7.Java内存模型详解
Posted qmillet
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了7.Java内存模型详解相关的知识,希望对你有一定的参考价值。
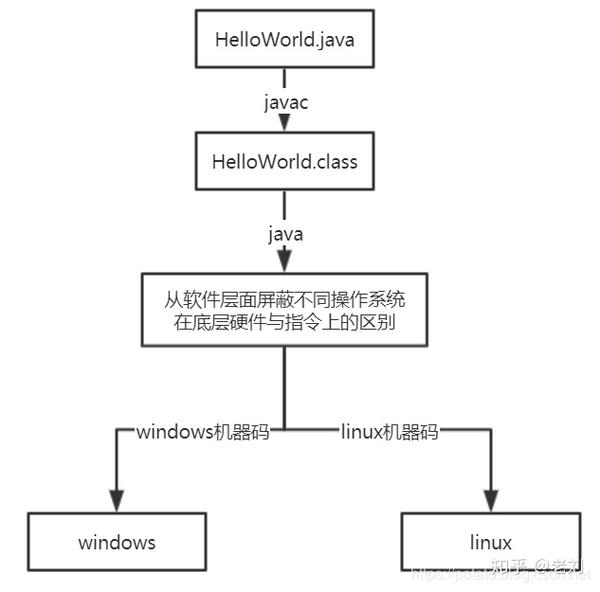
同样的java代码在不同平台生成的机器码肯定是不一样的,因为不同的操作系统底层的硬件指令集是不同的。
同一个java代码在windows上生成的机器码可能是0101.......,在linux上生成的可能是1100......,那么这是怎么实现的呢?
不知道同学们还记不记得,在下载jdk的时候,我们在oracle官网,基于不同的操作系统或者位数版本要下载不同的jdk版本,也就是说针对不同的操作系统,jdk虚拟机有不同的实现。
那么虚拟机又是什么东西呢,如图是从软件层面屏蔽不同操作系统在底层硬件与指令上的区别,也就是跨平台的由来。
说到这里同学们可能还是有点不太明白,说的还是太宏观了,那我们来了解下java虚拟机的组成。
二、虚拟机组成
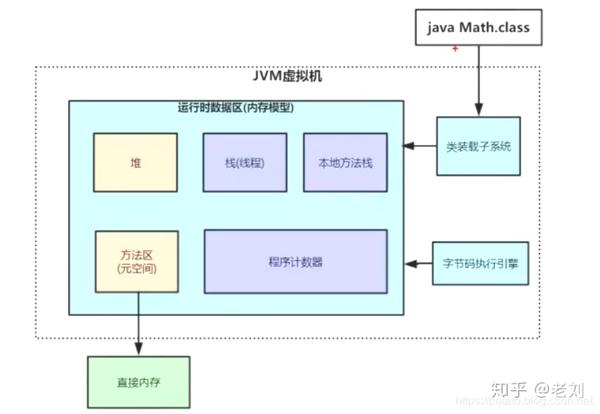
1.栈
我们先讲一下其中的一块内存区域栈,大家都知道栈是存储局部变量的,也是线程独有的区域,也就是每一个线程都会有自己独立的栈区域。
1 public class Math { 2 public static int initData = 666; 3 public static User user = new User(); 4 5 public int compute() { 6 int a = 1; 7 int b = 2; 8 int c = (a+b) * 10; 9 return c; 10 } 11 12 public static void main(String[] args) { 13 Math math = new Math(); 14 math.compute(); 15 System.out.println("test"); 16 } 17 }
说起栈大家都不会陌生,数据结构中就有学,这里线程栈中存储数据的部分使用的就是栈,先进后出。
大家都知道每个方法都有自己的局部变量,比如上图中main方法中的math,compute方法中的a b c,那么java虚拟机为了区分不同方法中局部变量作用域范围的内存区域,每个方法在运行的时候都会分配一块独立的栈帧内存区域,我们试着按上图中的程序来简单画一下代码执行的内存活动。

执行main方法中的第一行代码是,栈中会分配main()方法的栈帧,并存储math局部变量,,接着执行compute()方法,那么栈又会分配compute()的栈帧区域。
这里的栈存储数据的方式和数据结构中学习的栈是一样的,先进后出。当compute()方法执行完之后,就会出栈被释放,也就符合先进后出的特点,后调用的方法先出栈。
栈帧
那么栈帧内部其实不只是存放局部变量的,它还有一些别的东西,主要由四个部分组成。

那么要讲这个就会涉及到更底层的原理--字节码。我们先看下我们上面代码的字节码文件。
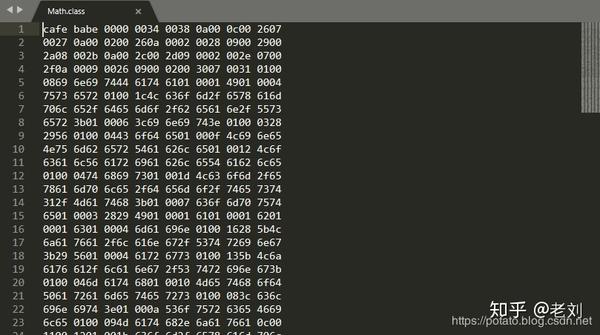
看着就是一个16字节的文件,看着像乱码,其实每个都是有对应的含义的,oracle官方是有专门的jvm字节码指令手册来查询每组指令对应的含义的。那我们研究的,当然不是这个。
jdk有自带一个javap的命令,可以将上述class文件生成一种更可读的字节码文件。
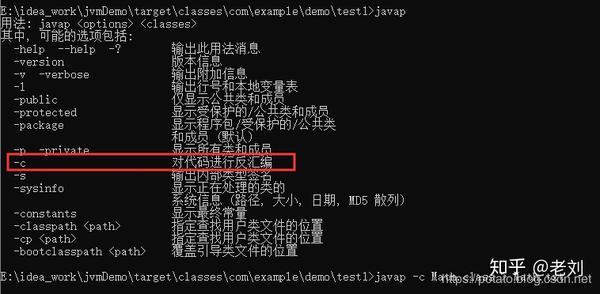
我们使用javap -c命令将class文件反编译并输出到TXT文件中。
1 Compiled from "Math.java" 2 public class com.example.demo.test1.Math { 3 public static int initData; 4 5 public static com.example.demo.bean.User user; 6 7 public com.example.demo.test1.Math(); 8 Code: 9 0: aload_0 10 1: invokespecial #1 // Method java/lang/Object."<init>":()V 11 4: return 12 13 public int compute(); 14 Code: 15 0: iconst_1 16 1: istore_1 17 2: iconst_2 18 3: istore_2 19 4: iload_1 20 5: iload_2 21 6: iadd 22 7: bipush 10 23 9: imul 24 10: istore_3 25 11: iload_3 26 12: ireturn 27 28 public static void main(java.lang.String[]); 29 Code: 30 0: new #2 // class com/example/demo/test1/Math 31 3: dup 32 4: invokespecial #3 // Method "<init>":()V 33 7: astore_1 34 8: aload_1 35 9: invokevirtual #4 // Method compute:()I 36 12: pop 37 13: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream; 38 16: ldc #6 // String test 39 18: invokevirtual #7 // Method java/io/PrintStream.println:(Ljava/lang/String;)V 40 21: return 41 42 static {}; 43 Code: 44 0: sipush 666 45 3: putstatic #8 // Field initData:I 46 6: new #9 // class com/example/demo/bean/User 47 9: dup 48 10: invokespecial #10 // Method com/example/demo/bean/User."<init>":()V 49 13: putstatic #11 // Field user:Lcom/example/demo/bean/User; 50 16: return 51 }
此时的jvm指令码就清晰很多了,大体结构是可以看懂的,类、静态变量、构造方法、compute()方法、main()方法。
其中方法中的指令还是有点懵,我们举compute()方法来看一下:
1 Code: 2 0: iconst_1 3 1: istore_1 4 2: iconst_2 5 3: istore_2 6 4: iload_1 7 5: iload_2 8 6: iadd 9 7: bipush 10 10 9: imul 11 10: istore_3 12 11: iload_3 13 12: ireturn
这几行代码就是对应的我们代码中compute()方法中的四行代码。大家都知道越底层的代码,代码实现的行数越多,因为他会包含一些java代码在运行时底层隐藏的一些细节原理。
那么一样的,这个jvm指令官方也是有手册可以查阅的,网上也有很多翻译版本,大家如果想了解可自行百度。
这里我只讲解本博文设计代码中的部分指令含义:
0. 将int类型常量1压入操作数栈
0: iconst_1 这一步很简单,就是将1压入操作数栈
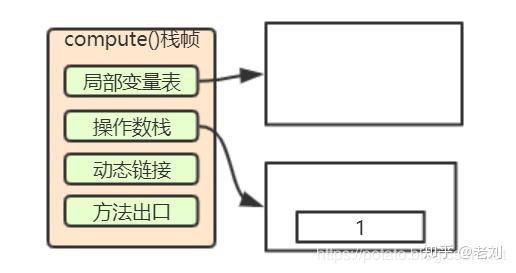
1. 将int类型值存入局部变量1
1: istore_1 局部变量1,在我们代码中也就是第一个局部变量a,先给a在局部变量表中分配内存,然后将int类型的值,也就是目前唯一的一个1存入局部变量a
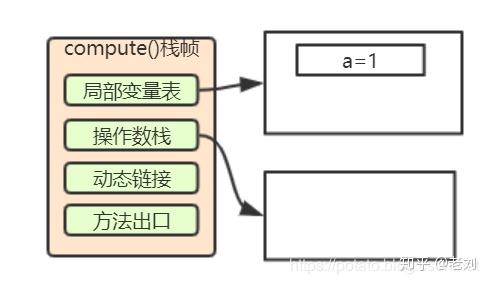
2. 将int类型常量2压入操作数栈
2: iconst_23. 将int类型值存入局部变量2
3: istore_2这两行代码就和前两行类似了。

4. 从局部变量1中装载int类型值
4: iload_15. 从局部变量2中装载int类型值
5: iload_2这两个代码是将局部变量1和2,也就是a和b的值装载到操作数栈中
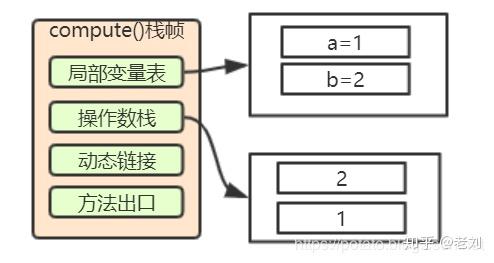
6. 执行int类型的加法
6: iaddiadd指令一执行,会将操作数栈中的1和2依次从栈底弹出并相加,然后把运算结果3在压入操作数栈底。
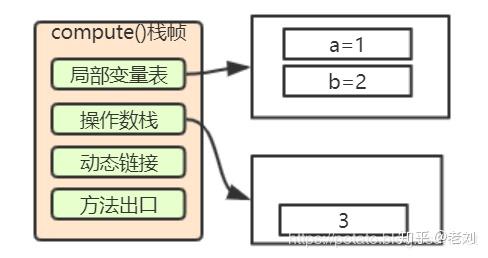
7. 将一个8位带符号整数压入栈
7: bipush 10这个指令就是将10压入栈
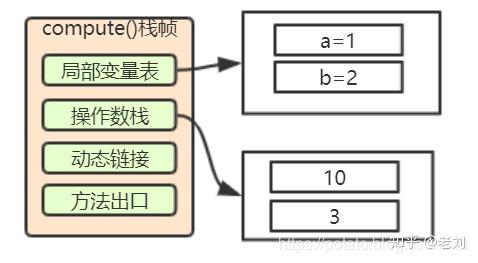
8. 执行int类型的乘法
9: imul这里就类似上面的加法了,将3和10弹出栈,把结果30压入栈
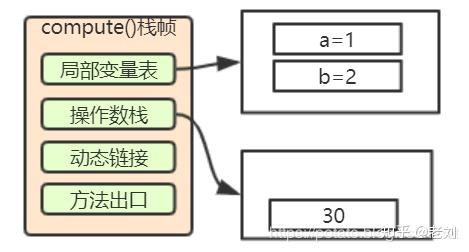
9. 将将int类型值存入局部变量3
10: istore_3这里大家就不陌生了吧,和第二步第三步是一样的,将30存入局部变量3,也就是c
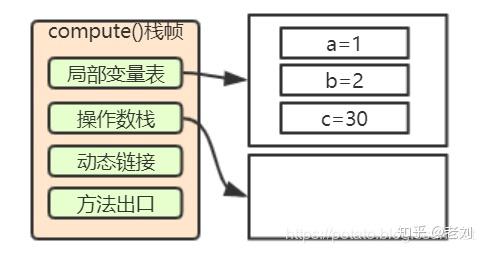
10. 从局部变量3中装载int类型值
11: iload_3这个前面也说了
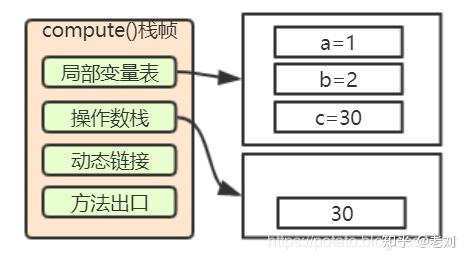
11. 返回int类型值
12: ireturn这个就不用多说了,就是将操作数栈中的30返回
到这里就把我们compute()方法讲解完了,讲完有没有对局部变量表和操作数栈的理解有所加深呢?说白了赋值号=后面的就是操作数,在这些操作数进行赋值,运算的时候需要内存存放,那就是存放在操作数栈中,作为临时存放操作数的一小块内存区域。
接下来我们再说说方法出口。
方法出口说白了不就是方法执行完了之后要出到哪里,那么我们知道上面compute()方法执行完之后应该回到main()方法第三行那么当main()方法调用compute()的时候,compute()栈帧中的方法出口就存储了当前要回到的位置,那么当compute()方法执行完之后,会根据方法出口中存储的相关信息回到main()方法的相应位置。
那么main()方同样有自己的栈帧,在这里有些不同的地方我们讲一下。
我们上面已经知道局部变量会存放在栈帧中的局部变量表中,那么main()方法中的math会存入其中,但是这里的math是一个对象,我们知道new出来的对象是存放在堆中的

那么这个math变量和堆中的对象有什么联系呢?是同一个概念么?
当然不是的,局部变量表中的math存储的是堆中那个math对象在堆中的内存地址
2. 程序计数器
程序计数器也是线程私有的区域,每个线程都会分配程序计数器的内存,是用来存放当前线程正在运行或者即将要运行的jvm指令码对应的地址,或者说行号位置。
上述代码中每个指令码前面都有一个行号,你就可以把它看作当前线程执行到某一行代码位置的一个标识,这个值就是程序计数器的值。
那么jvm虚拟机为什么要设置程序计数器这个结构呢?就是为了多线程的出现,多线程之间的切换,当一个程序被挂起的时候,总是要恢复的,那么恢复到哪个位置呢,总不能又重新开始执行吧,那么程序计数器就解决了这个问题。
3. 方法区
在jdk1.8之前,有一个名称叫做持久带/永久代,很多同学应该听过,在jdk1.8之后,oracle官方改名为元空间。存放常量、静态变量、类元信息。
public static int initData = 666;这个initData就是静态变量,毋庸置疑是存放在方法区的
public static User user = new User();那么这个user就有点不一样了,user变量放在方法区,new的User是存放在堆中的
到这里我们就能意识到栈,堆,方法区之间都是有联系的。

栈中的局部变量,方法区中的静态变量,如果是对象类型的话都会指向堆中new出来中的对象,那么红色的联系代表什么呢?我们先来了解一下对象。
对象组成
你对对象的了解有多少呢,天天用对象,你是否知道对象在虚拟机中的存储结构呢?
对象在内存中存储的布局可以分为3块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。下图是普通对象实例与数组对象实例的数据结构:
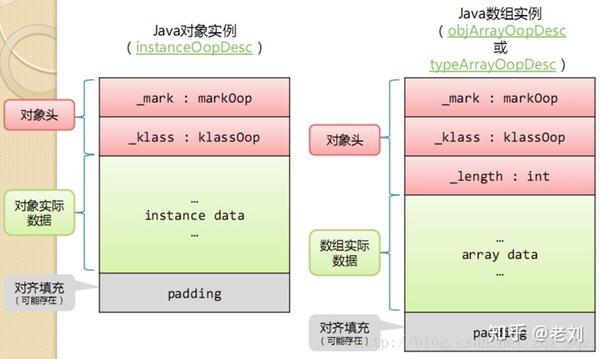
对象头
HotSpot虚拟机的对象头包括两部分信息:
Mark Word
第一部分markword,用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等,这部分数据的长度在32位和64位的虚拟机(未开启压缩指针)中分别为32bit和64bit,官方称它为“MarkWord”。
Klass Pointer
对象头的另外一部分是klass类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例.
数组长度(只有数组对象有)
如果对象是一个数组, 那在对象头中还必须有一块数据用于记录数组长度.
实例数据
实例数据部分是对象真正存储的有效信息,也是在程序代码中所定义的各种类型的字段内容。无论是从父类继承下来的,还是在子类中定义的,都需要记录起来。
对齐填充
第三部分对齐填充并不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用。由于HotSpot VM的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说,就是对象的大小必须是8字节的整数倍。而对象头部分正好是8字节的倍数(1倍或者2倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
其中的klass类型指针就是那条红色的联系,那是怎么联系的呢?
new Thread().start();
类加载其实最终是以类元信息的形式存储在方法区中的,math和math2都是由同一个类new出来的,当对象被new时,都会在对象头中存储一个指向类元信息的指针,这就是Klass Pointer.
到这里我们就讲解了栈,程序计数器和方法区,下面我们简单介绍一下本地方法区,最后再终点讲解堆。
4.本地方法栈
实际上现在本地方法栈已经用的比较少了,大家应该都有听过本地方法吧
如何经常用的线程类
1 new Thread().start(); 2 3 4 5 public synchronized void start() { 6 if (threadStatus != 0) 7 throw new IllegalThreadStateException(); 8 group.add(this); 9 boolean started = false; 10 try { 11 start0(); 12 started = true; 13 } finally { 14 try { 15 if (!started) { 16 group.threadStartFailed(this); 17 } 18 } catch (Throwable ignore) { 19 } 20 } 21 }
其中底层调用了一个start0()的方法
private native void start0();这个方法没有实现,但又不是接口,是使用native修饰的,是属于本地方法,底层通过C语言实现的,那java代码里为什么会有C语言实现的本地方法呢?
大家都知道JAVA是问世的,在那之前一个公司的系统百分之九十九都是使用C语言实现的,但是java出现后,很多项目都要转为java开发,那么新系统和旧系统就免不了要有交互,那么就需要本地方法来实现了,底层是调用C语言中的dll库文件,就类似于java中的jar包,当然,如今跨语言的交互方式就很多了,比如thrift,http接口方式,webservice等,当时并没有这些方式,就只能通过本地方法来实现了。
那么本地方法始终也是方法,每个线程在运行的时候,如果有运行到本地方法,那么必然也要产生局部变量等,那么就需要存储在本地方法栈了。如果没有本地方法,也就没有本地方法栈了。
5.堆
最后我们讲堆,堆是最重要的一块内存区域,我相信大部分人对堆都不陌生。但是对于它的内部结构,运作细节想要搞清楚也没那么简单。
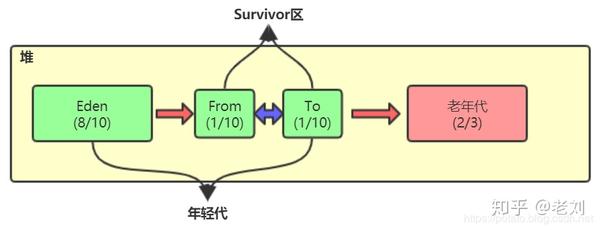
对于这个基本组成大家应该都有所了解,对就是由年轻代和老年代组成,年轻代又分为伊甸园区和survivor区,survivor区中又有from区和to区.
我们new出来的对象大家都知道是放在堆中,那具体放在堆中的哪个位置呢?
其实new出来的对象一般都放在Eden区,那么为什么叫伊甸园区呢,伊甸园就是亚当夏娃住的地方,不就是造人的地方么?所以我们new出来的对象就是放在这里的,那当Eden区满了之后呢?
假设我们给对分配600M内存,这个是可以通过参数调节的,我们后文再讲。那么老年代默认是占2/3的,也就是差不多400M,那年轻代就是200M,Eden区160M,Survivor区40M。
GC

一个程序只要在运行,那么就不会不停的new对象,那么总有一刻Eden区会放满,那么一旦Eden区被放满之后,虚拟机会干什么呢?没错,就是gc,不过这里的gc属于minor gc,就是垃圾收集,来收集垃圾对象并清理的,那么什么是垃圾对象呢?
好比我们上面说的math对象,我们假设我们是一个web应用程序,main线程执行完之后程序不会结束,但是main方法结束了,那么main()方法栈帧会被释放,局部变量会被释放,但是局部变量对应的堆中的对象还是依然存在的,但是又没有指针指向它,那么它就是一个垃圾对象,那就应该被回收掉了,之后如果还会new Math对象,也不会用这个之前的了,因为已经无法找到它了,如果留着这个对象只会占用内存,显然是不合适的。
这里就涉及到了一个GC Root根以及可达性分析算法的概念,也是面试偶尔会被问到的。
可达性分析算法是将GC Roots对象作为起点,从这些起点开始向下搜索引用的对象,找到的对象都标记为非垃圾对象,其余未标记的都是垃圾对象。
那么GC Roots根对象又是什么呢,GC Roots根就是判断一个对象是否可以回收的依据,只要能通过GC Roots根向下一直搜索能搜索到的对象,那么这个对象就不算垃圾对象,而可以作为GC Roots根的有线程栈的本地变量,静态变量,本地方法栈的变量等等,说白了就是找到和根节点有联系的对象就是有用的对象,其余都认为是垃圾对象来回收。
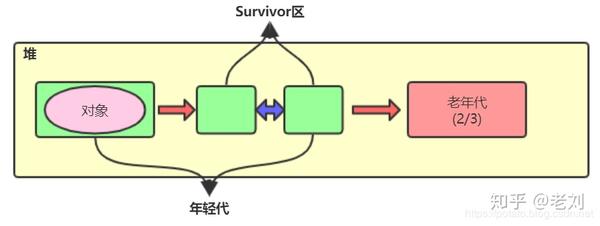
经历了第一次minor gc后,没有被清理的对象就会被移到From区,如上图。
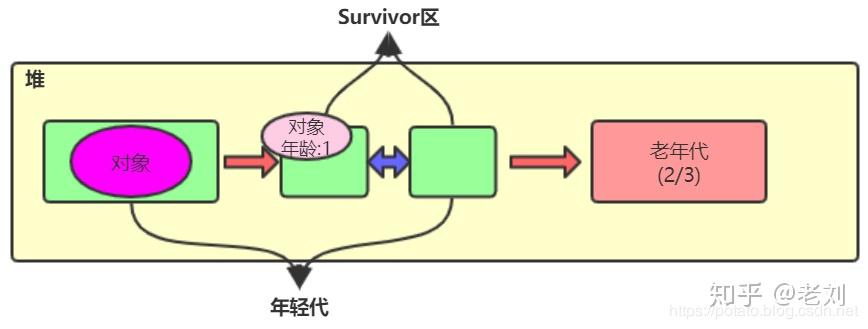
上面在说对象组成的时候有写到,在对象头的Mark Word中有存储GC分代年龄,一个对象每经历一次gc,那么它的gc分代年龄就会+1,如上图。
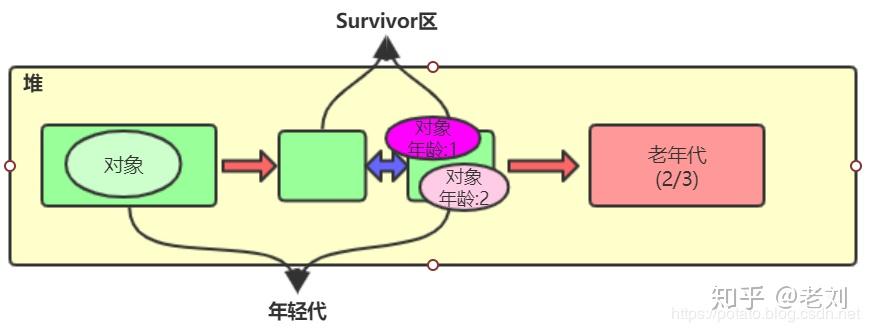
那么如果第二次新的对象又把Eden区放满了,那么又会执行minor gc,但是这次会连着From区一起gc,然后将Eden区和From区存活的对象都移到To区域,对象头中分代年龄都+1,如上图。
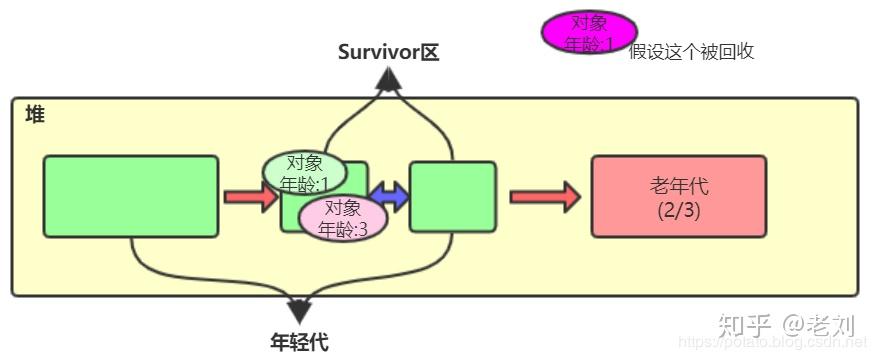
那么当第三次Eden区又满的时候,minor gc就是回收Eden区和To区域了,TEden区和To区域还活着的对象就会都移到From区,如上图。说白了就是Survivor区中总有一块区域是空着的,存活的对象存放是在From区和To区轮流存放,也就是互相复制拷贝,这也就是垃圾回收算法中的复制-回收算法。
如果一个对象经历了一个限值15次gc的时候,就会移至老年代。那如果还没有到限值,From区或者To区域也放不下了,就会直接挪到老年代,这只是举例了两种常规规则,还有其他规则也是会把对象存放至老年代的。
那么随着应用程序的不断运行,老年代最终也是会满的,那么此时也会gc,此时的gc就是Full gc了。
GC案例
下面我们通过一个简单的演示案例来更加清楚的了解GC。
1 public class HeapTest { 2 byte[] a = new byte[1024*100]; 3 public static void main(String[] args) throws InterruptedException { 4 ArrayList<HeapTest> heapTest = new ArrayList<>(); 5 while(true) { 6 heapTest.add(new HeapTest()); 7 Thread.sleep(10); 8 } 9 } 10 }
这块代码很明显,就是一个死循环,不断的往list中添加new出来的对象。
我们这里使用jdk自带的一个jvm调优工具jvisualvm来观察一下这个代码执行的的内存结构。
运行代码打开之后我们可以看到这样的界面:
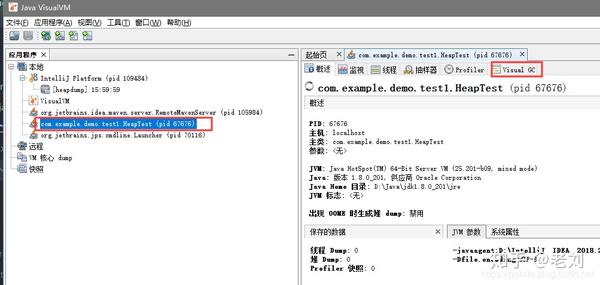
我们在左边的应用程序中可以看到我们运行的这个代码,右边是它的一些jvm,内存信息,我们这里不关注,我们需要用到的是最后一个Visual GC面板,这是一个插件,如果你的打开没有这一栏的话,可以再工具栏的插件中进行下载安装。
打开visual GC,我们先看一下界面大概的布局,
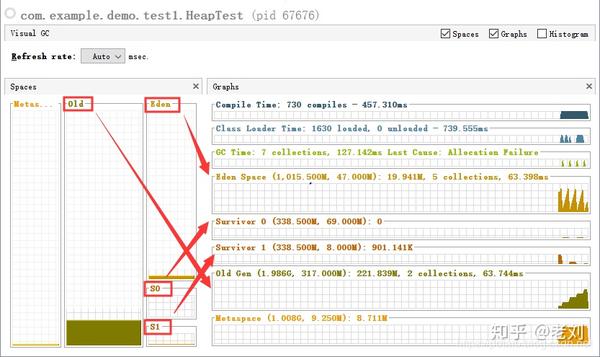
其中老年代(Olc),伊甸园区(Eden),S0(From),S1(To)几个区域的内存和动态分配图都是清晰可见,以一对应的。
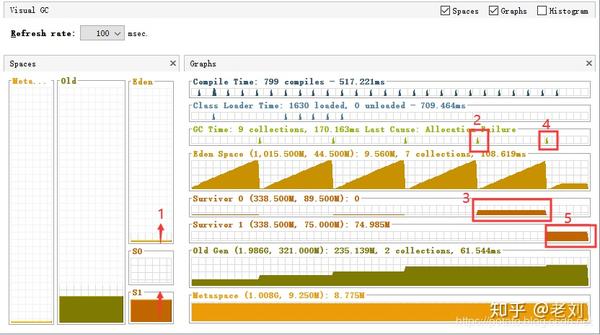
我们选择中间一张图给大家对应一下上面所讲的内容:
1:对象放入Eden区
2:Eden区满发生minor gc
3:第二步的存活对象移至From(Survivor 0)区
4:Eden区再满发生minor gc
5:第四步存活的对象移至To(Survivor 1)区

这里可以注意到From和To区域和我们上面所说移至,总有一个是空的。

大家还可以注意到老年代这里,都是一段一段的直线,中间是突然的增加,这就是在minor gc中一批一批符合规则的对象被批量移入老年代。
那当我们老年代满了会发生什么呢?当然是我们上面说过的Full GC,但是你仔细看我们写的这个程序,我们所有new出来的HeapTest对象都是存放在heapLists中的,那就会被这个局部变量所引用,那么Full GC就不会有什么垃圾对象可以回收,可是内存又满了,那怎么办?
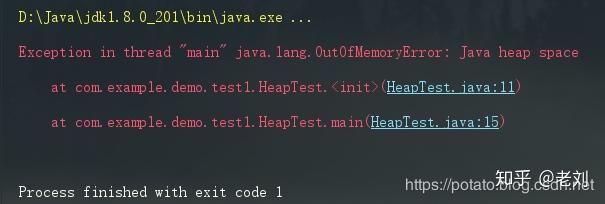
没错,就是我们就算没见过也总听过的OOM。
以上是关于7.Java内存模型详解的主要内容,如果未能解决你的问题,请参考以下文章
14.VisualVM使用详解15.VisualVM堆查看器使用的内存不足19.class文件--文件结构--魔数20.文件结构--常量池21.文件结构访问标志(2个字节)22.类加载机制概(代码片段