《STL源码剖析》——第四章序列容器
Posted zzw1024
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《STL源码剖析》——第四章序列容器相关的知识,希望对你有一定的参考价值。
1、容器的概观与分类
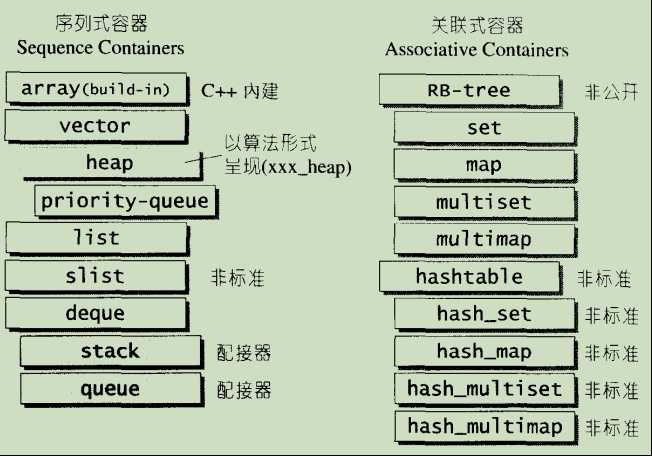
所谓序列式容器,其中的元素都可序(ordered)【比如可以使用sort进行排序】,但未必有序(sorted)。C++语言本身提供了一个序列式容器array,STL另外再提供vector,list,deque,stack,queue,priority-queue 等等序列式容器。其中stack和queue由于只是将 deque 头换面而成,技术上被归类为一种配接器(adapter)。
2、vector
vector的数据安排以及操作方式,与array非常相似。两者的唯一差别在于空间的运用的灵活性。
array是静态空间,一旦配置了就不能改变;要换个大(或小)一点的房子,可以,一切琐细得由客户端自己来:首先配置一块新空间,然后将元素从旧址一一搬往新址,再把原来的空间释还给系统。
vector是动态空间,随着元素的加入,它的内部机制会自行扩充空间以容纳新元素。因此,vector的运用对于内存的合理利用与运用的灵活性有很大的帮助,我们再也不必因为害怕空间不足而一开始就要求一个大块头array了,我们可以安心使用vector,吃多少用多少。
- 常用的源码:



注意:
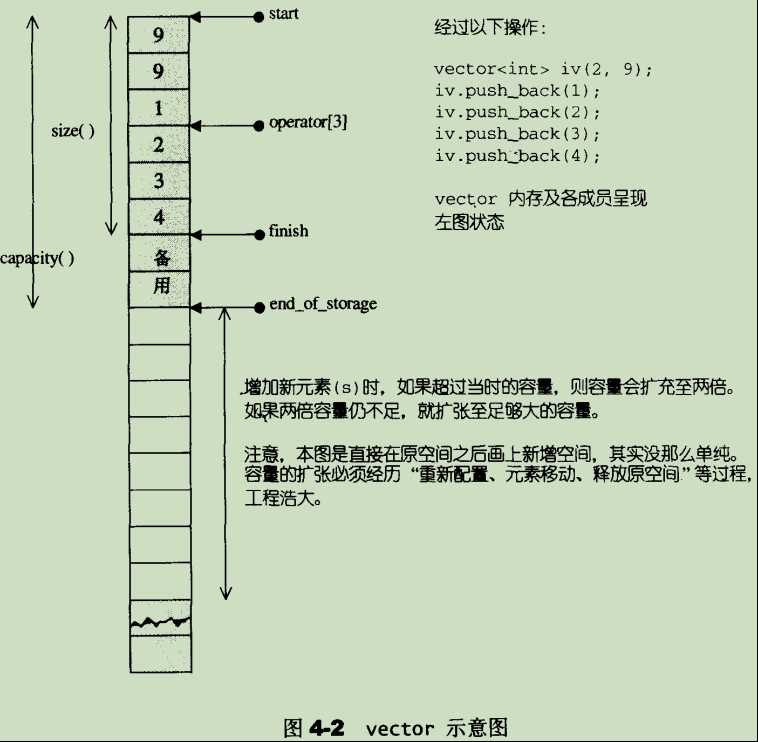
- size() & captical:
表示已存储数据的大小,而capital则是内部开辟的空间的大小
所以,在erase、pop_back、clear等删除操作,都不会使得其captial产生变化,只会变的就是size()
- 动态空间配置:
注意,所谓动态增加大小,并不是在原空间之后接续新空间(因为无法保证原空间之后尚有可供配置的空间),而是以原大小的两倍另外配置一块较大空间,然后将原内容拷贝过来,然后才开始在原内容之后构造新元素,并释放原空间。因此,对vector的任何操作,一旦引起空间重新配置,指向原vector的所有迭代器就都失效了。这是程序员易犯的一个错误,务需小心。
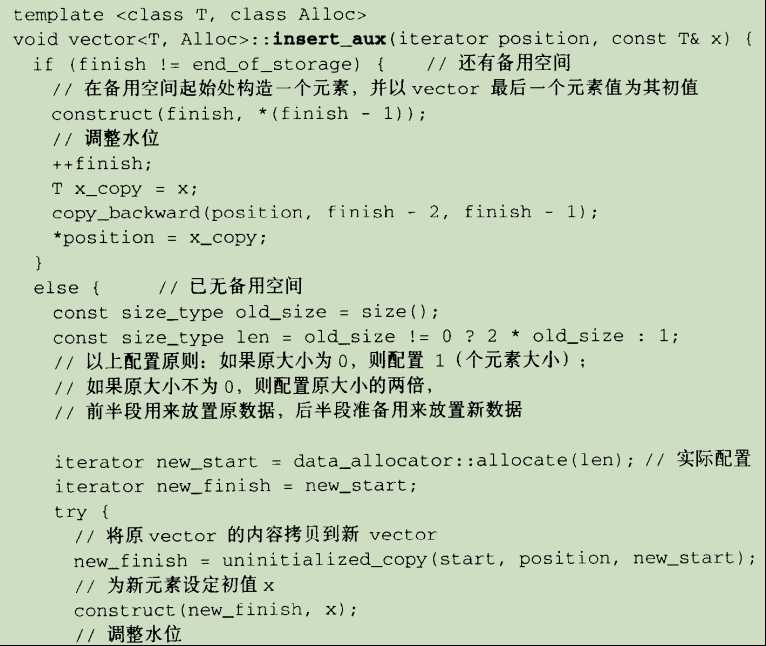

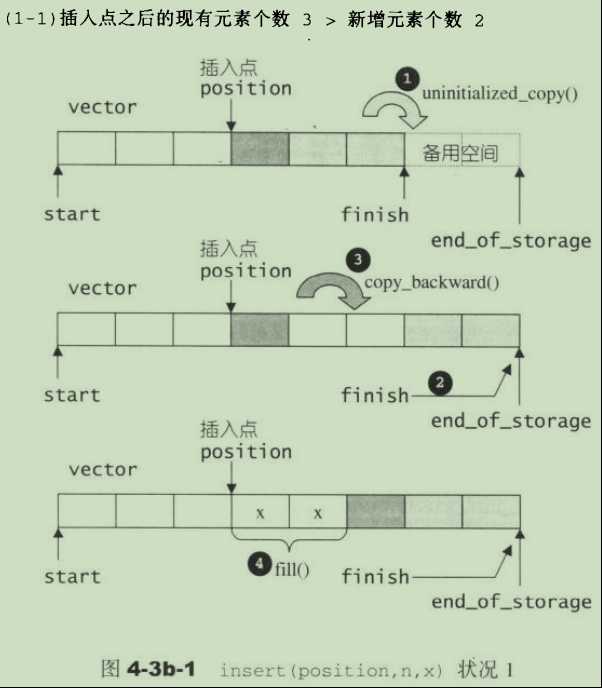
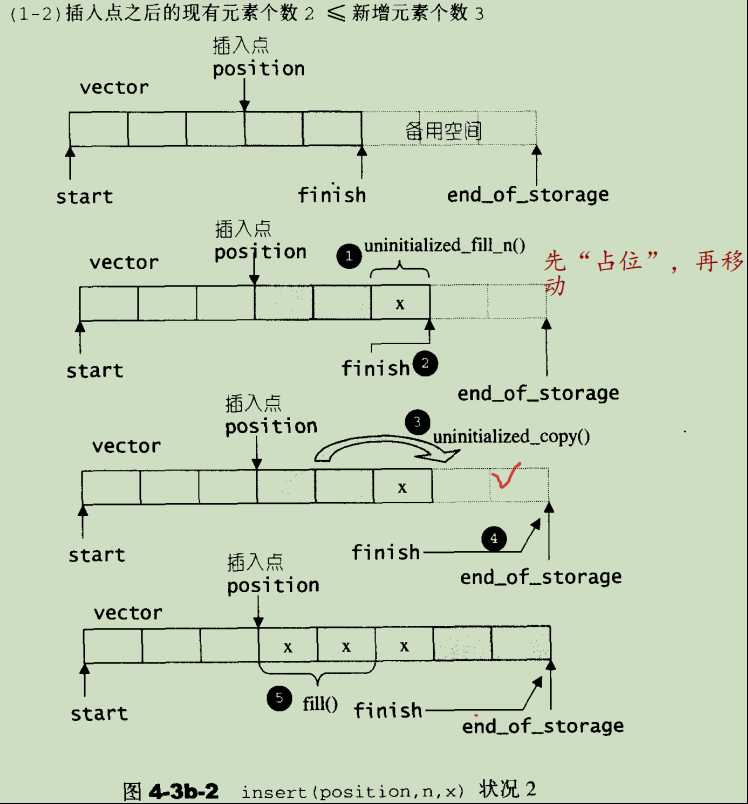
- insert():
insert()会根据需要插入元素的位置p以及p后面的元素个数与需要插入元素个数n进行比较,分两种情况进行插入
- emplace_back() VS push_back()减少内存拷贝和移动
1 struct President 2 { 3 President(std::string && p_name, std::string && p_country, int p_year) 4 : name(std::move(p_name)), country(std::move(p_country)), year(p_year) 5 { 6 std::cout << "I am being constructed. "; 7 } 8 President(President&& other) 9 : name(std::move(other.name)), country(std::move(other.country)), year(other.year) 10 { 11 std::cout << "I am being moved. "; 12 } 13 President& operator=(const President& other) = default; 14 }; 15 16 int main() 17 { 18 std::vector<President> elections; 19 std::cout << "emplace_back: "; 20 elections.emplace_back("Nelson Mandela", "South Africa", 1994); 21 22 std::vector<President> reElections; 23 std::cout << " push_back: "; 24 reElections.push_back(President("Franklin Delano Roosevelt", "the USA", 1936)); 25 } 26 emplace_back: 27 I am being constructed. 28 29 push_back: 30 I am being constructed. 31 I am being moved.
merge()函数:
merge方式要注意三点:
merge(vec1.begin(),vec1.end(),vec2.begin(),vec2.end(),vec3.begin());
1、vec1,和vec2需要经过排序,merge只能合并排序后的集合,不然会报错。
2、vec3需要指定好大小,不然会报错。
3、merge的时候指定vec3的位置一定要从begin开始,如果指定了end,它会认为没有空间,当然,中间的位置我没有试,回头有空试一下。
3、list
相较于vector的连续线性空间,1ist就显得复杂许多,它的好处是每次插人或删除一个元素,就配置或释放一个元素空间。因此,list 对于空间的运用有绝对的精准,一点也不浪费。而且,对于任何位置的元素插人或元素移除,list永远是常数时间。
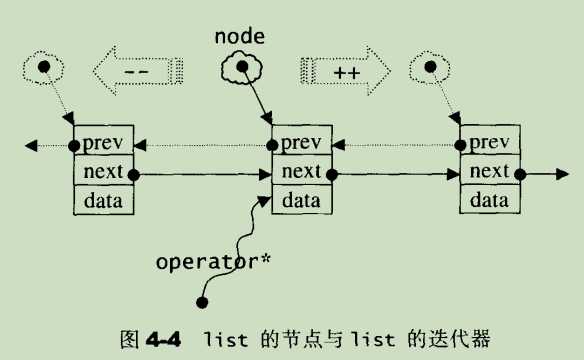
由于STL1ist是一个双向链表(double linked-list),迭代器必须具备前移、后移的能力,所以1ist 提供的是Bidirectional lterators。
list 有一个重要性质:插入操作(insert)和接合操作(splice)都不会造成原有的list迭代器失效。这在vector是不成立的,因为vector的插入操作可能造成记忆体重新配置,导致原有的迭代器全部失效。甚至1ist的元素删除操作(erase),也只有“指向被删除元素”的那个迭代器失效,其它迭代器不受任何影响。
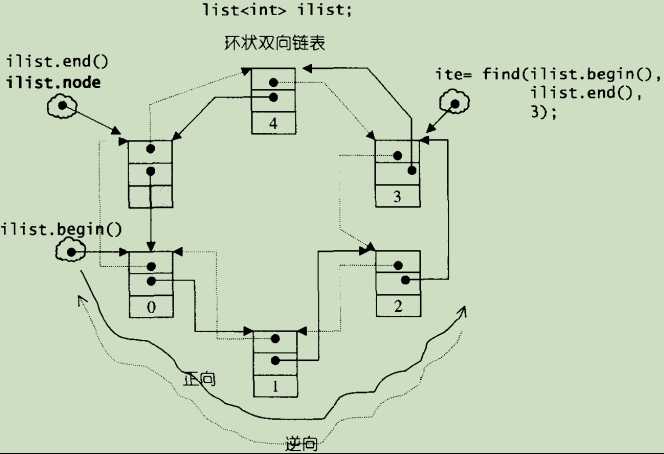
- SGI list 是一个环状双向链表,它只需要一个指针就可以完整表现整个链表
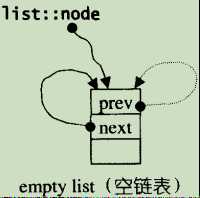
- list链表的初始结构:
node->next = node;
node->prv = node;
- .transfter() //迁移函数
void transfer(iterator position, iterator first, iterator last);
将list2的first-last之间的元素插入到list1中的position中
- .splice() //衔接函数
|
void splice( const_iterator pos, list& other ); |
(1) |
|
|
void splice( const_iterator pos, list&& other ); |
(1) |
(C++11 起) |
|
void splice( const_iterator pos, list& other, const_iterator it ); |
(2) |
|
|
void splice( const_iterator pos, list&& other, const_iterator it ); |
(2) |
(C++11 起) |
|
void splice( const_iterator pos, list& other, const_iterator first, const_iterator last); |
(3) |
|
|
void splice( const_iterator pos, list&& other, const_iterator first, const_iterator last ); |
(3) |
(C++11 起) |
从一个 list 转移元素给另一个。
不复制或移动元素,仅重指向链表结点的内部指针。若 get_allocator() != other.get_allocator() 则行为未定义。没有迭代器或引用被非法化,指向被移动元素的迭代器保持合法,但现在指代到 *this 中,而非到 other 中。
1) 从 other 转移所有元素到 *this 中。元素被插入到 pos 所指向的元素之前。操作后容器 other 变为空。若 other 与 *this 指代同一对象则行为未定义。
2) 从 other 转移 it 所指向的元素到 *this 。元素被插入到 pos 所指向的元素之前。
3) 从 other 转移范围 [first, last) 中的元素到 *this 。元素被插入到 pos 所指向的元素之前。若 pos 是范围 [first,last) 中的迭代器则行为未定义。
参数
|
pos |
- |
将插入内容到其前的元素 |
|
other |
- |
要自之转移内容的另一容器 |
|
it |
- |
要从 other 转移到 *this 的元素 |
|
first, last |
- |
要从 other 转移到 *this 的元素范围 |
- .merge()
|
c1.merge(c2) |
//合并2个有序的链表并使之有序,从新放到c1里,释放c2。 |
|
c1.merge(c2,comp) |
//合并2个有序的链表并使之按照自定义规则排序之后从新放到c1中,释放c2。 |
|
c1.splice(c1.beg,c2) |
//将c2连接在c1的beg位置,释放c2 |
|
c1.splice(c1.beg,c2,c2.beg) |
//将c2的beg位置的元素连接到c1的beg位置,并且在c2中释放掉beg位置的元素 |
|
c1.splice(c1.beg,c2,c2.beg,c2.end) |
//将c2的[beg,end)位置的元素连接到c1的beg位置并且释放c2的[beg,end)位置的元素 |
归并二个已排序链表为一个。链表应以升序排序。
不复制元素。操作后容器 other 变为空。若 other 与 *this 指代同一对象则函数不做任何事。若 get_allocator() != other.get_allocator() ,则行为未定义。没有引用和迭代器变得非法,除了被移动元素的迭代器现在指代到 *this 中,而非到 other 中,第一版本用 operator< 比较元素,第二版本用给定的比较函数 comp 。
此操作是稳定的:对于二个链表中的等价元素,来自 *this 的元素始终前驱来自 other 的元素,而且 *this 和 other 的等价元素顺序不更改。
参数
|
other |
- |
要交换的另一容器 |
|
comp |
- |
比较函数对象(即满足比较 (Compare) 概念的对象),若第一参数小于(即先序于)第二参数则返回 ?true 。 比较函数的签名应等价于如下: bool cmp(const Type1 &a, const Type2 &b); 虽然签名不必有 const & ,函数也不能修改传递给它的对象,而且必须接受(可为 const 的)类型 Type1 与 Type2的值,无关乎值类别(从而不允许 Type1 & ,亦不允许 Type1 ,除非 Type1 的移动等价于复制 (C++11 起))。 类型 Type1 与 Type2 必须使得 list<T,Allocator>::const_iterator 类型的对象能在解引用后隐式转换到这两个类型。 ? |
4、deque
deque和vector的最大差异:【vector与deque都可以随机读取】
一在于deque允许于常数时间内对起头端进行元素的插入或移除操作,
二在于deque没有所谓容量(capacity)观念,因为它是动态地以分段连续空间组合而成,随时可以增加一段新的空间并链接起来。
- 中控器:
deque是连续空间(至少逻辑上看来如此)。
deque系由一段一段的定量连续空间构成。一旦有必要在deque的前端或尾端增加新空间,便配置一段定量连续空间,串接在整个deque的头端或尾端。
deque的最大任务,便是在这些分段的定量连续空间上,维护其整体连续的假象,并提供随机存取的接口。避开了“重新配置、复制、释放”的轮回,代价则是复杂的迭代器架构。
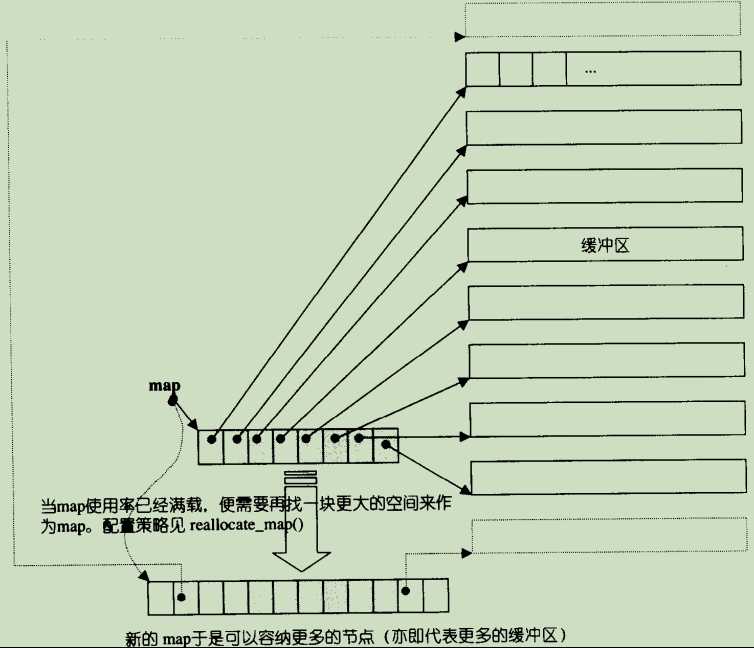
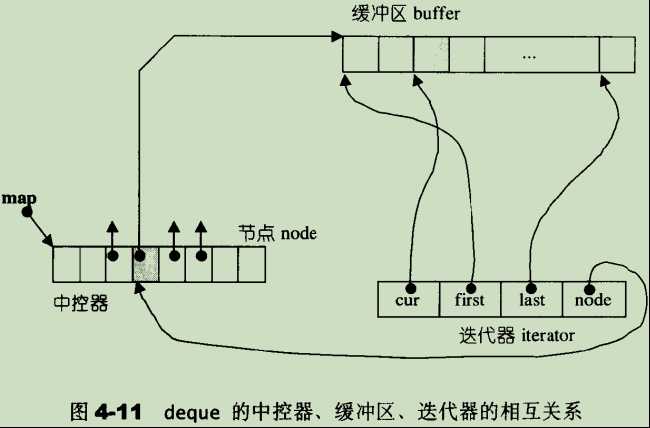
deque采用一块所谓的map(注意,不是STL的map容器)作为主控。这里所谓map是一小块连续空间,其中每个元素(此处称为一个节点,node)都是指针,指向另一段(较大的)连续线性空间,称为缓冲区。缓冲区才是deque的储存空间主体。SGI STL允许我们指定缓冲区大小,默认值0表示将使用512bytes缓冲区。
当map的空间也不够后,会开辟另一个大的map空间
- 迭代器:
deque是分段连续空间。维持其“整体连续”假象的任务,落在了迭代器的operator++和operator--两个运算子身上。
- 数据结构:
- deque 除了维护一个先前说过的指向map的指针外,也维护 start,finish两个迭代器,分别指向第一缓冲区的第一个元素和最后缓冲区的最后一个元素(的下一位置)。此外,它当然也必须记住目前的map大小。因为一旦map所提供的节点不足,就必须重新配置更大的一块map。
- 什么时候map需要重新整治?这个问题的判断由 reserve_map_at_back()和 reserve_map_at_front()进行,实际操作则由reallocate_map()执行;
- 一个deque对象包含四个成员变量,_M_map指向主控器,_M_map_size表示中控器的大小,能够容纳多少个指针,_M_start表示deque的迭代器,所有元素的起始位置,_M_finish表示deque的迭代器,所有元素的终止位置。
- deque的insert()操作:首先判断插入的地方是头或者尾,如果都不是则在调用一个名为insert_aux的辅助函数。此辅助函数通过判断当前的插入位置更靠近头端或者尾端。
- deque的+=操作:首先判断是否在同一级缓冲区区域,如果不在,在确定应该夸几个缓冲区,然后到相应的缓冲区后,再移动
5、stack
- sack定义完整列表
deque是双向开口的数据结构,若以deque为底部结构并封闭其头端开口,便轻而易举地形成了一个stack。因此,SGI STL便以deque作为缺省情况下的stack底部结构,stack的实现因而非常简单,源代码十分简短,
- stack没有迭代器
- 以list作为stack的底层容器
6、queue
- queue定义完整列表
- deque是双向开口的数据结构,若以deque为底部结构并封闭其底端的出口和前端的入口,便轻而易举地形成了一个queue。因此,SGISTL便以deque作为缺省情况下的queue底部结构,queue的实现因而非常简单。
- queue没有迭代器
- 以list作为queue的底层容器
- 优先队列
- priority_queue<Type, Container, Functional>
7、 heap(隐式表述,implicit representation)【堆排序】
- 概念
heap并不归属于STL容器组件,它是个幕后英雄,扮演priority queue
的助手。顾名思义,priority queue允许用户以任何次序将任何元素推入容器内,但取出时一定是从优先权最高(也就是数值最高)的元素开始取。binary max heap正是具有这样的特性,适合作为priority queue的底层机制。
如果使用list作为priority queue的底层机制,元素插入操作可享常数时间。但是要找到list中的极值,却需要对整个list进行线性扫描。我们也可以改变做法,让元素插人前先经过排序这一关,使得list的元素值总是由小到大(或由大到小),但这么一来,收之东隅却失之桑榆:虽然取得极值以及元素删除操作达到最高效率,可元素的插入却只有线性表现。
以binary search tree作为priority queue的底层机制。这么一来,元素的插入和极值的取得就有O(logN)的表现。
但杀鸡用牛刀,未免小题大做,一来binary search tree的输入需要足够的随机性,二来binary search tree并不容易实现。priority queue的复杂度,最好介于queue和binary search tree 之间,才算适得其所。binary heap便是这种条件下的适当候选人。
binary heap就是一种 complete binary tree(完全二叉树)2,也就是说,整棵binary tree除了最底层的叶节点(s)之外,是填满的,而最底层的叶节点(s)由左至右又不得有空隙。【即是一棵完全搜索二叉树】
- heap算法
- push_heap
实现的是堆排序中的插入操作
1 //向上调整 2 void upAdjust(int L, int R) 3 { 4 int i = R, j = (i - 1) / 2;//i为欲调整结点,j为其父亲 5 while (j >= L) 6 { 7 if (v[j] < v[i])//父节点小了,那么就将孩子节点调上来 8 { 9 swap(v[i], v[j]); 10 i = j; 11 j = (i - 1) / 2;//继续向上遍历 12 } 13 else//无需调整 14 break; 15 } 16 } 17 void insert(int x) 18 { 19 v[n] = x;//将新加入的值放置在数组的最后,切记保证数组空间充足 20 upAdjust(0, n);//向上调整新加入的结点n 21 }
- pop_heap
实现的是堆排序的删除操作pop_heap -
1 //向下调整 2 void downAdjust(int L, int R) 3 { 4 int i = L, j = 2 * L + 1;//i为父节点,j为左子节点 5 while (j <= R) 6 { 7 if (j + 1 <= R && v[j + 1] > v[j])//若有右节点,且右节点大,那么就选右节点,即选取最大的子节点与父节点对比 8 ++j;//选取了右节点 9 if (v[j] <= v[i])//孩子节点都比父节点小,满足条件,无需调整 10 break; 11 //不满足的话,那么我就将最大孩子节点j与父节点i对调, 12 swap(v[i], v[j]); 13 i = j; 14 j = 2 * i + 1;//继续向下遍历 15 } 16 } 17 18 //删除堆顶元素 19 20 void deleteTop() 21 { 22 v[0] = v[n - 1];//也就是堆顶使用最后一个数值来替代 23 downAdjust(0, n - 2);//然后对前n-1个数进行排序 24 }
- sort_heap
就是不断的pop出最大的元素sort_heap
实现的就是堆排序
1 for (int i = n - 1; i > 0; --i)//从最后开始交换,直到只剩下最后一个数字 2 { 3 swap(v[i], v[0]);//每次都将最大值放到最后 4 downAdjust(0, i - 1);//将前0-i个数字重新构成大根堆 5 }
- make_heap
实现的是堆排序的构建
1 //建堆 2 void createHeap() 3 { 4 for (int i = n / 2; i >= 0; --i) 5 downAdjust(i, n - 1); 6 }
- heap没有迭代器
8、 priority_queue
- 概念
- priority_queue带有权值观念,其内的元素并非依照被推入的次序排列,而是自动依照元素的权值排列(通常权值以实值表示)。权值最高者,排在最前面。
- 定义
- 由于priority_queue 完全以底部容器为根据,再加上heap处理规则,所以其实现非常简单。缺省情况下是以vector为底部容器。具有这种“修改某物接口,形成另一种风貌”之性质者,称为adapter(配接器),因此,STL priority-queue往往不被归类为container(容器),而被归类为container adapter。
- 没有迭代器
9、slist
- 概述
- STL list是个双向链表(double linked list)。SGI STL另提供了一个单向链表(single linked list),名为slist。
- slist和list的主要差别在于,前者的迭代器属于单向的Forward lerator,后者的迭代器属于双向的Bidirectional lterator。单向链表所耗用的空间更小,某些操作更快,不失为另一种选择。
- 注意,根据STL的习惯,插入操作会将新元素插入于指定位置之前,而非之后。然而作为一个单向链表,slist没有任何方便的办法可以回头定出前一个位置,因此它必须从头找起。换句话说,除了slist起点处附近的区域之外,在其它位置上采用insert或erase操作函数,都属不智之举。这便是slist相较于1ist之下的大缺点。为此,slist 特别提供了insert_after()和erase_after()供灵活运用。
- 迭代器
10、常见错误总结:
迭代器失效:
·由于vector在扩容时,是在一块新地址上开辟空间,然后将原数据复制过来,并把原来的内存空间给释放了,所以一旦vector发生扩容,那么指向原来迭代器将会失效。
·由于list不是连续空间,所以删除和添加都在原的内存上添加或删除一个空间即可,所以指向原来的迭代器不会失效【除非该迭代器指向的位置被删除了】。
·迭代器不仅可以后移,而且可以前进的,--ptr, ++ptr
以上是关于《STL源码剖析》——第四章序列容器的主要内容,如果未能解决你的问题,请参考以下文章