爬取耶鲁大学公开课
Posted y-xp
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取耶鲁大学公开课相关的知识,希望对你有一定的参考价值。
耶鲁大学(Yale University)是一所坐落于美国康涅狄格州纽黑文的私立研究型大学,创于1701年,初名“大学学院”(Collegiate School),是全美历史第三悠久的高等学府,亦为常春藤盟校成员之一。该校教授阵容、学术创新、课程设置和场馆设施等方面堪称一流。除了研究生课程之外,耶鲁同时也非常注重本科生教育。在各个大学排名榜单中,都一直名列前茅。
所以,我们今天的目标是爬取耶鲁大学公开课信息,并将它们加以保存。
首先,我们打开耶鲁大学公开课的首页进行分析。可以看到,在表格中有着许多课程,这就是我们要爬取其中之一。。
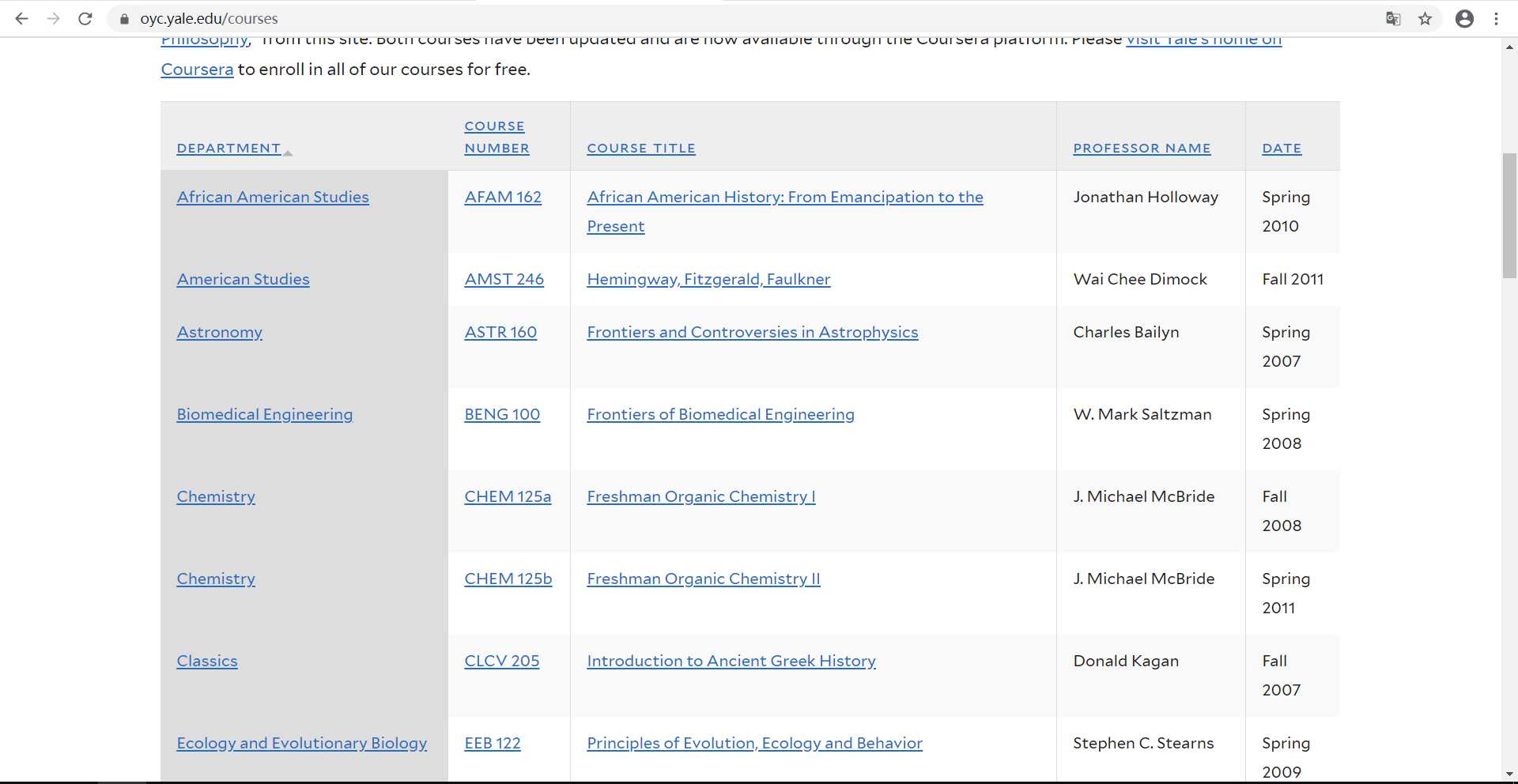
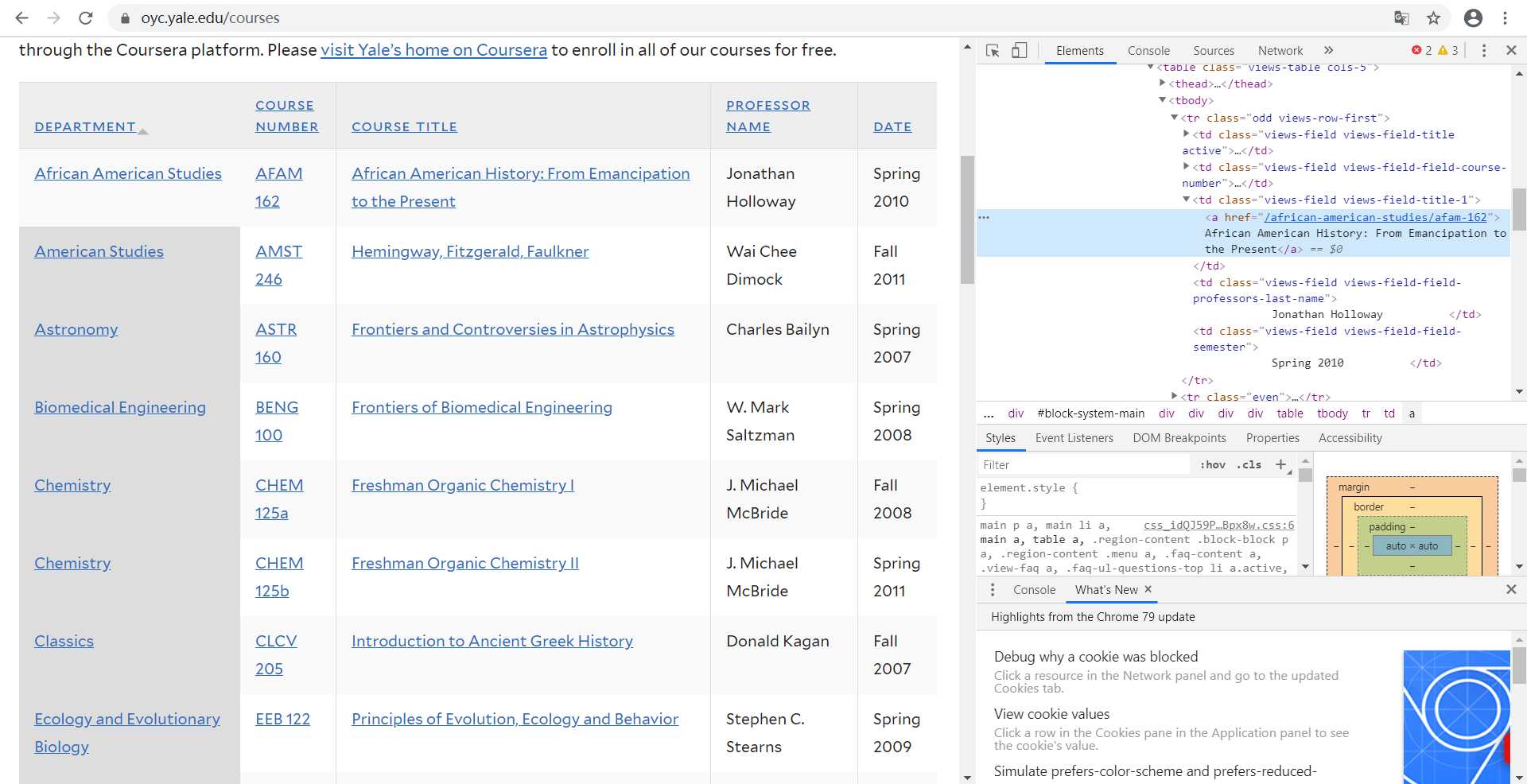
然后点击“检查”,查看这些信息在网页中的位置以及属性。
现在进入课程页面,点击一门课程,可以看到课程的详细信息,包括课程名称,课程描述等信息。
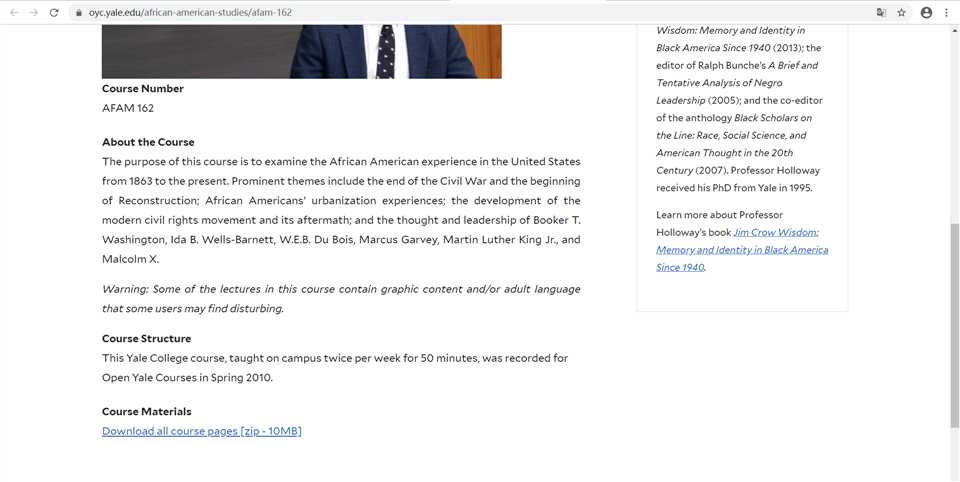
同样的,我们也要得到它们的属性
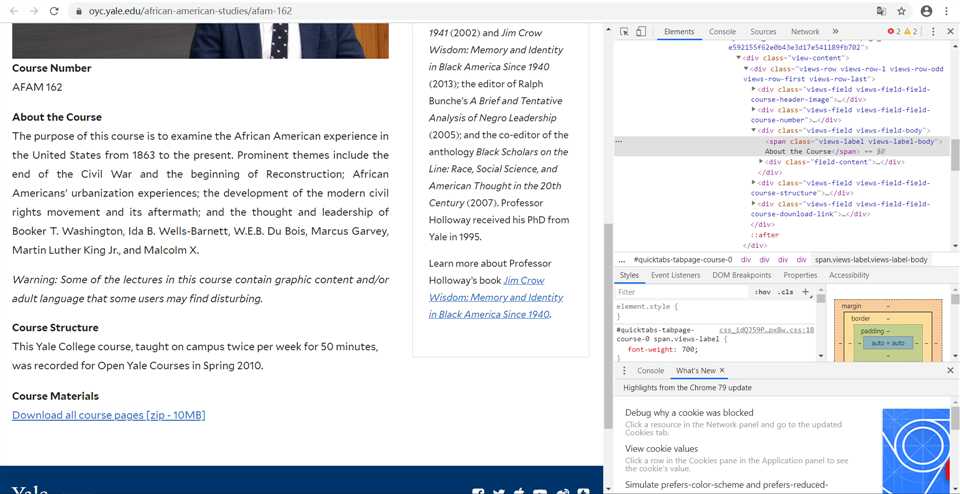
最后,在确定我们要爬取的信息的属性之后,我们就可以编写代码进行爬取了。
在爬取之前,我们先确定思路:
1、爬取首页中所有课程中的URL并保存。
2、然后根据爬取到的URL,分别爬取课程的详细信息并保存。
3、在爬取所有的课程信息之后,将爬取的课程信息保存为csv文件保存在本地
首先我们编写爬取首页的代码:
# 获取列表中的URL def getDetailsUrl(url): # 爬取列表中课程类别和子链接到列表中 r = requests.get(url) r.encoding = ‘utf8‘ soup = BeautifulSoup(r.text, ‘lxml‘) # 获取课程类别 depa = soup.find_all(‘td‘, {‘class‘: ‘views-field views-field-title active‘}) for i in depa: # 课程标题 m = i.text Course_Title.append(m.replace(‘ ‘, ‘‘)) # 课程类别 n = i.find(‘a‘) Department.append(n.text) # 获取课程子连接 link = soup.find_all(‘td‘, {‘class‘: ‘views-field views-field-title-1‘}) for i in link: # 课程子链接 n = i.find(‘a‘) ListUrl.append(n[‘href‘])
然后,我们开始编写爬取课程信息代码:
经过分析,所有的课程界面的网页结构都是相同的,所以我们可以利用同一个函数来进行爬取,而且所有的课程链接组成为:https://oyc.yale.edu+课程子链接
# 获取子网页中的内容 def getText(): # 页数 page = 1 for i in range(len(ListUrl)): url = ‘https://oyc.yale.edu‘ + ListUrl[i] print(‘第{}个链接:{}‘.format(page, url)) page = page + 1 r = requests.get(url) r.encoding = ‘utf8‘ soup = BeautifulSoup(r.text, ‘lxml‘) # 课程编号 aa = soup.find(‘div‘, {‘class‘: ‘views-field views-field-field-course-number‘}).find(‘div‘, { ‘class‘: ‘field-content‘}).text aa.replace(‘ ‘, ‘‘).replace(‘,‘, ‘.‘) Course_Number.append(aa) # 关于课程 bb = soup.find(‘div‘, {‘class‘: ‘views-field views-field-body‘}).find(‘div‘, {‘class‘: ‘field-content‘}).text bb.replace(‘ ‘, ‘‘).replace(‘,‘, ‘.‘) About_the_Course.append(bb) # 课程结构 cc = soup.find(‘div‘, {‘class‘: ‘views-field views-field-field-course-structure‘}).find(‘div‘, { ‘class‘: ‘field-content‘}).text cc.replace(‘ ‘, ‘‘).replace(‘,‘, ‘.‘) Course_Structure.append(cc) # 讲课教授 dd = soup.find(‘div‘, {‘class‘: ‘views-field views-field-field-professor-name‘}).find(‘div‘, { ‘class‘: ‘field-content‘}).text dd.replace(‘ ‘, ‘‘).replace(‘,‘, ‘.‘) Professor.append(dd) # 课程描述 ee = soup.find(‘div‘, {‘class‘: ‘views-field views-field-body‘}).find(‘div‘, {‘class‘: ‘field-content‘}).text ee.replace(‘ ‘, ‘‘).replace(‘,‘, ‘.‘) Description.append(ee) # 课程资料 ff = soup.find(‘div‘, {‘class‘: ‘views-field views-field-field-syllabus-texts‘}).find(‘div‘, { ‘class‘: ‘field-content‘}).text ff.replace(‘ ‘, ‘‘).replace(‘,‘, ‘.‘) Texts.append(ff) # 随机暂停,防止被封 time.sleep(random.randint(1, 6))
在爬取完课程信息后,我们就可以将这些信息进行保存:
# CSV标题 l = [‘Department‘, ‘Course_Number‘, ‘Course_Title‘, ‘About_the_Course‘, ‘Course_Structure‘, ‘Professor‘, ‘Description‘, ‘Texts ‘] choose = 1 for i in range(len(ListUrl)): all = [Department[i], Course_Number[i], Course_Title[i], About_the_Course[i], Course_Structure[i], Professor[i], Description[i], Texts[i]] with open(‘123.csv‘, ‘a+‘, newline=‘‘, encoding=‘uft8‘) as csvfile: writer = csv.writer(csvfile) if choose == 1: writer.writerow(l) choose = 10 writer.writerow(all)
最后,我们将这些代码结合起来,加入首页的URL,组合成为一个项目。
运行程序后,可以得到一个csv文件,如下
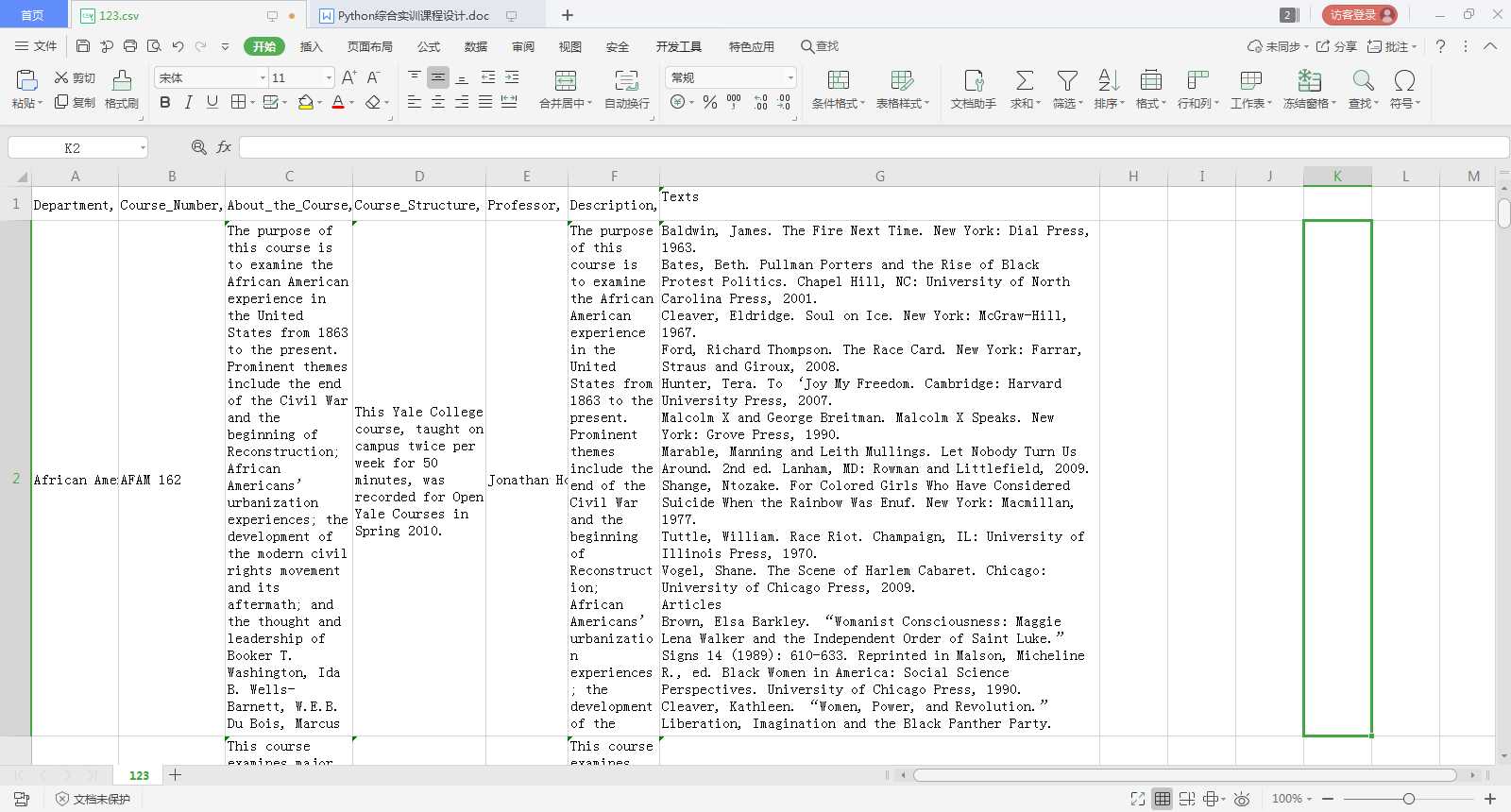
打开csv文件,就可以看到所爬取到的课程信息了,如下图所示:
完整程序代码如下:
import csv import time import random import requests from bs4 import BeautifulSoup all = [] # 转存数据 Department = [] # 课程类别 Course_Title = [] # 课程名称 ListUrl = [] # 课程子链接 Course_Number = [] # 课程编号 About_the_Course = [] # 关于课程 Course_Structure = [] # 课程结构 Professor = [] # 讲课教授 Description = [] # 课程描述 Texts = [] # 相关资料 # 获取列表中的URL def getDetailsUrl(url): # 爬取列表中课程类别和子链接到列表中 r = requests.get(url) r.encoding = ‘utf8‘ soup = BeautifulSoup(r.text, ‘lxml‘) # 获取课程类别 depa = soup.find_all(‘td‘, {‘class‘: ‘views-field views-field-title active‘}) for i in depa: # 课程标题 m = i.text Course_Title.append(m.replace(‘ ‘, ‘‘)) # 课程类别 n = i.find(‘a‘) Department.append(n.text) # 获取课程子连接 link = soup.find_all(‘td‘, {‘class‘: ‘views-field views-field-title-1‘}) for i in link: # 课程子链接 n = i.find(‘a‘) ListUrl.append(n[‘href‘]) # 获取子网页中的内容 def getText(): # 页数 page = 1 for i in range(len(ListUrl)): url = ‘https://oyc.yale.edu‘ + ListUrl[i] print(‘第{}个链接:{}‘.format(page, url)) page = page + 1 r = requests.get(url) r.encoding = ‘utf8‘ soup = BeautifulSoup(r.text, ‘lxml‘) # 课程编号 aa = soup.find(‘div‘, {‘class‘: ‘views-field views-field-field-course-number‘}).find(‘div‘, { ‘class‘: ‘field-content‘}).text aa.replace(‘ ‘, ‘‘).replace(‘,‘, ‘.‘) Course_Number.append(aa) # 关于课程 bb = soup.find(‘div‘, {‘class‘: ‘views-field views-field-body‘}).find(‘div‘, {‘class‘: ‘field-content‘}).text bb.replace(‘ ‘, ‘‘).replace(‘,‘, ‘.‘) About_the_Course.append(bb) # 课程结构 cc = soup.find(‘div‘, {‘class‘: ‘views-field views-field-field-course-structure‘}).find(‘div‘, { ‘class‘: ‘field-content‘}).text cc.replace(‘ ‘, ‘‘).replace(‘,‘, ‘.‘) Course_Structure.append(cc) # 讲课教授 dd = soup.find(‘div‘, {‘class‘: ‘views-field views-field-field-professor-name‘}).find(‘div‘, { ‘class‘: ‘field-content‘}).text dd.replace(‘ ‘, ‘‘).replace(‘,‘, ‘.‘) Professor.append(dd) # 课程描述 ee = soup.find(‘div‘, {‘class‘: ‘views-field views-field-body‘}).find(‘div‘, {‘class‘: ‘field-content‘}).text ee.replace(‘ ‘, ‘‘).replace(‘,‘, ‘.‘) Description.append(ee) # 课程资料 ff = soup.find(‘div‘, {‘class‘: ‘views-field views-field-field-syllabus-texts‘}).find(‘div‘, { ‘class‘: ‘field-content‘}).text ff.replace(‘ ‘, ‘‘).replace(‘,‘, ‘.‘) Texts.append(ff) # 随机暂停,防止被封 time.sleep(random.randint(1, 6)) if __name__ == ‘__main__‘: url = ‘https://oyc.yale.edu/courses‘ getDetailsUrl(url) getText() # CSV标题 l = [‘Department‘, ‘Course_Number‘, ‘Course_Title‘, ‘About_the_Course‘, ‘Course_Structure‘, ‘Professor‘, ‘Description‘, ‘Texts ‘] choose = 1 for i in range(len(ListUrl)): all = [Department[i], Course_Number[i], Course_Title[i], About_the_Course[i], Course_Structure[i], Professor[i], Description[i], Texts[i]] with open(‘123.csv‘, ‘a+‘, newline=‘‘, encoding=‘uft8‘) as csvfile: writer = csv.writer(csvfile) if choose == 1: writer.writerow(l) choose = 10 writer.writerow(all)
以上是关于爬取耶鲁大学公开课的主要内容,如果未能解决你的问题,请参考以下文章
斯坦福大学公开课:iPad和iPhone应用开发(iOS5) 学习笔记 2