Socket与内核调用深度分析
Posted n-p-2019-blogs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Socket与内核调用深度分析相关的知识,希望对你有一定的参考价值。
1 概念
Linux的设计哲学之一就是:对不同的操作赋予不同的执行等级,就是所谓特权的概念,即与系统相关的一些特别关键的操作必须由最高特权的程序来完成。
Intel的X86架构的CPU提供了0到3四个特权级,数字越小,特权越高,Linux操作系统中主要采用了0和3两个特权级,分别对应的就是内核态(Kernel Mode)与用户态(User Mode)。
- 内核态:CPU可以访问内存所有数据,包括外围设备(硬盘、网卡),CPU也可以将自己从一个程序切换到另一个程序;
- 用户态:只能受限的访问内存,且不允许访问外围设备,占用CPU的能力被剥夺,CPU资源可以被其他程序获取;
Linux中任何一个用户进程被创建时都包含2个栈:内核栈,用户栈,并且是进程私有的,从用户态开始运行。内核态和用户态分别对应内核空间与用户空间,内核空间中存放的是内核代码和数据,而进程的用户空间中存放的是用户程序的代码和数据。不管是内核空间还是用户空间,它们都处于虚拟空间中。
2 内核空间相关
- 内核空间:存放的是内核代码和数据,处于虚拟空间;
- 内核态:当进程执行系统调用而进入内核代码中执行时,称进程处于内核态,此时CPU处于特权级最高的0级内核代码中执行,当进程处于内核态时,执行的内核代码会使用当前进程的内核栈,每个进程都有自己的内核栈;
- CPU堆栈指针寄存器指向:内核栈地址;
- 内核栈:进程处于内核态时使用的栈,存在于内核空间;
- 处于内核态进程的权利:处于内核态的进程,当它占有CPU的时候,可以访问内存所有数据和所有外设,比如硬盘,网卡等等;
3 用户空间相关
- 用户空间:存放的是用户程序的代码和数据,处于虚拟空间;
- 用户态:当进程在执行用户自己的代码(非系统调用之类的函数)时,则称其处于用户态,CPU在特权级最低的3级用户代码中运行,当正在执行用户程序而突然被中断程序中断时,此时用户程序也可以象征性地称为处于进程的内核态,因为中断处理程序将使用当前进程的内核栈;
- CPU堆栈指针寄存器指向:用户堆栈地址;
- 用户堆栈:进程处于用户态时使用的堆栈,存在于用户空间;
- 处于用户态进程的权利:处于用户态的进程,当它占有CPU的时候,只可以访问有限的内存,而且不允许访问外设,这里说的有限的内存其实就是用户空间,使用的是用户堆栈;
4 scoket创建过程分析
在用户进程中,socket(int domain, int type, int protocol) 函数用于创建socket并返回一个与socket关联的fd,该函数实际执行的是系统调用 sys_socketcall,sys_socketcall几乎是用户进程socket所有操作函数的入口:
1 /** sys_socketcall (linux/syscalls.h)*/ 2 asmlinkage long sys_socketcall(int call, unsigned long __user *args);
sys_socketcall 实际调用的是 SYSCALL_DEFINE2:
1 /** SYSCALL_DEFINE2 (net/socket.c)*/ 2 SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args) 3 { 4 unsigned long a[AUDITSC_ARGS]; 5 unsigned long a0, a1; 6 int err; 7 unsigned int len; 8 // 省略... 9 a0 = a[0]; 10 a1 = a[1]; 11 12 switch (call) { 13 case SYS_SOCKET: 14 // 与 socket(int domain, int type, int protocol) 对应,创建socket 15 err = sys_socket(a0, a1, a[2]); 16 break; 17 case SYS_BIND: 18 err = sys_bind(a0, (struct sockaddr __user *)a1, a[2]); 19 break; 20 case SYS_CONNECT: 21 err = sys_connect(a0, (struct sockaddr __user *)a1, a[2]); 22 break; 23 // 省略... 24 }
在 SYSCALL_DEFINE2 函数中,通过判断call指令,来统一处理 socket 相关函数的事务,对于socket(…)函数,实际处理是在 sys_socket 中,也是一个系统调用,对应的是 SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol):
1 /** SYSCALL_DEFINE3 net/socket.c*/ 2 SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol) 3 { 4 int retval; 5 struct socket *sock; 6 int flags; 7 // SOCK_TYPE_MASK: 0xF; SOCK_STREAM等socket类型位于type字段的低4位 8 // 将flag设置为除socket基本类型之外的值 9 flags = type & ~SOCK_TYPE_MASK; 10 11 // 如果flags中有除SOCK_CLOEXEC或者SOCK_NONBLOCK之外的其他参数,则返回EINVAL 12 if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK)) 13 return -EINVAL; 14 15 // 取type中的后4位,即sock_type,socket基本类型定义 16 type &= SOCK_TYPE_MASK; 17 18 // 如果设置了SOCK_NONBLOCK,则不论SOCK_NONBLOCK定义是否与O_NONBLOCK相同, 19 // 均将flags中的SOCK_NONBLOCK复位,将O_NONBLOCK置位 20 if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK)) 21 flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK; 22 23 // 创建socket结构,(重点分析) 24 retval = sock_create(family, type, protocol, &sock); 25 if (retval < 0) 26 goto out; 27 28 if (retval == 0) 29 sockev_notify(SOCKEV_SOCKET, sock); 30 31 // 将socket结构映射为文件描述符retval并返回,(重点分析) 32 retval = sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK)); 33 if (retval < 0) 34 goto out_release; 35 out: 36 return retval; 37 out_release: 38 sock_release(sock); 39 return retval; 40 }
SYSCALL_DEFINE3 中主要判断了设置的socket类型type,如果设置了除基本sock_type,SOCK_CLOEXEC和SOCK_NONBLOCK之外的其他参数,则直接返回;同时调用 sock_create 创建 socket 结构,使用 sock_map_fd 将socket 结构映射为文件描述符并返回。在分析 sock_create 之前,先看看socket结构体:
1 /** socket结构体 (linux/net.h)*/ 2 struct socket { 3 socket_state state; // 连接状态:SS_CONNECTING, SS_CONNECTED 等 4 short type; // 类型:SOCK_STREAM, SOCK_DGRAM 等 5 unsigned long flags; // 标志位:SOCK_ASYNC_NOSPACE(发送队列是否已满)等 6 struct socket_wq __rcu *wq; // 等待队列 7 struct file *file; // 该socket结构体对应VFS中的file指针 8 struct sock *sk; // socket网络层表示,真正处理网络协议的地方 9 const struct proto_ops *ops; // socket操作函数集:bind, connect, accept 等 10 };
socket结构体中定义了socket的基本状态,类型,标志,等待队列,文件指针,操作函数集等,利用 sock 结构,将 socket 操作与真正处理网络协议相关的事务分离。
回到 sock_create 继续看socket创建过程,sock_create 实际调用的是 __sock_create:
1 /** __sock_create (net/socket.c)*/ 2 int __sock_create(struct net *net, int family, int type, int protocol, 3 struct socket **res, int kern) 4 { 5 int err; 6 struct socket *sock; 7 const struct net_proto_family *pf; 8 9 // 检查是否是支持的地址族,即检查协议 10 if (family < 0 || family >= NPROTO) 11 return -EAFNOSUPPORT; 12 // 检查是否是支持的socket类型 13 if (type < 0 || type >= SOCK_MAX) 14 return -EINVAL; 15 16 // 省略... 17 18 // 检查权限,并考虑协议集、类型、协议,以及 socket 是在内核中创建还是在用户空间中创建 19 // 可以参考:https://www.ibm.com/developerworks/cn/linux/l-selinux/ 20 err = security_socket_create(family, type, protocol, kern); 21 if (err) 22 return err; 23 24 // 分配socket结构,这其中创建了socket和关联的inode (重点分析) 25 sock = sock_alloc(); 26 if (!sock) { 27 net_warn_ratelimited("socket: no more sockets "); 28 return -ENFILE; /* Not exactly a match, but its the 29 closest posix thing */ 30 } 31 sock->type = type; 32 // 省略... 33 }
__socket_create 检查了地址族协议和socket类型,同时,调用 security_socket_create 检查创建socket的权限(如:创建不同类型不同地址族socket的SELinux权限也会不同)。接着,来看看 sock_alloc:
1 /** sock_alloc (net/socket.c)*/ 2 static struct socket *sock_alloc(void) 3 { 4 struct inode *inode; 5 struct socket *sock; 6 7 // 在已挂载的sockfs文件系统的super_block上分配一个inode 8 inode = new_inode_pseudo(sock_mnt->mnt_sb); 9 if (!inode) 10 return NULL; 11 12 // 获取inode对应socket_alloc中的socket结构指针 13 sock = SOCKET_I(inode); 14 15 inode->i_ino = get_next_ino(); 16 inode->i_mode = S_IFSOCK | S_IRWXUGO; 17 inode->i_uid = current_fsuid(); 18 inode->i_gid = current_fsgid(); 19 20 // 将inode的操作函数指针指向 sockfs_inode_ops 函数地址 21 inode->i_op = &sockfs_inode_ops; 22 23 this_cpu_add(sockets_in_use, 1); 24 return sock; 25 }
new_inode_pseudo 函数实际调用的是 alloc_inode(struct super_block *sb) 函数:
1 /** alloc_inode (fs/inode.c)*/ 2 static struct inode *alloc_inode(struct super_block *sb) 3 { 4 struct inode *inode; 5 6 // 如果文件系统的超级块已经指定了alloc_inode的函数,则调用已经定义的函数去分配inode 7 // 对于sockfs,已经将alloc_inode指向sock_alloc_inode函数指针 8 if (sb->s_op->alloc_inode) 9 inode = sb->s_op->alloc_inode(sb); 10 else 11 // 否则在公用的 inode_cache slab缓存上分配inode 12 inode = kmem_cache_alloc(inode_cachep, GFP_KERNEL); 13 14 if (!inode) 15 return NULL; 16 17 // 编译优化,提高执行效率,inode_init_always正常返回0 18 if (unlikely(inode_init_always(sb, inode))) { 19 if (inode->i_sb->s_op->destroy_inode) 20 inode->i_sb->s_op->destroy_inode(inode); 21 else 22 kmem_cache_free(inode_cachep, inode); 23 return NULL; 24 } 25 26 return inode; 27 }
从前文 “socket文件系统注册” 提到的:”.alloc_inode = sock_alloc_inode” 可知,alloc_inode 实际将使用 sock_alloc_inode 函数去分配 inode:
1 /** sock_alloc_inode (net/socket.c)*/ 2 static struct inode *sock_alloc_inode(struct super_block *sb) 3 { 4 // socket_alloc 结构体包含一个socket和一个inode,将两者联系到一起 5 struct socket_alloc *ei; 6 struct socket_wq *wq; 7 8 // 在sock_inode_cachep缓存上分配一个socket_alloc 9 // sock_inode_cachep: 前文"socket文件系统注册"中已经提到,专用于分配socket_alloc结构 10 ei = kmem_cache_alloc(sock_inode_cachep, GFP_KERNEL); 11 if (!ei) 12 return NULL; 13 // 分配socket等待队列结构 14 wq = kmalloc(sizeof(*wq), GFP_KERNEL); 15 if (!wq) { 16 kmem_cache_free(sock_inode_cachep, ei); 17 return NULL; 18 } 19 // 初始化等待队列 20 init_waitqueue_head(&wq->wait); 21 wq->fasync_list = NULL; 22 wq->flags = 0; 23 // 将socket_alloc中socket的等待队列指向wq 24 RCU_INIT_POINTER(ei->socket.wq, wq); 25 26 // 初始化socket的状态,标志,操作集等 27 ei->socket.state = SS_UNCONNECTED; 28 ei->socket.flags = 0; 29 ei->socket.ops = NULL; 30 ei->socket.sk = NULL; 31 ei->socket.file = NULL; 32 33 // 返回socket_alloc中的inode 34 return &ei->vfs_inode; 35 }
5 内核跟踪
我们首先在 sys_socketcall 处建立断点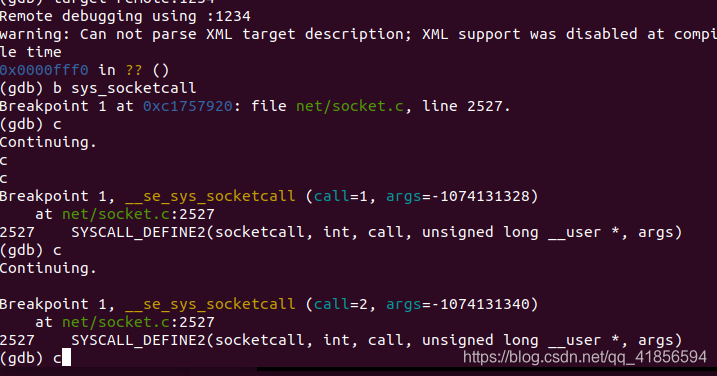
捕获到sys_socketcall,对应的内核处理函数为SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args)
在net/socket.c中查看SYSCALL_DEFINE2相关的源代码如下:
1 SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args) 2 { 3 unsigned long a[AUDITSC_ARGS]; 4 unsigned long a0, a1; 5 int err; 6 unsigned int len; 7 8 if (call < 1 || call > SYS_SENDMMSG) 9 return -EINVAL; 10 call = array_index_nospec(call, SYS_SENDMMSG + 1); 11 12 len = nargs[call]; 13 if (len > sizeof(a)) 14 return -EINVAL; 15 16 /* copy_from_user should be SMP safe. */ 17 if (copy_from_user(a, args, len)) 18 return -EFAULT; 19 20 err = audit_socketcall(nargs[call] / sizeof(unsigned long), a); 21 if (err) 22 return err; 23 24 a0 = a[0]; 25 a1 = a[1]; 26 27 switch (call) { 28 case SYS_SOCKET: 29 err = __sys_socket(a0, a1, a[2]); 30 break; 31 case SYS_BIND: 32 err = __sys_bind(a0, (struct sockaddr __user *)a1, a[2]); 33 break; 34 case SYS_CONNECT: 35 err = __sys_connect(a0, (struct sockaddr __user *)a1, a[2]); 36 break; 37 case SYS_LISTEN: 38 err = __sys_listen(a0, a1); 39 break; 40 case SYS_ACCEPT: 41 err = __sys_accept4(a0, (struct sockaddr __user *)a1, 42 (int __user *)a[2], 0); 43 break; 44 case SYS_GETSOCKNAME: 45 err = 46 __sys_getsockname(a0, (struct sockaddr __user *)a1, 47 (int __user *)a[2]); 48 break; 49 case SYS_GETPEERNAME: 50 err = 51 __sys_getpeername(a0, (struct sockaddr __user *)a1, 52 (int __user *)a[2]); 53 break; 54 case SYS_SOCKETPAIR: 55 err = __sys_socketpair(a0, a1, a[2], (int __user *)a[3]); 56 break; 57 case SYS_SEND: 58 err = __sys_sendto(a0, (void __user *)a1, a[2], a[3], 59 NULL, 0); 60 break; 61 case SYS_SENDTO: 62 err = __sys_sendto(a0, (void __user *)a1, a[2], a[3], 63 (struct sockaddr __user *)a[4], a[5]); 64 break; 65 case SYS_RECV: 66 err = __sys_recvfrom(a0, (void __user *)a1, a[2], a[3], 67 NULL, NULL); 68 break; 69 case SYS_RECVFROM: 70 err = __sys_recvfrom(a0, (void __user *)a1, a[2], a[3], 71 (struct sockaddr __user *)a[4], 72 (int __user *)a[5]); 73 break; 74 case SYS_SHUTDOWN: 75 err = __sys_shutdown(a0, a1); 76 break; 77 case SYS_SETSOCKOPT: 78 err = __sys_setsockopt(a0, a1, a[2], (char __user *)a[3], 79 a[4]); 80 break; 81 case SYS_GETSOCKOPT: 82 err = 83 __sys_getsockopt(a0, a1, a[2], (char __user *)a[3], 84 (int __user *)a[4]); 85 break; 86 case SYS_SENDMSG: 87 err = __sys_sendmsg(a0, (struct user_msghdr __user *)a1, 88 a[2], true); 89 break; 90 case SYS_SENDMMSG: 91 err = __sys_sendmmsg(a0, (struct mmsghdr __user *)a1, a[2], 92 a[3], true); 93 break; 94 case SYS_RECVMSG: 95 err = __sys_recvmsg(a0, (struct user_msghdr __user *)a1, 96 a[2], true); 97 break; 98 case SYS_RECVMMSG: 99 if (IS_ENABLED(CONFIG_64BIT) || !IS_ENABLED(CONFIG_64BIT_TIME)) 100 err = __sys_recvmmsg(a0, (struct mmsghdr __user *)a1, 101 a[2], a[3], 102 (struct __kernel_timespec __user *)a[4], 103 NULL); 104 else 105 err = __sys_recvmmsg(a0, (struct mmsghdr __user *)a1, 106 a[2], a[3], NULL, 107 (struct old_timespec32 __user *)a[4]); 108 break; 109 case SYS_ACCEPT4: 110 err = __sys_accept4(a0, (struct sockaddr __user *)a1, 111 (int __user *)a[2], a[3]); 112 break; 113 default: 114 err = -EINVAL; 115 break; 116 } 117 return err; 118 }
SYSCALL_DEFINE2根据不同的call来进入不同的分支,从而调用不同的内核处理函数,如__sys_bind, __sys_listen等等内核处理函数。
在SYSCALL_DEFINE2调用的与socket相关的函数们都打上断点,再进行调试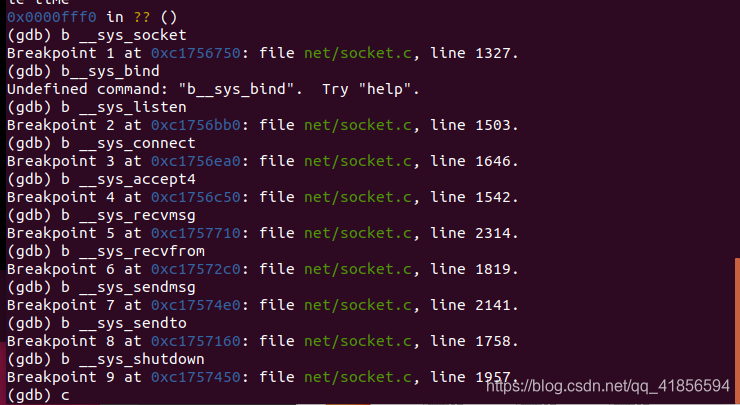
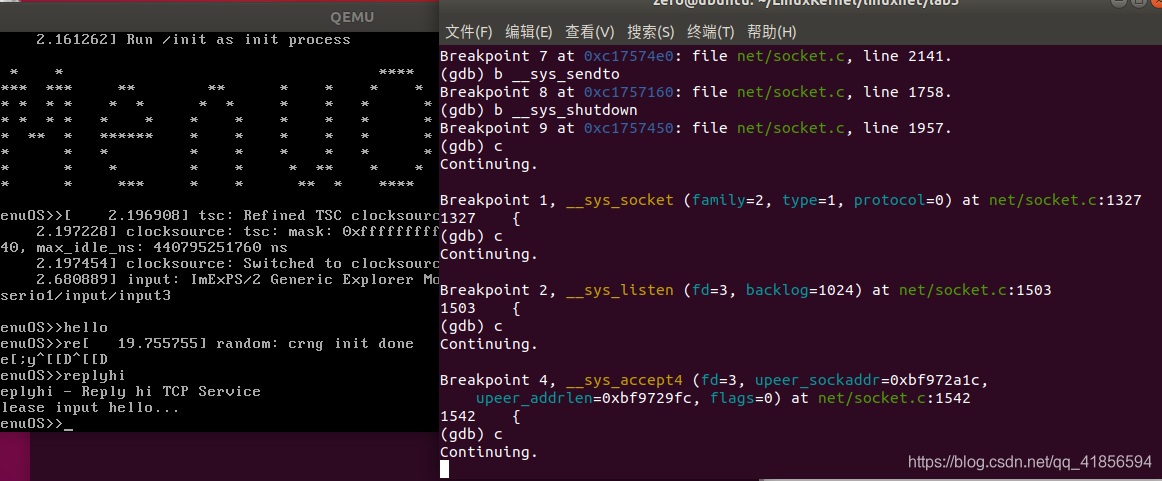
在Qemu中输入replyhi,发现gdb捕获到以上断点,一直到sys_accept4函数停止。说明此时服务器处于阻塞状态,一直在等待客户端连接,在Qemu中输入hello,同样捕获断点,可以看到客户端发起连接,发送接收数据,整个过程与TCP socket通信流程完全相同,至此,整个追踪过程结束。
以上是关于Socket与内核调用深度分析的主要内容,如果未能解决你的问题,请参考以下文章