用测试经验总结的主要内容,如果未能解决你的问题,请参考以下文章