爬取https://www.parenting.com/baby-names/boys/earl网站top10男女生名字及相关信息
Posted c1q2s3
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取https://www.parenting.com/baby-names/boys/earl网站top10男女生名字及相关信息相关的知识,希望对你有一定的参考价值。
爬取源代码如下:
import requests
import bs4
from bs4 import BeautifulSoup
import re
import pandas as pd
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding=‘gb18030‘)
import bs4
from bs4 import BeautifulSoup
import re
import pandas as pd
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding=‘gb18030‘)
lilist=[]
r=requests.get(‘https://www.parenting.com/baby-names/boys/earl‘)
soup=BeautifulSoup(r.text,"lxml")
soup= soup.find_all(‘a‘,href=True)
for i in soup:
if ‘https://www.parenting.com/pregnancy/baby-names/baby-boy-names/‘ in str(i)or‘https://www.parenting.com/pregnancy/baby-names/girl-baby-names/‘ in str(i):
lilist.append(i.get("href"))
lilist1=[]
results1=[]
results=[]
results2=[]
results1=[]
results=[]
results2=[]
for i in list(set(lilist)):
r=requests.get(i)
soup=BeautifulSoup(r.text,"lxml")
Source=soup.find_all(‘p‘)
Source=soup.find_all(attrs={‘class‘: ‘description‘})
results0 = re.findall(‘<h4>(.*?)</h4>‘, r.text)
for c in results0:
if c!=‘‘:
lilist1.append(c)
#print(lilist1)
#lilist1=[]
Source=soup.find_all(attrs={‘class‘: ‘description‘})
results0 = re.findall(‘<h4>(.*?)</h4>‘, r.text)
for c in results0:
if c!=‘‘:
lilist1.append(c)
#print(lilist1)
#lilist1=[]
pattern = re.compile(‘<p><strong>Origin:</strong>s(.*?)</p>‘, re.S)
results += re.findall(pattern, str(Source))
pattern1 = re.compile(‘<p><strong>Meaning:</strong>s(.*?)</p>‘, re.S)
results1 += re.findall(pattern1, str(Source))
results += re.findall(pattern, str(Source))
pattern1 = re.compile(‘<p><strong>Meaning:</strong>s(.*?)</p>‘, re.S)
results1 += re.findall(pattern1, str(Source))
pattern2 = re.compile("<p><strong>Why it’s big:</strong>s(.*?)</p>", re.S)
results2 += re.findall(pattern2, str(Source))
results2 += re.findall(pattern2, str(Source))
print(lilist1)
print(results1)
print(results)
print(results2)
data = {
‘EnName‘:lilist1,
‘Meaning‘:results1,
‘Origin‘:results,
‘Description‘:results2
}
frame = pd.DataFrame(data)
frame.to_csv(‘wt10.csv‘,encoding="gb18030")
#print(results2)
csv文件截图:
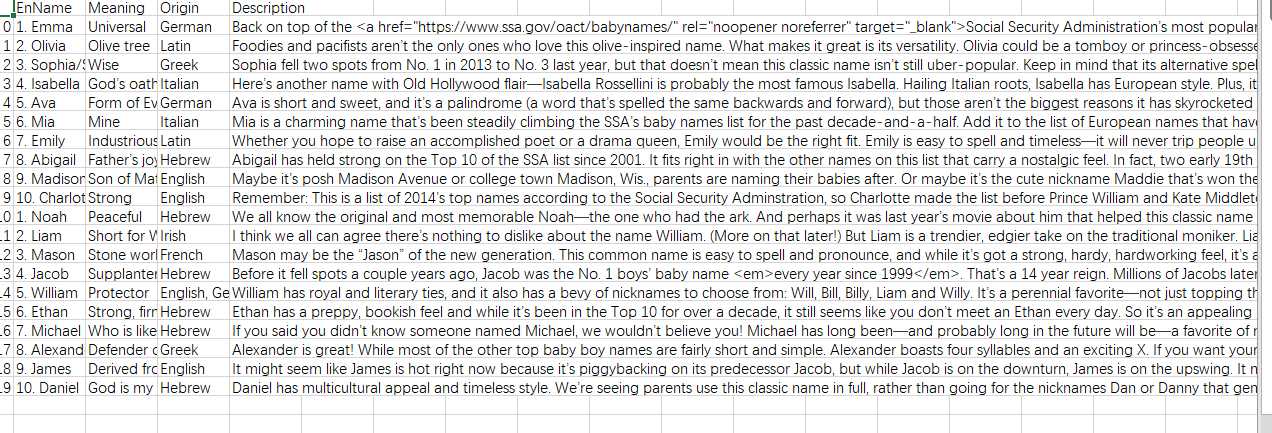
以上是关于爬取https://www.parenting.com/baby-names/boys/earl网站top10男女生名字及相关信息的主要内容,如果未能解决你的问题,请参考以下文章