算法数据结构02 /常用数据结构
Posted liubing8
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法数据结构02 /常用数据结构相关的知识,希望对你有一定的参考价值。
2算法数据结构02 /常用数据结构
1. 栈
特性:先进后出的数据结构,有栈顶和栈尾
应用场景:每个 web 浏览器都有一个返回按钮。浏览网页时,这些网页被放置在一个栈中(实际是网页的网址)。现在查看的网页在顶部,第一个查看的网页在底部。如果按‘返回’按钮,将按相反的顺序浏览刚才的页面。
栈的方法:
Stack():创建一个空的新栈。 它不需要参数,并返回一个空栈。 push(item):将一个新项添加到栈的顶部。它需要 item 做参数并不返回任何内容。 pop():从栈中删除顶部项。它不需要参数并返回 item 。栈被修改。 peek():从栈返回顶部项,但不会删除它。不需要参数。 不修改栈。 isEmpty():测试栈是否为空。不需要参数,并返回布尔值。 size():返回栈中的 item 数量。不需要参数,并返回一个整数。列表实现一个栈
class Stack(): def __init__(self): self.items = [] def push(self,item): """ 栈顶添加 """ self.items.append(item) def pop(self): """ 栈顶删除 """ return self.items.pop() def peek(self): """ 查看栈顶元素 """ return self.items[-1] def isEmpty(self): """ 查看栈是否为空 """ return self.items == [] def size(self): """ 查看栈中元素个数 """ return len(self.items)
2. 队列
特性:先进先出的数据结构
应用场景:计算机实验室有 30 台计算机与一台打印机联网。当学生想要打印时,他们的打印任务与正在等待的所有其他打印任务“一致”。第一个进入的任务是先完成。如果你是最后一个,你必须等待你前面的所有其他任务打印
队列的方法:
Queue():创建一个空的新队列。 它不需要参数,并返回一个空队列。 enqueue(item):将新项添加到队尾。 它需要 item 作为参数,并不返回任何内容。 dequeue():从队首移除项。它不需要参数并返回 item。 队列被修改。 isEmpty():查看队列是否为空。它不需要参数,并返回布尔值。 size():返回队列中的项数。它不需要参数,并返回一个整数。列表实现一个队列
class Queue(): def __init__(self): self.items = [] def enqueue(self,item): """ 队列尾部添加元素 """ self.items.insert(0,item) def dequeue(self): """ 删除队列头部的元素 """ return self.items.pop() def isEmpty(self): """ 查看队列是否为空 """ return self.items == [] def size(self): """ 查看队列中元素的个数 """ return len(self.items)队列应用示例:
烫手的山芋 1.烫手山芋游戏介绍: 6个孩子围城一个圈,排列顺序孩子们自己指定。第一个孩子手里有一个烫手的山芋,需要在计时器计时1秒后将山芋传递给下一个孩子,依次类推。规则是,在计时器每计时7秒时,手里有山芋的孩子退出游戏。该游戏直到剩下一个孩子时结束,最后剩下的孩子获胜。请使用队列实现该游戏策略,排在第几个位置最终会获胜。 2.提取有价值的信息: 计时1s的时候山芋在第一个孩子手里面 山芋会被1s传递一次 7秒钟山芋被传递了6次 准则:保证第一个(队头)孩子手里面永远要有山芋,山芋不动、人动kids = ['A','B','C','D','E','F'] q = Queue() for kid in kids: q.enqueue(kid) while q.size() > 1: # 当队列中孩子的个数大于1游戏继续否则游戏结束 for i in range(1,7): # 山芋传递的次数 kid = q.dequeue() # 对头元素出队列再入队列 q.enqueue(kid) q.dequeue() # 一轮游戏结束后,将对头孩子淘汰(对头孩子手里永远有山芋) print(q.dequeue())
3. 双端队列
特性:同队列相比,有两个头部和尾部。可以在双端进行数据的插入和删除,提供了单数据结构中栈和队列的特性
双端队列的方法:
Deque():创建一个空的新 deque。它不需要参数,并返回空的 deque。 addFront(item):将一个新项添加到 deque 的首部。它需要 item 参数 并不返回任何内容。 addRear(item):将一个新项添加到 deque 的尾部。它需要 item 参数并不返回任何内容。 removeFront():从 deque 中删除首项。它不需要参数并返回 item。deque 被修改。 removeRear():从 deque 中删除尾项。它不需要参数并返回 item。deque 被修改。 isEmpty():测试 deque 是否为空。它不需要参数,并返回布尔值。 size():返回 deque 中的项数。它不需要参数,并返回一个整数。列表实现双端队列
class Deque: def __init__(self): self.items = [] def addFront(self,item): """ 双端队列头部添加 """ self.items.insert(0,item) def addRear(self,item): """ 双端队列尾部添加 """ self.items.append(item) def removeFront(self): """ 双端队列头部删除 """ return self.items.pop(0) def removeRear(self): """ 双端队列尾部删除 """ return self.items.pop() def isEmpty(self): """ 查看双端队列是否为空 """ return self.items == [] def size(self): """ 查看双端队列元素的个数 """ return len(self.items)双端队列应用示例:判断一个字符串是否是回文
deque = Deque() def huiwen(s): for i in s: deque.addFront(i) while deque.size() > 1: if deque.removeRear() != deque.removeFront(): print('不是回文') return print('是回文') huiwen('12321')
4. 内存相关
形象化理解内存(内存的大小和地址)
1.开辟好的内存空间会有两个默认的属性:大小,地址 2.大小:衡量该块内存能够存储数据的大小 - bit(位):只可以存放一位二进制的数 - byte(字节):8bit - kb:1024byte - 10Mb:10*1024*1024*8 - 作用:可以衡量该内存存储数据大小的范围 3.地址:16进制的数表示 - 作用:定位内存空间的位置 - 变量/引用:内存空间的地址变量的概念
1.引用==变量,变量就是我们为存储数据单独开辟的内存空间。 2.理解a=10的内存图(指向) 如果一个变量表示的是某一块内存空间的地址,则该变量指向该块内存空间。 如果一个变量指向了某一块内存空间,则该变量就可以代替/表示这块内存中存储的数值不同数据占用内存空间的大小
整数:4字节 浮点型:float:4字节,double:8字节 字符型(char):1字节
5. 顺序表
顺序表的结构可以分为两种形式:单数据类型和多数据类型;python中的列表和元组就属于多数据类型的顺序表
单数据类型顺序表的内存图(内存连续开启),以数组为例:

多数据类型顺序表的内存图(内存非连续开辟),以列表为例:
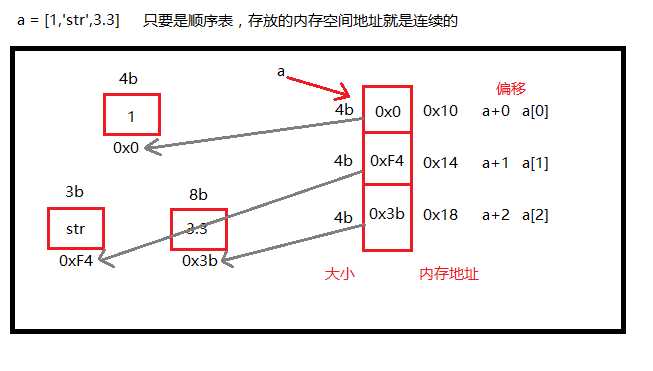
顺序表的弊端
顺序表的结构需要预先知道数据大小来申请连续的存储空间,而在进行扩充时又需要进行数据的搬迁。
6. 链表
链表简述:
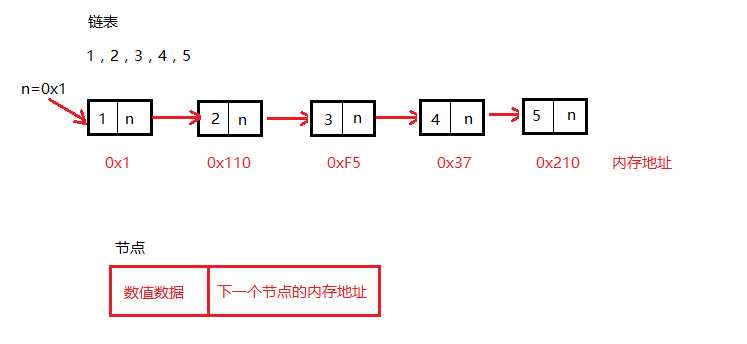
1.链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是不像顺序表一样连续存储数据,而是每一个结点(数据存储单元)里存放下一个结点的信息(即地址)
2.相对于顺序表,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理且进行扩充时不需要进行数据搬迁。
链表的方法:
is_empty():链表是否为空 length():链表长度 travel():遍历整个链表 add(item):链表头部添加元素 append(item):链表尾部添加元素 insert(pos, item):指定位置添加元素 remove(item):删除节点 search(item):查找节点是否存在代码实现
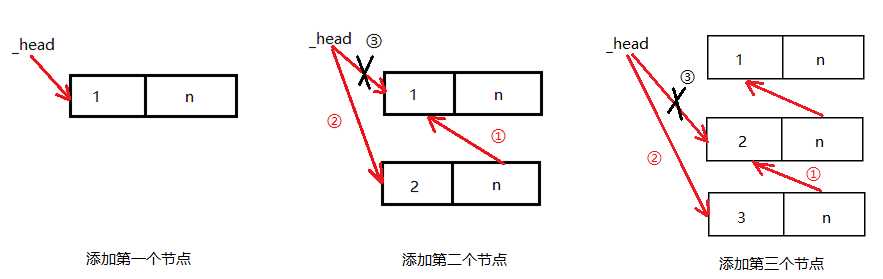
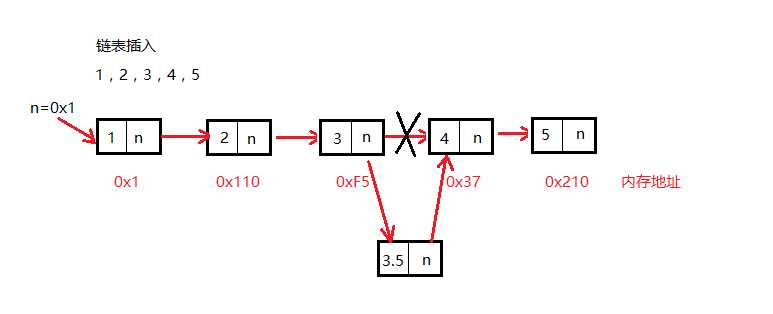
class Node(): """ 初始化一个节点 """ def __init__(self,item): self.item = item # 存储数值数据 self.next = None # 存储下一个节点的地址 class Link(): """ 构建一个空链表 """ def __init__(self): self._head = None # _head要指向第一个节点,如果没有节点则指向None def add(self,item): """ 链表头部添加元素 """ node = Node(item) # 1.创建一个新节点 node.next = self._head # 2.将创建新节点的next指向,指向原来的第一个节点 self._head = node # 3.将链表的_head指向新创建的节点 def travel(self): """ 遍历链表 """ # 在非空的链表中head永远要指向第一个节点的地址,永远不要修改它的指向,否则会造成数据的丢失 cur = self.__head while cur: print(cur.item) cur = cur.next def is_empty(self): """ 判断链表是否为空 """ return self._head == [] def length(self): """ 查看链表的长度 """ count = 0 # 记录节点的个数 cur = self.__head while cur: count += 1 cur = cur.next return count def append(self,item): """ 在链表的尾部添加元素 """ node = Node(item) cur = self._head # 当前结点 pre = None # 指向cur的前一个节点 if self._head = None: # 如果链表为空则需要单独处理 self._head = node return while cur: pre = cur cur = cur.next # 循环结束之后cur指向了None,pre指向了最后一个节点 pre.next = node def search(self,item): """ 在链表中查找元素 """ cur = self._head find = False while cur: if cur.item == item: find = True break else: cur = cur.next return find def insert(self,pos,item): """ 在链表中插入元素 """ node = Node(item) cur = self._head pre = None # 如果插入的位置大于链表的长度,则默认插入到尾部 if pos > self.items.length()-1: self.append(item) return for i in range(pos): pre = cur cur = cur.next pre.next = node node.next = cur def remove(self,item): """ 移除指定的元素 """ cur = self._head pre = None if item == cur.item: self._head = cur.next return while cur: if cur.item != item: pre = cur cur = cur.next else: break pre.next = cur.next链表结构内存图:
链表头部添加(add)内存图:
链表插入(insert)内存图:
7. 二叉树
二叉树概述:
二叉树组成:根节点,叶子节点
2.子树:左右叶子节点都有就是完整子树、只有单个的节点的就是不完整的子树
3.结论:
- 一个子树最少要包含一个根节点
- 一个完整的二叉树是由多个子树构成
- 一个子树的子节点也可以表示另一个子树的根节点
二叉树的遍历
广度遍历:逐层遍历 深度遍历:纵向遍历,前中后表示的是子树种根节点的位置 一定要基于子树去遍历 前序遍历:根左右 中序遍历:左根右 后序遍历:左右根 为什么用深度遍历:要结合排序二叉树一起使用,深度遍历可以帮我们二叉树进行排序。普通二叉树实现:
class Node(): def __init__(self,item): self.item = item self.left = None self.right = None class Tree(): # 构建一棵空树 def __init__(self): self.root = None def add(self,item): """ 插入节点 """ if self.root == None: # 向空树中插入第一个节点 node = Node(item) self.root = node return else: # 向非空的二叉树中插入一个节点 node = Node(item) cur = self.root # 防止根节点指向改变 queue = [cur] while queue: root = queue.pop(0) if root.left != None: queue.append(root.left) else: root.left = node break if root.right != None: queue.append(root.right) else: root.right = node break # 广度遍历 def travel(self): """ 遍历二叉树 """ cur = self.root queue = [cur] if self.root == None: print('') return while queue: root = queue.pop(0) print(root.item) if root.left != None: queue.append(root.left) if root.right != None: queue.append(root.right) # 深度遍历 def forward(self,root): """ 前序遍历 """ if root == None: return print(root.item) self.forward(root.left) self.forward(root.right) def middle(self,root): """ 中序遍历 """ if root == None: return self.middle(root.left) print(root.item) self.middle(root.right) def back(self,root): """ 后序遍历 """ if root == None: return self.back(root.left) self.back(root.right) print(root.item)排序二叉树实现:
# 排序二叉树 class SortTree(): def __init__(self): self.root = None def add(self,item): node = Node(item) cur = self.root if self.root == None: self.root = node return while True: # 插入节点的值小于根节点的值,往根节点左侧插 if node.item < cur.item: if cur.left == None: cur.left = node break else: cur = cur.left else: # 插入节点的值大于根节点,往根节点右侧插 if cur.right == None: cur.right = node break else: cur = cur.right def middle(self,root): """ 中序遍历 """ if root == None: return self.middle(root.left) print(root.item) self.middle(root.right)tree = SortTree() alist = [3,8,4,6,7,8] for i in alist: tree.add(i) tree.middle(tree.root)
以上是关于算法数据结构02 /常用数据结构的主要内容,如果未能解决你的问题,请参考以下文章