谈谈对象大小——从字节对齐到对象模型
Posted leijiangtao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谈谈对象大小——从字节对齐到对象模型相关的知识,希望对你有一定的参考价值。
谈谈对象大小——从字节对齐到对象模型 一. 前言 这篇文章主要介绍以下从c的结构体变量到c++的类对象中编译器对内存分配做的事情。总而言之,言而总之,这篇文章就是讲述对于一个变量(对象)它的内存布局是怎么样子的。 为了方便描述,我们按照以下几个层次来讲述: 1.c中struct的字节对齐 2.从struct到class的过渡 3.单继承对对象内存模型的影响 4.虚函数对对象内存布局的影响 5.多继承对对象内存模型的影响 6.虚基类对对象内存布局的影响 二. c中struct的字节对齐 在谈字节对齐之前,我们先思考一下下面这个结构体大小? struct node { }; 没错,就是一个空结构体,按道理来说,如果没有数据应该内存大小为0,然而事实上并不是这样。它有一个隐藏的1B大小,那是呗编译器安插进去的一个char,这使得这个struct对应的对象在内存中有独一无二的地址。 下面就来了解字节对齐: 许多计算机系统对基本数据类型变量的地址做了约束,这样做是为了提高bus(总线)对数据存取的效率。比如,我们如果对一个int类型数据进行读写操作;如果int变量地址不是4的倍数,那么数据就会被分割在多个块中,那么cpu读写该变量就要进行多次访存。所以,字节对齐是操作系统对于性能提高的一种策略。 不同的系统中这些策略都是有区别的,例如: Linux系统: 对于2字节数据类型变量地址必须是2的倍数,其余数据类型变量地址必须是4的倍数。 Windows系统: 对于大小为k字节的数据类型变量必须是k的倍数。 而上述中提到的地址必须是x的倍数,换句话说也就是按照k对齐。我们可以更改对齐规则么?可以!不过一般我们不这么做,除非有特殊需求,比如thunk技术。 先看下面这段代码: struct node { char mem1; //sizeof(char) = 1 int mem2; //sizeof(int) = 4 char mem3; }; struct node a; sizeof(a)的值应该是多少呢? 5? 12! 如果从未了解过字节对齐的朋友可能对这个答案感到很不可思议,因为这比本应该占的内存(5字节)的两倍还多。 但是事实上,按照上述所说的字节对齐规则来说,得到12这个答案其实并不意外。我们先来看来对齐规则: 1.对于基本数据类型变量按照其字节数大小k对齐。 2.对于结构体类型变量按照其成员中最大对齐量对齐。 ———保证结构体第一个变量满足对齐规则 3.对于结构体类型变量其大小要为其成员最大对齐量的整数倍 ———保证结构体数组中每个元素满足对齐规则。 所以按照上述规则,a的内存布局应该是这样的:

首先,mem1逻辑地址为0,满足按照1字节对齐; —–规则2 这时候分配mem2,因为mem2数据类型为int大小为4个字节,所以需要在中间插入3个字节的间隙,所以mem2的逻辑地址为4; —–规则1 这时候分配mem3,当前逻辑地址为8,满足按照1字节对齐,所以直接分配给mem3 —–规则1 此时逻辑地址已经分配了9字节,然而不满足成员最大对齐量(int对齐量为4字节)的整数倍,所以还需要在最后插入3字节间隙。 —–规则3 可能有的朋友还是对规则3的缘由不是很清楚,为什么还需要最后插入3个字节。如果我们申请一个结构体数组 : struct node arr[2]; 假如我们最后不进行3个字节的间隙插入,那么很显然,即使arr[0]元素的每个成员满足对齐规则,然而数组要保证元素地址连续,那么必定导致arr[1]的第一个成员一定不满足对齐规则。 如何修改字节对齐的规则呢?请看下面这段代码: #pragma pack(push,1) //使结构体按1字节方式对齐,将原来的对齐规则压栈 struct node { char mem1; int mem2; }; #pragma pack(pop) //恢复原来的对齐规则 //sizeof(node) = 5 三. 从struct到class的过渡 首先,需要注意的一点是,在c++中,我们可以使用struct替换class,因为本质上这两个关键字除了default access section不一样以外,其他都是都无差别。 所以这里说,从struct到class的过渡的实质,只是在这里,我把struct认为一个数据集合体,没有private data,也没有member function等等,虽然struct可以代替class实现private data、member function、继承等等。 后面所谈到的继承派生等等都只是指class。 四.单继承对对象内存模型的影响 首先先来看下这段代码: //带透明通道颜色信息的顶点结构 class ColorAVertex{ public: int _x,_y,_z; unsigned char _r,_g,_b,_a; //颜色rgba三通道值 }; 嗯,经过第二段和第三段的介绍,我们应该很容易推出 sizeof(ColorAVertex) = 16。 不过,经过分析之后,决定将其分裂成三层结构: class Vertex{ int _x,_y,_z; }; class ColorVertex:public Vertex{ public: unsigned char _r,_g,_b; }; class ColorAVertex:public ColorVertex{ public: unsigned char _a; }; 从设计的角度来看,可能这个结构相对更加合理,但是从实现的角度来说,我们发现一个事情:sizeof(ColorAVertex) = 20 嗯,要对这个问题追根溯源,我们就需要了解单继承对对象模型产生的影响。我们可以观察上述两种情况对应产生的对象模型:
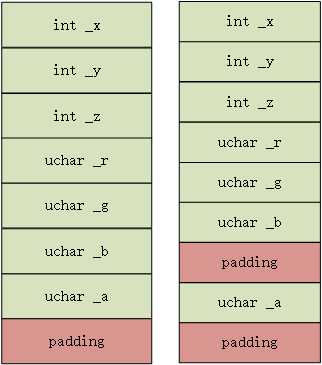
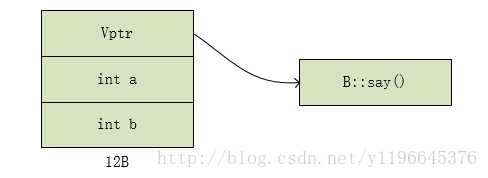
可以看出来,在第二种情况,内存布局中间多了一段间隙。而这段间隙的来源就是ColorVertex类要满足规则3.而在ColorAVertex继承ColorVertex的后,_a并不会接着_b之后,而是需要保持那段间隔。因为继承派生是is a 关系,所以在ColorAVertex的内存布局中不能改变ColorVertex的布局结构。不过在其他某些编译器种,并不是这样实现的。 VC++2015 : sizeof(ColorAVertex) = 20 GUN GCC : sizeof(ColorAVertex) = 16 除此之外,还有一些member类型需要注意:static member 和 member function( 不包括 virtual function ) 。这些类型的成员是不会引起对象内存布局的变化的。这些数据成员并不是存在每个对象的内存模型之中。 我们再来看下面这种情况: struct A { }; struct B:A { }; 在上面我们了解到如果member data为空,那么编译器会安插一个char,那么在这段代码中B的大小是2还是1呢? 事实上,当B继承A之后,因为A已经安插了一个char了,B就不为空了,所以说sizeof(B) = 1。 五.虚函数对对象内存布局的影响 在上一段末尾中提到,member function不影响对象内存布局,但是把virtual function排除开外了。因为virtual function作为c++运行时多态的核心,而为了支持这一特性,在对象内部也添加了相应的一些信息。 例如:下面这段代码: class A { public: int a; virtual void say(){ printf("A::say() "); } }; class B:public A { public: int b; void say(){ printf("B::say() "); } }; int main() { A* p = ....; p->say(); return 0; } 在以上继承体系中,编译阶段并不能知道A* p真正的类型,而编译阶段就需要进行函数绑定,而真正的函数只有在运行阶段才知道。所以,对象内部必须要存储相应的动态类型信息,这样才能实现动态绑定。而这样的信息就是vptr,也就是虚表指针,指向一个虚函数表。而一个类的虚函数表只有一个,也就是一个类的不同对象vptr值是相同的。 所以说,拥有虚函数的对象,会多4个字节用于存放vptr虚表指针,而存放位置由编译器决定,一般来说不是对象首部,就是尾部。不过大多数编译器都是放在对象首部,也就是说&vptr=&obj。 在单继承体系中,如果一个类的父类中已经有vptr了,那么在子类的虚函数只有可能是新添或者重写。而这些操作都是先复制父类的虚表,然后在其上修改。注意:在单继承体系中,对象内存模型中vptr只有一个,也就是后面的操作都是在vptr对应的虚表上覆盖或者新添。
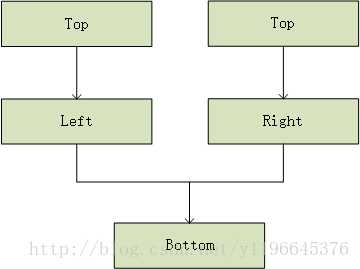
六.多继承对对象内存模型的影响 在多继承体系中,对象的很多东西就会变得十分复杂,这里我们撇开这些复杂的特殊性不谈。只是简单谈谈在对象内存模型中的影响。 首先看下面这段代码: class Top{ public: int _top; }; class Left: public Top{ public: int _left; }; class Right: public Top{ public: int _right; }; class Bottom: public Left,public Right{ public: int _bottom; };
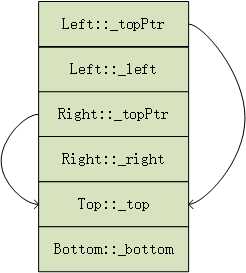
在继承过程中,由于Bottom继承了Left和Right,导致基类Top在Bottom中有两份实体。所以,Bottom的内存布局如下:

当然,有的时候,这样的重复并不是我们所希望的我,所以对于多继承中,这样的重复继承情况,c++提出了虚拟继承这样的概念来解决。 七.虚基类对对象内存布局的影响 嗯,如果要花篇幅去深究虚基类里面的种种细节,可能再写几千字也不为过。不过在这里我只是简单的介绍,如果类的继承体系中出现了虚基类会对内存布局产生的影响。 虚基类的内存布局难点是在于,既要保证多个继承源的情况下,虚基类只能有一个。并且子类的内存布局中不能改变父类的内存布局模式。这里就不探讨解决方案的相关的。直接给出常规编译器的解决方案之一吧(VC++2015)。如果一个类B虚拟继承自类A。相当于类B组合了一个A对象,并且含有一个指针指向A对象。而基于B对象读取A类的相关data或者function都是通过这个指针。所以说,在子类中,A对象只有一个,其他父类中如果虚拟继承了类A,只不过是把这个指针指向了这个A对象,而这些操作都是子类的构造函数完成的。 观察如下代码: class Top { public: int _top; }; class Left : public virtual Top { public: int _left; }; class Right : public virtual Top { public: int _right; }; class Bottom : public Left, public Right { public: int _bottom; }; 对于该继承体系,Bottom的对象内存布局应该如下:
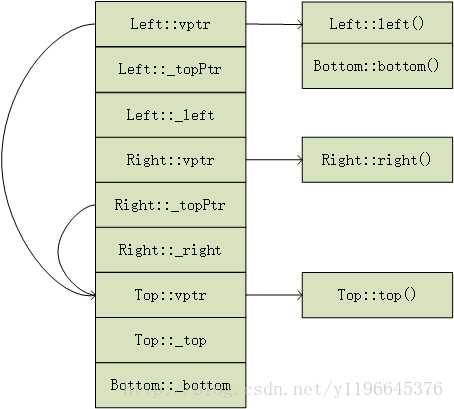
如果加上了虚函数呢? class Top { public: int _top; virtual int top(){ return _top; } }; class Left : public virtual Top { public: int _left; virtual int left(){ return _left; } }; class Right : public virtual Top { public: int _right; virtual int right(){ return _right; } }; class Bottom : public Left, public Right { public: int _bottom; virtual int bottom(){ return _bottom; } }; 对于该继承体系,Bottom的对象内存布局应该如下:
对于不同的编译器,对于虚拟继承的内存布局处理方式可能有区别,这里只是按照VC++2015编译器的解决方式来进行说明。 当然,本文章对内存模型的布局原因等没有过多着墨介绍。一是本人能力有限,怕言辞有误。二是的确本身c++标准对内存布局并没有很严格的规定,在各个编译器中有的细节设计也有不同之处。所以这里只是作为简单了解。如果想更进一步了解可以查看<Inside the C++ Object Model>一书。
谈谈对象大小——从字节对齐到对象模型原创YzlCoder 发布于2017-02-02 22:39:24 阅读数 616 收藏展开
一. 前言 这篇文章主要介绍以下从c的结构体变量到c++的类对象中编译器对内存分配做的事情。总而言之,言而总之,这篇文章就是讲述对于一个变量(对象)它的内存布局是怎么样子的。 为了方便描述,我们按照以下几个层次来讲述: 1.c中struct的字节对齐 2.从struct到class的过渡 3.单继承对对象内存模型的影响 4.虚函数对对象内存布局的影响 5.多继承对对象内存模型的影响 6.虚基类对对象内存布局的影响
二. c中struct的字节对齐 在谈字节对齐之前,我们先思考一下下面这个结构体大小?
struct node{};123 没错,就是一个空结构体,按道理来说,如果没有数据应该内存大小为0,然而事实上并不是这样。它有一个隐藏的1B大小,那是呗编译器安插进去的一个char,这使得这个struct对应的对象在内存中有独一无二的地址。 下面就来了解字节对齐:
许多计算机系统对基本数据类型变量的地址做了约束,这样做是为了提高bus(总线)对数据存取的效率。比如,我们如果对一个int类型数据进行读写操作;如果int变量地址不是4的倍数,那么数据就会被分割在多个块中,那么cpu读写该变量就要进行多次访存。所以,字节对齐是操作系统对于性能提高的一种策略。 不同的系统中这些策略都是有区别的,例如: Linux系统: 对于2字节数据类型变量地址必须是2的倍数,其余数据类型变量地址必须是4的倍数。 Windows系统: 对于大小为k字节的数据类型变量必须是k的倍数。 而上述中提到的地址必须是x的倍数,换句话说也就是按照k对齐。我们可以更改对齐规则么?可以!不过一般我们不这么做,除非有特殊需求,比如thunk技术。 先看下面这段代码:
struct node{ char mem1; //sizeof(char) = 1 int mem2; //sizeof(int) = 4 char mem3;};struct node a;1234567 sizeof(a)的值应该是多少呢? 5? 12! 如果从未了解过字节对齐的朋友可能对这个答案感到很不可思议,因为这比本应该占的内存(5字节)的两倍还多。 但是事实上,按照上述所说的字节对齐规则来说,得到12这个答案其实并不意外。我们先来看来对齐规则:
1.对于基本数据类型变量按照其字节数大小k对齐。 2.对于结构体类型变量按照其成员中最大对齐量对齐。 ———保证结构体第一个变量满足对齐规则 3.对于结构体类型变量其大小要为其成员最大对齐量的整数倍 ———保证结构体数组中每个元素满足对齐规则。
所以按照上述规则,a的内存布局应该是这样的:
首先,mem1逻辑地址为0,满足按照1字节对齐;—–规则2 这时候分配mem2,因为mem2数据类型为int大小为4个字节,所以需要在中间插入3个字节的间隙,所以mem2的逻辑地址为4;—–规则1 这时候分配mem3,当前逻辑地址为8,满足按照1字节对齐,所以直接分配给mem3—–规则1 此时逻辑地址已经分配了9字节,然而不满足成员最大对齐量(int对齐量为4字节)的整数倍,所以还需要在最后插入3字节间隙。—–规则3
可能有的朋友还是对规则3的缘由不是很清楚,为什么还需要最后插入3个字节。如果我们申请一个结构体数组 : struct node arr[2];
假如我们最后不进行3个字节的间隙插入,那么很显然,即使arr[0]元素的每个成员满足对齐规则,然而数组要保证元素地址连续,那么必定导致arr[1]的第一个成员一定不满足对齐规则。
如何修改字节对齐的规则呢?请看下面这段代码:
#pragma pack(push,1) //使结构体按1字节方式对齐,将原来的对齐规则压栈struct node{ char mem1; int mem2;};#pragma pack(pop) //恢复原来的对齐规则
//sizeof(node) = 5 123456789
三. 从struct到class的过渡 首先,需要注意的一点是,在c++中,我们可以使用struct替换class,因为本质上这两个关键字除了default access section不一样以外,其他都是都无差别。 所以这里说,从struct到class的过渡的实质,只是在这里,我把struct认为一个数据集合体,没有private data,也没有member function等等,虽然struct可以代替class实现private data、member function、继承等等。 后面所谈到的继承派生等等都只是指class。
四.单继承对对象内存模型的影响 首先先来看下这段代码://带透明通道颜色信息的顶点结构class ColorAVertex{public: int _x,_y,_z; unsigned char _r,_g,_b,_a; //颜色rgba三通道值};123456 嗯,经过第二段和第三段的介绍,我们应该很容易推出 sizeof(ColorAVertex) = 16。 不过,经过分析之后,决定将其分裂成三层结构:
class Vertex{ int _x,_y,_z;};class ColorVertex:public Vertex{public: unsigned char _r,_g,_b;};class ColorAVertex:public ColorVertex{public: unsigned char _a;};1234567891011 从设计的角度来看,可能这个结构相对更加合理,但是从实现的角度来说,我们发现一个事情:sizeof(ColorAVertex) = 20 嗯,要对这个问题追根溯源,我们就需要了解单继承对对象模型产生的影响。我们可以观察上述两种情况对应产生的对象模型:
可以看出来,在第二种情况,内存布局中间多了一段间隙。而这段间隙的来源就是ColorVertex类要满足规则3.而在ColorAVertex继承ColorVertex的后,_a并不会接着_b之后,而是需要保持那段间隔。因为继承派生是is a 关系,所以在ColorAVertex的内存布局中不能改变ColorVertex的布局结构。不过在其他某些编译器种,并不是这样实现的。 VC++2015 : sizeof(ColorAVertex) = 20 GUN GCC : sizeof(ColorAVertex) = 16 除此之外,还有一些member类型需要注意:static member 和 member function( 不包括 virtual function ) 。这些类型的成员是不会引起对象内存布局的变化的。这些数据成员并不是存在每个对象的内存模型之中。
我们再来看下面这种情况:
struct A{};struct B:A{};123456 在上面我们了解到如果member data为空,那么编译器会安插一个char,那么在这段代码中B的大小是2还是1呢? 事实上,当B继承A之后,因为A已经安插了一个char了,B就不为空了,所以说sizeof(B) = 1。
五.虚函数对对象内存布局的影响 在上一段末尾中提到,member function不影响对象内存布局,但是把virtual function排除开外了。因为virtual function作为c++运行时多态的核心,而为了支持这一特性,在对象内部也添加了相应的一些信息。 例如:下面这段代码:
class A{public: int a; virtual void say(){ printf("A::say()
"); }};class B:public A{public: int b; void say(){ printf("B::say()
"); }};int main(){ A* p = ....; p->say(); return 0;}123456789101112131415161718 在以上继承体系中,编译阶段并不能知道A* p真正的类型,而编译阶段就需要进行函数绑定,而真正的函数只有在运行阶段才知道。所以,对象内部必须要存储相应的动态类型信息,这样才能实现动态绑定。而这样的信息就是vptr,也就是虚表指针,指向一个虚函数表。而一个类的虚函数表只有一个,也就是一个类的不同对象vptr值是相同的。 所以说,拥有虚函数的对象,会多4个字节用于存放vptr虚表指针,而存放位置由编译器决定,一般来说不是对象首部,就是尾部。不过大多数编译器都是放在对象首部,也就是说&vptr=&obj。 在单继承体系中,如果一个类的父类中已经有vptr了,那么在子类的虚函数只有可能是新添或者重写。而这些操作都是先复制父类的虚表,然后在其上修改。注意:在单继承体系中,对象内存模型中vptr只有一个,也就是后面的操作都是在vptr对应的虚表上覆盖或者新添。
六.多继承对对象内存模型的影响 在多继承体系中,对象的很多东西就会变得十分复杂,这里我们撇开这些复杂的特殊性不谈。只是简单谈谈在对象内存模型中的影响。 首先看下面这段代码:
class Top{public: int _top;};class Left: public Top{public: int _left;};class Right: public Top{public: int _right;};class Bottom: public Left,public Right{public: int _bottom;};12345678910111213141516
在继承过程中,由于Bottom继承了Left和Right,导致基类Top在Bottom中有两份实体。所以,Bottom的内存布局如下:
当然,有的时候,这样的重复并不是我们所希望的我,所以对于多继承中,这样的重复继承情况,c++提出了虚拟继承这样的概念来解决。
七.虚基类对对象内存布局的影响
嗯,如果要花篇幅去深究虚基类里面的种种细节,可能再写几千字也不为过。不过在这里我只是简单的介绍,如果类的继承体系中出现了虚基类会对内存布局产生的影响。
虚基类的内存布局难点是在于,既要保证多个继承源的情况下,虚基类只能有一个。并且子类的内存布局中不能改变父类的内存布局模式。这里就不探讨解决方案的相关的。直接给出常规编译器的解决方案之一吧(VC++2015)。如果一个类B虚拟继承自类A。相当于类B组合了一个A对象,并且含有一个指针指向A对象。而基于B对象读取A类的相关data或者function都是通过这个指针。所以说,在子类中,A对象只有一个,其他父类中如果虚拟继承了类A,只不过是把这个指针指向了这个A对象,而这些操作都是子类的构造函数完成的。
观察如下代码:
class Top {public: int _top;};class Left : public virtual Top {public: int _left;};class Right : public virtual Top {public: int _right;};class Bottom : public Left, public Right {public: int _bottom;};12345678910111213141516 对于该继承体系,Bottom的对象内存布局应该如下:
如果加上了虚函数呢?
class Top {public: int _top; virtual int top(){ return _top; }};class Left : public virtual Top {public: int _left; virtual int left(){ return _left; }};class Right : public virtual Top {public: int _right; virtual int right(){ return _right; }};class Bottom : public Left, public Right {public: int _bottom; virtual int bottom(){ return _bottom; }};1234567891011121314151617181920 对于该继承体系,Bottom的对象内存布局应该如下:
对于不同的编译器,对于虚拟继承的内存布局处理方式可能有区别,这里只是按照VC++2015编译器的解决方式来进行说明。
当然,本文章对内存模型的布局原因等没有过多着墨介绍。一是本人能力有限,怕言辞有误。二是的确本身c++标准对内存布局并没有很严格的规定,在各个编译器中有的细节设计也有不同之处。所以这里只是作为简单了解。如果想更进一步了解可以查看<Inside the C++ Object Model>一书。
点赞 2收藏分享
YzlCoder发布了284 篇原创文章 · 获赞 383 · 访问量 59万+他的留言板关注C/C++—— 内存字节对齐规则阅读数 600
内存对齐规则博文来自: Be The Best!
————————————————版权声明:本文为CSDN博主「YzlCoder」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/y1196645376/article/details/54835979
以上是关于谈谈对象大小——从字节对齐到对象模型的主要内容,如果未能解决你的问题,请参考以下文章