12. Go 语言文件处理
Posted kershaw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了12. Go 语言文件处理相关的知识,希望对你有一定的参考价值。
Go 语言文件处理
本章我们将带领大家深入了解一下 Go语言中的文件处理,重点在于文件而非目录或者通用的文件系统,特别是如何读写标准格式(如 XML 和 JSON 格式)的文件以及自定义的纯文本和二进制格式文件。
由于前面的内容已覆盖 Go语言的所有特性,现在我们可以灵活地使用 Go语言提供的所有工具。我们会充分利用这种灵活性并利用闭包来避免重复性的代码,同时在某些情况下充分利用 Go语言对面向对象的支持,特别是对为函数添加方法的支持。
Go语言自定义数据文件
对一个程序非常普遍的需求包括维护内部数据结构,为数据交换提供导入导出功能,也支持使用外部工具来处理数据。
由于我们这里的关注重点是文件处理,因此我们纯粹只关心如何从程序内部数据结构中读取数据并将其写入标准和自定义格式的文件中,以及如何从标准和自定义格式文件中读取数据并写入程序的内部数据结构中。
本节中,我们会为所有的例子使用相同的数据,以便直接比较不同的文件格式。所有的代码都来自 invoicedate 程序(在 invoicedata 目录中的 invoicedata.go > gob.go、inv.go、jsn.go、txt.go 和 xml.go 等文件中)。大家可以从我的网盘(链接: https://pan.baidu.com/s/1j22QfIScihrauVCVFV6MWw 提取码: ajrk)下载相关的代码。
该程序接受两个文件名作为命令行参数,一个用于读,另一个用于写(它们必须是不同的文件)。程序从第一个文件中读取数据(以其后缀所表示的任何格式),并将数据写入第二个文件(也是以其后缀所表示的任何格式)。
由 invoicedata 程序创建的文件可跨平台使用,也就是说,无论是什么格式,Windows 上创建的文件都可在 Mac OS X 以及 Linux 上读取,反之亦然。Gzip 格式压缩的文件(如 invoices.gob.gz)可以无缝读写。
这些数据由一个 []invoice 组成,也就是说,是一个保存了指向 Invoice 值的指针的切片。每一个发票数据都保存在一个 invoice 类型的值中,同时每一个发票数据都以 []*Item 的形式保存着 0 个或者多个项。
type Invoice struct {
Id int
Customerld int
Raised time.Time
Due time.Time
Paid bool
Note string
Items []*Item
}
type Item struct {
Id st ring
Price float64
Quantity int
Note string
}这两个结构体用于保存数据。下表给出了一些非正式的对比,展示了每种格式下读写相同的 50000 份随机发票数据所需的时间,以及以该格式所存储文件的大小。
计时按秒计,并向上舍入到最近的十分之一秒。我们应该把计时结果认为是无绝对单位的,因为不同硬件以及不 同负载情况下该值都不尽相同。大小一栏以千字节(KB)算,该值在所有机器上应该都是相同的。
对于该数据集,虽然未压缩文件的大小千差万别,但压缩文件的大小都惊人的相似。而代码的 函数不包括所有格式通用的代码(例如,那些用于压缩和解压缩以及定义结构体的代码)。
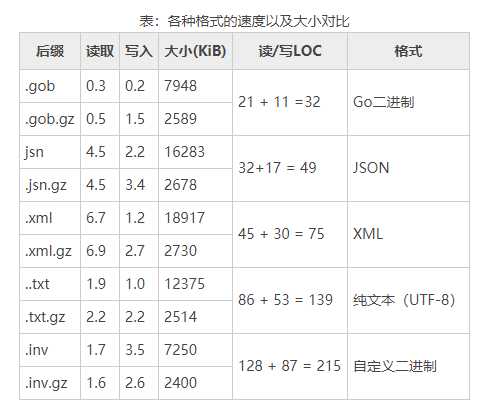
这些读写时间和文件大小在我们的合理预期范围内,除了纯文本格式的读写异常快之外。这得益于 fmt 包优秀的打印和扫描函数,以及我们设计的易于解析的自定义文本格式。
对于 JSON 和 XML 格式,我们只简单地存储了日期部分而非存储默认的 time.Time 值(一个 ISO-8601 日期/时间字符串),通过牺牲一些速度和增加一些额外代码稍微减小了文件的大小。
例如,如果让JSON代码自己来处理time.Time值,它能够运行得更快,并且其代码行数与 Go语言二进制编码差不多。
对于二进制数据,Go语言的二进制格式是最便于使用的。它非常快且极端紧凑,所需的代码非常少,并且相对容易适应数据的变化。然而,如果我们使用的自定义类型不原生支持 gob 编码,我们必须让该类型满足 gob.Encoder 和 gob. Decoder 接口,这样会导致 gob 格式的 读写相当得慢,并且文件大小也会膨胀。
对于可读的数据,XML 可能是最好使用的格式,特别是作为一种数据交换格式时非常有用。与处理 JSON 格式相比,处理 XML 格式需要更多行代码。这是因为 Go [没有一个 xml.Marshaler 接口,也因为我们这里使用了并行的数据类型 (XMLInvoice 和 XMLItem)来帮助映射 XML 数据和发票数据(invoice 和 Item)。
使用 XML 作为外部存储格式的应用程序可能不需要并行的数据类型或者也不需要 invoicedata 程序这样的 转换,因此就有可能比 invoicedata 例子中所给出的更快,并且所需的代码也更少。
除了读写速度和文件大小以及代码行数之外,还有另一个问题值得考虑:格式的稳健性。例如,如果我们为 Invoice 结构体和 Item 结构体添加了一个字段,那么就必须再改变文件的格式。我们的代码适应读写新格式并继续支持读旧格式的难易程度如何?如果我们为文件格式定义版本,这样的变化就很容易被适应(会以本章一个练习的形式给岀),除了让 JSON 格式同时适应读写新旧格式稍微复杂一点之外。
除了 Invoice 和 Item 结构体之外,所有文件格式都共享以下常量:
const (
fileType = "INVOICES" //用于纯文本格式
magicNumber = 0xl25D // 用于二进制格式
fileVersion = 100 //用于所有的格式
dataFormat = "2006-01-02" //必须总是使用该日期
)magicNumber 用于唯一标记发票文件。fileVersion 用于标记发票文件的版本,该标记便于之后修改程序来适应数据格式的改变。dataFormat 稍后介绍,它表 示我们希望数据如何按照可读的格式进行格式化。
同时,我们也创建了一对接口。
type InvoiceMarshaler interface {
Marshallnvoices(writer io.Writer, invoices []*Invoice) error
}
type InvoiceUnmarshaler interface {
Unmarshallnvoices(reader io.Reader) ([]*Invoice, error)
}这样做的目的是以统一的方式针对特定格式使用 reader 和 writer。例如,下列函数是 invoicedata 程序用来从一个打开的文件中读取发票数据的。
func readinvoices(reader io.Reader, suffix string)([]*Invoice, error) {
var unmarshaler InvoicesUnmarshaler
switch suffix {
case ".gobn:
unmarshaler = GobMarshaler{}
case H.inv":
unmarshaler = InvMarshaler{}
case ,f. jsn", H. jsonn:
unmarshaler = JSONMarshaler{}
case ".txt”:
unmarshaler = TxtMarshaler{}
case ".xml":
unmarshaler = XMLMarshaler{}
}
if unmarshaler != nil {
return unmarshaler.Unmarshallnvoices(reader)
}
return nil, fmt.Errorf("unrecognized input suffix: %s", suffix)
}其中,reader 是任何能够满足 io.Reader 接口的值,例如,一个打开的文件 ( 其类型为 os . File)> 一个 gzip 解码器 ( 其类型为 gzip. Reader) 或者一个 string. Readero 字符串 suffix 是文件的后缀名 ( 从 .gz 文件中解压之后)。
在接下来的小节中我们将会看到 GobMarshaler 和 InvMarshaler 等自定义的类型,它们提供了 MarshmlTnvoices() 和 Unmarshallnvoices() 方法 (因此满足 InvoicesMarshaler 和 InvoicesUnmarshaler 接口)。
Go语言JSON文件的读写操作
根据 www.json.org 介绍,JSON (javascript 对象表示法,JavaScript Object Notation) 是一种易于人读写并且易于机器解析和生成的轻量级的数据交换格式。
JSON 是一种使用 UTF-8 编码的纯文本格式。由于写起来比 XML 格式方便,并且(通常)更为紧凑,而所需的处理时间也更少,JSON 格式已经越来越流行,特别是在通过网络连接传送数据方面。
这里是一个简单的发票数据的 JSON 表示,但是它省略了该发票的第二项的大部分字段。
{
"Id": 4461,
"Customerld": 917,
"Raised": ”2012-07-22”,
"Due": "2012-08-21”,
"Paid": true,
"Note": "Use trade ent rance",
"Items":[
{
"Id": "AM2574",
"Price": 415.8,
"Quantity": 5,
"Note": ""
},
{
"Id": "MI7296",
...
}
]
}通常,encodeing/json 包所写的 JSON 数据没有任何不必要的空格,但是这里我们为了更容易看明白数据的结构而使用了缩进和空白来展示它。虽然 encoding/json 包支持 time.Times,但是我们通过自己实现自定义的 MarshalJSON() 和 UnmarshalJSON() Invoice 方法来处理发票的开具和到期日期。
这样我们就可以存储更短的日期字符串 ( 因为对于我们的数据来说,其时间部分始终为 0),例如“2012-09-06”,而非整个日期/时间值,如 "2012-09-06T00:00:00Z"。
写 JSON 文件
我们创建了一个基于空结构体的类型,它定义了与 JSON 相关的 Marshallnvoices() 和 UnmarshalInvoices() 方法。
type JSONMarshaler struct{}该类型满足我们在前文看到的 InvoicesMarshaler 和 InvoicesUnmarshaler 接口。
这里的方法使用 encoding/json 包中标准的 Go 到 JSON 序列化函数将 []Invoice 项中的所有数据以 JSON 格式写入一个 io.Writer 中。该 writer 可以是 os.Create() 函数返回的 os.File,或者是 gzip.NewWriter() 函数返回的 *gzip.Writer,或者是任何满足 io.Writer 接口的其他值。
func (JSONMarshaler) Marshallnvoices(writer io.Writer, invoices []*Invoice) error {
encoder := j son.NewEncoder(writer)
if err := encoder.Encode(fileType); err != nil {
return err
}
if err := encoder.Encode(fileVersion); err != nil {
return err
}
return encoder.Encode(invoices)
}JSONMarshaler 类型没有数据,因此我们没必要将其值赋值给一个接收器变量。
函数开始处,我们创建了一个 JSON 编码器,它包装了 io.Writer,可以接收我们写入的支持 JSON 编码的数据。
我们使用 json.Encoder.Encode() 方法来写入数据。该方法能够完美地处理发票切片,其中每个发票都包含一到多个项的切片。该方法返回一个错误值或者空值 nil。如果返回的是一个错误值,则立即返回给调用者。
文件的类型和版本不是必须写入的,但在后面一个练习中会看到,这样做是为了以后更容易更改文件格式 (例如,为了适应 Invoice 和 Item 结构体中额外的字段 ),以及为了能够同时支持读取新旧格式的数据。
需注意的是,该方法实际上与它所编码的数据类型无关,因此很容易创建类似函数用于写入其他可 JSON 编码的数据。另外,只要新的文件格式中新增的字段是导出的且支持 JSON 编码,该 JSONMarshaler.Marshallnvoices() 方法无需做任何更改。
如果这里所给出的代码就是 JSON 相关代码的全部,这样当然可以很好地工作。然而,由于我们希望更好地控制 JSON 的输出,特别是对 time.Time 值的格式化,我们还为 Invoice 类型提供了一个满足 json.Marshaler 接口的 MarshalJSON() 方法。
json.Encode() 函数足够智能,它会去检查所需编码的值是否支持 json.Marshaler 接口,如果支持,该函数会使用该值的 MarshalJSON() 方法而非内置的编码代码。
type JSONInvoice struct {
Id int
CustomerId int
Raised st ring // Invoice 结构体中的 time.Time
Due string // Invoice 结构体中的 time.Time
Paid bool
Note string
Items []*Item
}
func (invoice Invoice) MarshalJSON()([]byte, error) {
jsonlnvoice := JSONInvoice {
invoice.Id,
invoice.Customerld,
invoice.Raised.Format(dateFormat),
invoice.Due.Format(dateFormat),
invoice.Paid,
invoice.Note,
invoice.Items,
}
return json.Marshal(jsonlnvoice)
}该自定义的 Invoice.MarshalJSON() 方法接受一个已有的 Invoice 值,返回一个该数据 JSON 编码后的版本。该函数的第一个语句简单地将发票的各个字段复制到自定义的 JSONInvoice 结构体中,同时将两个 time.Time 值转换成字符串。
由于 JSONInvoice 结构体的字段都是布尔类型、数字或者字符串,该结构体可以使用 json.Marshal() 函数进行编码,因此我们使用该函数来完成工作。
为了将日期/时间 ( 即 time.Time 值 ) 以字符串的形式写入,我们必须使用 time.Time.Format() 方法。该方法接受一个格式字符串,它表示该日期/时间值应该如何写入。
该格式字符串非常特殊,必须是一个 Unix 时间 1 136 243 045 的字符串表示,即精确的日期/时间值 2006-01-02T15:04:05Z07:00,或者跟这里一样,使用该日期/时间值的子集。该特殊的日期/时间值是任意的,但必须是确定的,因为没有其他的值来声明日期、时间以及日期/时间的格式。
如果我们想自定义日期/时间格式,它们必须按照 Go语言的日期/时间格式来写。假如我们要以星期、月、日和年的形式来写日期,我们必须使用“Mon, Jan 02, 2006”这种格式,或者如果我们希望删除前导的 0,就必须使用"Mon, Jan _2, 2006”这种格式。time 包的文档中有完整的描述,并列出了一些预定义的格式字符串。
读 JSON 文件
读 JSON 数据与写 JSON 数据一样简单,特别是当将数据读回与写数据时类型一样的变量时。JSONMarshaler.UnMarshallnvoices() 方法接受一个 io.Reader 值,该值可以是一个 os.Open() 函数返回的 os.File 值,或者是一个 gzip.NewReader() 函数返回的 gzip.Reader 值,也可以是任何满足 io.Reader 接口的值。
func (JSONMarshaler) Unmarshallnvoices(reader io.Reader) ([]*Invoice, error){
decoder := json.NewDecoder(reader)
var kind string
if err := decoder.Decode(&king); err != nil {
return nil, err
}
if kind != fileType {
return nil, errors.New ("Cannot read non-invoices json file")
}
var version int
if err := decoder.Decode(&version); err != nil {
return nil, err
}
if version > fileVersion {
return nil, fmt.Error("version %d is too new to read", version)
}
var invoices []*Invoice
err := decoder.Decode(&invoices)
return invoices, err
}我们需读入 3 项数据:文件类型、文件版本以及完整的发票数据。json.Decoder.Decode() 方法接受一个指针,该指针所指向的值用于存储解码后的 JSON 数据,解码后返回一个错误值或者 nil。
我们使用前两个变量 (kind 和 version) 来保证接受一个 JSON 格式的发票文件,并且该文件的版本是我们能够处理的。然后程序读取发票数据,在该过程中,随着 json.Decoder.Decode() 方法所读取发票数的增多,它会增加 invoices 切片的长度,并将相应发票的指针 ( 及其项目 ) 保存在切片中,这些指针是 Unmarshallnvoices 函数在必要时实时创建的。最后,该方法返回解码后的发票数据和一个 nil 值。或者,如果解码过程中遇到了问题则返回一个 nil 值和一个错误值。
如果我们之前纯粹依赖于 json 包内置的功能把数据的创建及到期日期按照默认的方式序列化,那么这里给出的代码已经足以反序列化一个 JSON 格式的发票文件。然而,由于我们使用自定义的方式来序列化数据的建立和到期日期 time.Times (只存储日期部分 ),我们必须提供一个自定义的反序列化方法,该方法理解我们的自定义序列化流程。
func (invoice *Invoice) UnmarshalJSON(data []byte) (err error) {
var jsonlnvoice JSONInvoice
if err = json.Unmarshal(data, &jsonlnvoice); err != nil {
return err
}
var raised, due time.Time
if raised, err = time.Parse(dateFormat, jsonlnvoice.Raised);
err != nil {
return err
}
if due, err = time.Parse(dateFormat, jsonlnvoice.Due); err != nil {
return err
}
*invoice = Invoice {
jsonlnvoice.Id,
jsonlnvoice.Customerld,
raised,
due,
jsonlnvoice.Paid,
jsonlnvoice.Note,
jsonlnvoice.Items,
}
return nil
}该方法使用与前面一样的 JSONInvoice 结构体,并且依赖于 json.Unmarshal() 函数来填充数据。然后,我们将反序列化后的数据以及转换成 time.Time 的日期值赋给新创建的 Invoice 变量。
json.Decoder.Decode() 足够智能会检查它需要解码的值是否满足 json.Unmarshaler 接口,如果满足则使用该值自己的 UnmarshalJSON() 方法。
如果发票数据因为新添加了导出字段而发生改变,该方法能继续正常工作的前提是我们必须让 Invoice.UnmarshalJSON() 方法也能处理版本变化。另外,如果新添加字段的零值不可被接受,那么当以原始格式读文件的时候,我们必须对数据做一些后期处理,并给它们一个合理的值。
虽然要支持两个或者更多个版本的 JSON 文件格式有点麻烦,但 JSON 是一种很容易处理的格式,特别是如果我们创建的结构体的导出字段比较合理时。同时,json.Encoder.Encode() 函数和 json.Decoder.Decode() 函数也不是完美可逆的,这意味着序列化后得到的数据经过反序列化后不一定能够得到原始的数据。因此,我们必须小心检查,保证它们对我们的数据有效。
顺便提一下,还有一种叫做 BSON (Binary JSON) 的格式与 JSON 非常类似,它比 JSON 更为紧凑,并且读写速度也更快。godashboard.appspot.com/project 网页上有一个支持 BSON 格式的第三方包 (gobson)。
Go语言XML文件的读写操作
XML(extensible Markup Language) 格式被广泛用作一种数据交换格式,并且自成一种文件格式。与 JSON 相比,XML 复杂得多,手动写起来也啰嗦而且乏味得多。
encoding/xml 包可以用在结构体和 XML 格式之间进行编解码,其方式跟 encoding/json 包类似。然而,与 encoding/json 包相比,XML 的编码和解码在功能上更苛刻得多。这部分是由于 encoding/xml 包要求结构体的字段包含格式合理的标签(然而 JSON 格式却不需要)。
同时,Go 1 的 encoding/xml 包没有 xml.Marshaler 接口,因此与编解码 JSON 格式和 Go语言的二进制格式相比,我们处理 XML 格式时必须写更多的代码。(该问题有望在 Go 1.x 发行版中得以解决。)
这里有个简单的 XML 格式的发票文件。为了适应页面的宽度和容易阅读,我们添加了换行和额外的空白。
<INVOICE Id="2640" CustomerId="968" Raised="2012-08-27" DUe="2012-09-26" Paid="false"><NOTE>See special Terms & Conditions</NOTE>
<ITEM Id="MI2419" Price="342.80" Quantity="1"><NOTE></NOTE></ITEM>
<ITEM Id="OU5941" Price="448.99" Quantity="3"><N0TE>
"Blue" ordered but will accept "Navy"</NOTE> </ITEM>
<ITEM Id="IF9284" Price="475.01" Quantity="1"><NOTE></NOTE></ITEM>
<ITEM Id="TI4394" Price="417.79" Quantity="2"><N0TE></N0TE></ITEM>
<ITEM Id="VG4325" Price="80.67" Quantity= "5"><NOTE></NOTE></ITEM>
</INVOICE>对于 xml 包中的编码器和解码器而言,标签中如果包含原始字符数据 ( 如 invoice 和 item 中的 Note 字段 ) 处理起来比较麻烦,因此 invoicedata 示例使用了显式的
写 XML 文件
encoidng/xml 包要求我们使用的结构体中的字段包含 encoding/xml 包中所声明的标签,所以我们不能直接将 Invoice 和 Item 结构体用于 XML 序列化。
因此,我们创建了针对 XML 格式的 XMLInvoices、XMLInvoice 和 XMLItem 结构体来解决这个问题。同时,由于 invoicedata 程序要求我们有并行的结构体集合,因此必须提供一种方式来让它们相互转换。
当然,使用 XML 格式作为主要存储格式的应用程序只需一个结构体(或者一个结构体集合),同时要将必要的 encoidng/xml 包的标签直接添加到结构体的字段中。
下面是保存整个数据集合的 XMLInvoices 结构体。
type XMLInvoices struct {
XMLName xml.Name 'xml:"INVOICES"'
Version int 'xml:"version, attr"'
Invoice []*XMLInvoice 'xml:"INVOICE"'
}在 Go语言中,结构体的标签本质上没有任何语义,它们只是可以使用 Go语言的反射接口获得的字符串。然而,encoding/xml 包要求我们使用该标签来提供如何将结构体的字段映射到 XML 的信息。
xml.Name 字段用于为 XML 中的标签命名,该标签包含了该字段所在的结构体。以 ‘xml:",attr"‘ 标记的字段将成为该标签的属性,字段名字将成为属性名。我们也可以根据自己的喜好使用另一个名字,只需在所给的名字签名加上一个逗号。
这里,我们把 Version 字段当做一个叫做 version 的属性,而非默认的名字 Version。如果标签只包含一个名字,则该名字用于表示嵌套的标签,如此例中的 <TNVOTCE> 标签。有一个非常重要的细节需注意的是,我们把 XMLInvoices 的发票字段命名为 Invoice,而非 Invoices,这是为了匹配 XML 格式中的标签名(不区分大小写)。
下面是原始的 Invoice 结构体,以及与 XML 格式相对应的 XMLInvoice 结构体。
type Invoice struct {
Id int
Customerld int
Raised time.Time
Due time.Time
Paid bool
Note string
Items []*1tem
}
type XMLInvoice struct {
XMLName xml.Name 'xml: "INVOICE"'
Id int 'xml:",attr"'
CustomerId int 'xml:",attr"'
Raised string 'xml:",attr"'
Due string 'xml:",attr"'
Paid bool 'xml:",attr"'
Note string 'xml:"NOTE"'
Item []*XMLItem 'xml:"ITEM"'
}在这里,我们为属性提供了默认的名字。例如,字段 Customerld 在 XML 中对应一个属性,其名字与该字段的名字完全一样。这里有两个可嵌套的标签:<NOTE>和<ITEM>,并且如 XMLInvoices 结构体一样,我们把 XMLInvoice 的 item 字段定义成 Item(大小写不敏感)而非 Items,以匹配标签名。
由于我们希望自己处理创建和到期日期(只存储日期),而非让 encoding/xml 包来保存完整的日期/时间字符串,我们为它们在 XMLInvoice 结构体中定义了相应的 Raised 和 Due 字段。
下面是原始的 Item 结构体,以及与 XML 相对应的 XMLItem 结构体。
type Item struct {
Id string
Price float64
Quantity int
Note string
}
type XMLItem struct {
XMLName xml.Name 'xml:"ITEM"'
Id string 'xml:",attr"'
Price float64 'xml:",attr"'
Quantity int 'xml:",attr"'
Note string 'xml:"NOTE"'
}除了作为嵌套的 <NOTE> 标签的 Note 字段和用于保存该 XML 标签名的 XMLName 字段之外,XMLItem 的字段都被打上了标签以作为属性。
正如处理 JSON 格式时所做的那样,对于 XML 格式,我们创建了一个空的结构体并关联了 XML 相关的 MarshalInvoices() 方法和 UnmarshalInvoices() 方法。
type XMLMarshaler struct{}该类型满足前文所述的 InvoicesMarshaler 和 InvoiceUnmarshaler 接口。
func (XMLMarshaler) Marshallnvoices(writer io.Writer, invoices []*Invoice) error {
if err := writer.Writer([]byte(xml.Header)); err != nil {
return err
}
xmlinvoices := XMLInvoicesForInvoices(invoices)
encoder := xml.NewEncoder(writer)
return encoder.Encode(xmlinvoices)
}该方法接受一个 io.Writer (也就是说,任何满足 io.Writer 接口的值如打开的文件或者打开的压缩文件),以用于写入 XML 数据。该方法从写入标准的 XML 头部开始 ( 该 xml.Header 常量的末尾包含一个新行)。
然后,它将所有的发票数据及其项写入相应的 XML 结构体中。这样做虽然看起来会耗费与原始数据相同的内存,但是由于 Go语言的字符串是不可变的,因此在底层只将原始数据字符串的引用复制到 XML 结构体中,因此其代价并不是我们所看到的那么大。而对于直接使用带有 XML 标签的结构体的应用而言,其数据没必要再次转换。
一旦填充好 xmlInvoices( 其类型为 XMLInvoices) 后,我们创建了一个新的 xml.Encoder,并将我们希望写入数据的 io.Writer 传给它。然后,我们将数据编码成 XML 格式,并返回编码器的返回值,该值可能为一个 error 值也可能为 nil。
func XMLInvoicesForlnvoices(invoices []*Invoice) *XMLInvoices {
xmlinvoices :=? &XMLInvoices{
Version: fileVersion,
Invoice: make([]*XMLInvoice, 0, len(invoices)),
}
for _, invoice := range invoices {
xmlInvoices.Invoice = append(xmlinvoices.Invoice,
XMLInvoiceForInvoice (invoice))
}
return xmlInvoices
}该函数接受一个 []*Invoice 值并返回一个 *XMLInvoices 值,其中包含转换成 *XMLInvoices(还包含 *XMLItems 而非 *Items) 的所有数据。该函数又依赖于 XmlInvoiceForInvoice() 函数来为其完成所有工作。
我们不必手动填充 xml.Name 字段(除非我们想使用名字空间),因此在这里,当创建 *XMLInvoices 的时候,我们只需填充 Version 字段以保证我们的标签有一个 version 属性,例如 <INVILES verion="100">。
同时,我们将 Invoice 字段设置成一个空间足够容纳所有的发票数据的空切片。这样做不是严格必须的,但是与将该字段的初始值留空相比,这样做可能更高效,因为这样做意味着调用内置的 append() 函数时无需分配内存和复制数据以扩充切片容量。
func XMLInvoiceForlnvoice(invoice *Invoice) *XMLInvoice {
xmlInvoice := &XMLInvoice{
Id: invoice.id,
CustomerId: invoice.CustomerId,
Raised: invoice.Raised.Format(dateFormat),
Due: invoice.Due.Format(dateFormat),
Paid: invoice.Paid,
Note: invoice.Note,
Item: make([]*XMLItem, 0, len(invoice.Items)),
}
for _, item := range invoice.Items {
xmlItem := &XMLItem {
Id: item.Id,
Price: item.Price,
Quantity: item.Quantity,
Note: item.Note,
}
xmlInvoice.Item = append(xmlInvoice.Item, xmlItem)
}
return xmlInvoice
}该函数接受一个 Invoice 值并返回一个等价的 XMLInvoice 值。该转换非常直接,只需简单地将 Invoice 中每个字段的值复制至 XMLInvoice 字段中。由于我们选择自己来处理创建以及到期日期(因此我们只需存储日期而非完整的日期/时间),我们只需将其转换成字符串。
而对于 Invoice.Items 字段,我们将每一项转换成 XMLItem 后添加到 XMLInvoice.Item 切片中。与前面一样,我们使用相同的优化方式,创建 Item 切片时分配了足够多的空间以避免 append() 时需要分配内存和复制数据。前文阐述 JSON 格式时我们已讨论过 time.Time 值的写入。
最后需要注意的是,我们的代码中没有做任何 XML 转义,它是由 xml.Encoder.Encode() 方法自动完成的。
读 XML 文件
读 XML 文件比写 XML 文件稍微复杂,特别是在必须处理一些我们自定义的字段的时候(例如日期)。但是,如果我们使用合理的打上 XML 标签的结构体,就不会复杂。
func (XMLMarshaler) UnmarshalInvoices(reader io.Reader)([]*Invoice, error) {
xmlInvoices := &XMLInvoices{}
decoder := xml.NewDecoder(reader)
if err := decoder.Decode(xmlInvoices); err != nil {
return nil, err
}
if xmlInvoices.Version > fileVersion {
return nil, fmt.Errorf ("version %d is too new to read", xmlInvoices.Version)
}
return xmlInvoices.Invoices()
}该方法接受一个 io.Reader( 也就是说,任何满足 io.Reader 接口的值如打开的文件或者打开的压缩文件),并从其中读取 XML。该方法的开始处创建了一个指向空 XMLInvoices 结构体的指针,以及一个 xml.Decoder 用于读取 io.Reader。
然后,整个 XML 文件由 xml.Decoder.Decode() 方法解析,如果解析成功则将 XML 文件的数据填充到该 *XMLInvoices 结构体中。如果解析失败(例如,XML 文件语法有误,或者该文件不是一个合法的发票文件),那么解码器会立即返回错误值给调用者。
如果解析成功,我们再检查其版本,如果该版本是我们能够处理的,就将该 XML 结构体转换成我们程序内部使用的结构体。当然,如果我们直接使用带 XML 标签的结构体,该转换步骤就没必要了。
func (xmllnvoices *XMLInvoices) Invoices() (invoices []*Invoice, err error){
invoices = make([]*Invoice, 0, len(xmllnvoices.Invoice))
for _, XMLInvoice := range xmlInvoices.Invoice {
invoice, err := xmlInvoice.Invoice()
if err != nil {
return nil, err
}
invoices = append(invoices, invoice)
}
return invoices, nil
}该 XMLInvoices.Invoices() 方法将一个 XMLInvoices 值转换成一个 []Invoice 值,它是 XmllnvoicesForInvoices() 函数的逆反操作,并将具体的转换工作交给 XMLInvoice.Invoice() 方法完成。
func (xmlInvoice *XMLInvoice) Invoice() (invoice *Invoice, err error) {
invoice = &Invoice{
Id: xmlInvoice.Id,
CustomerId: xmlInvoice.CustomerId,
Paid: xmlInvoice.Paid,
Note: strings.TrimSpace(xmlInvoice.Note),
ems: make([]*Item, 0, len(xmlInvoice.Item)),
}
if invoice.Raised, err = time.Parse(dateFormat, xmlInvoice.Raised);
err != nil {
return nil, err
}
if invoice.Due, err = time.Parse(dateFormat, xmlInvoice.Due);
err != nil{
return nil, err
}
for _, xmlItem := range xmlInvoice.Item {
item := &Item {
Id: xmlItem.Id,
Price: xmlItem.Price,
Quantity: xmlItem.Quantity,
Note: strings.TrimSpace(xmlItem.Note),
}
invoice.Items = append(invoice.Items, item)
}
return invoice, nil
}该方法用于返回与调用它的 *XMLInvoice 值相应的 *Invoice 值。
该方法在开始处创建了一个 Invoice 值,其大部分字段都由来自 XMLInvoice 的数据填充,而 Items 字段则设置成一个容量足够大的空切片。
然后,由于我们选择自己处理这些,因此手动填充两个日期/时间字段。time.Parse() 函数接受一个日期/时间格式的字符串(如前所述,该字符串必须基于精确的日期/时间值,如 2006-01-02T15:04:05Z07:00),以及一个需要解析的字符串,并返回等价的 time.Time 值和 nil,或者,返回一个 nil 和一个错误值。
接下来是填充发票的 Items 字段,这是通过迭代 XMLInvoice 的 Item 字段中的 *XMLItems 并创建相应的 *Items 来完成的。最后,返回 *Invoice。
正如写 XML 时一样,我们无需关心对所读取的 XML 数据进行转义,xml.Decoder.Decode() 函数会自动处理这些。
xml 包支持比我们这里所需的更为复杂的标签,包括嵌套。例如,标签名为 ‘xml:"Books>Author"‘ 产生的是
Go语言使用Gob传输数据
Gob 是 Go语言自己的以二进制形式序列化和反序列化程序数据的格式;可以在 encoding 包中找到。这种格式的数据简称为 Gob (即 Go binary 的缩写)。类似于 Python 的 "pickle" 和 Java 的"Serialization"。
Gob 通常用于远程方法调用参数和结果的传输,以及应用程序和机器之间的数据传输。它和 JSON 或 XML 有什么不同呢?Gob 特定地用于纯 Go 的环境中,例如,两个用 Go 写的服务之间的通信。这样的话服务可以被实现得更加高效和优化。
Gob 不是可外部定义,语言无关的编码方式。因此它的首选格式是二进制,而不是像 JSON 和 XML 那样的文本格式。Gob 并不是一种不同于 Go 的语言,而是在编码和解码过程中用到了 Go 的反射。
Gob 文件或流是完全自描述的:里面包含的所有类型都有一个对应的描述,并且总是可以用 Go 解码,而不需要了解文件的内容。
只有可导出的字段会被编码,零值会被忽略。在解码结构体的时候,只有同时匹配名称和可兼容类型的字段才会被解码。当源数据类型增加新字段后,Gob 解码客户端仍然可以以这种方式正常工作:解码客户端会继续识别以前存在的字段。并且还提供了很大的灵活性,比如在发送者看来,整数被编码成没有固定长度的可变长度,而忽略具体的 Go 类型。
假如在发送者这边有一个有结构 T:
type T struct { X, Y, Z int }
var t = T{X: 7, Y: 0, Z: 8}而在接收者这边可以用一个结构体 U 类型的变量 u 来接收这个值:
type U struct { X, Y *int8 }
var u U在接收者中,X 的值是 7,Y 的值是 0(Y 的值并没有从 t 中传递过来,因为它是零值)和 JSON 的使用方式一样,Gob 使用通用的 io.Writer 接口,通过 NewEncoder() 函数创建 Encoder 对象并调用 Encode();相反的过程使用通用的 io.Reader 接口,通过 NewDecoder() 函数创建 Decoder 对象并调用 Decode 。
【示例 1】下面代码是一个编解码,并且以字节缓冲模拟网络传输的简单例子:
package main
import (
"bytes"
"fmt"
"encoding/gob"
"log"
)
type P struct {
X, Y, Z int
Name string
}
type Q struct {
X, Y *int32
Name string
}
func main() {
//初始化编码器和解码器。通常 ENC 和 DEC 为
//绑定到网络连接,编码器和解码器将
//在不同的进程中运行。
var network bytes.Buffer // 网络连接
enc := gob.NewEncoder(&network) // 写入网络
dec := gob.NewDecoder(&network) // 从网络读取
// 对值进行编码(发送)
err := enc.Encode(P{3, 4, 5, "Pythagoras"})
if err != nil {
log.Fatal("encode error:", err)
}
// 解码(接收)值
var q Q
err = dec.Decode(&q)
if err != nil {
log.Fatal("decode error:", err)
}
fmt.Printf("%q: {%d,%d}
", q.Name, *q.X, *q.Y)
}
// Output: "Pythagoras": {3,4}【示例 2】编码到文件:
package main
import (
"encoding/gob"
"log"
"os"
)
type Address struct {
Type string
City string
Country string
}
type VCard struct {
FirstName string
LastName string
Addresses []*Address
Remark string
}
var content string
func main() {
pa := &Address{"private", "Aartselaar","Belgium"}
wa := &Address{"work", "Boom", "Belgium"}
vc := VCard{"Jan", "Kersschot", []*Address{pa,wa}, "none"}
// fmt.Printf("%v:
", vc) // {Jan Kersschot [0x126d2b80 0x126d2be0] none}:
// 使用编码器
file, _ := os.OpenFile("vcard.gob", os.O_CREATE|os.O_WRONLY, 0)
defer file.Close()
enc := gob.NewEncoder(file)
err := enc.Encode(vc)
if err != nil {
log.Println("Error in encoding gob")
}
}Go语言纯文本文件的读写操作
对于纯文本文件,我们必须创建自定义的格式,理想的格式应该易于解析和扩展。
下面是某单个发票以自定义纯文本格式存储的数据。
INVOICE ID=5441 CUSTOMER=960 RAISED=2012-09-06 DUE=2012-10-06 PAID=true
ITEM ID=BE9066 PRICE=400.89 QUANTITY=7: Keep out of <direct> sunlight
ITEM ID=AM7240 PRICE=183.69 QUANTITY=2
ITEM ID=PT9110 PRICE=105.40 QUANTITY=3: Flammable在该格式中,每个发票是一个 INVOICE 行,然后是一个或者多个 ITEM 行,最后是换页符。每一行(无论是发票还是它们的项)的基本结构都相同:起始处有一个单词表示该行的类型,接下来是一个空格分隔的“键=值”序列,以及可选的跟在一个冒号和一个空格后面的注释文本。
写纯文本文件
由于 Go语言的 fmt 包中打印函数强大而灵活,写纯文本数据非常简单直接。
type TxtMarshaler struct{}
func (TxtMarshaler) Marshallnvoices(writer io.Writer,
invoices []*Invoice) error {
bufferedWriter := bufio.NewWriter(writer)
defer bufferedWriter.Flush()
var write writerFunc = func (format string, args...interface{}) error {
_, err := fmt.Fprintf(bufferedWriter, format, args ...)
return err
}
if err := write("%s %d
", fileType, fileVersion); err != nil {
return err
}
for invoice := range invoices {
if err := write.Writeinvoice(invoice); err != nil {
return err
}
}
return nil
}该方法在开始处创建了一个带缓冲区的 writer,用于操作所传入的文件。延迟执行刷新缓冲区的操作是必要的,这可以保证我们缩写的数据确实能够写入文件(除非发生错误)。
与以 if _,err := fmt.Fprintf(bufferedWriter,...); err != nil {return err} 的形式来检查每次写操作不同的是,我们创建了一个函数字面量来做两方面的简化。第该 writer() 函数会忽略 fmt.Fprintf() 函数报告的所写字节数。其次,该函数处理了 bufferedWriter,因此我们不必在自己的代码中显式地提到。
我们本可以将 write() 函数传给辅助函数的,例如,writeinvoice(write, invoice)。但不同于此做法的是,我们往前更进了一步,将该方法添加到 writerFunc 类型中。
这是通过声明接受一个 writerFunc 值作为其接收器的方法(即函数)来达到,跟定义任何其他类型一样。这样就允许我们以 write.writeinvoice(invoice) 这样的形式调用,也就是说,在 write() 函数自身上调用方法。并且,由于这些方法接受 write() 函数作为它们的接收器,我们就可以使用 write() 函数。
需注意的是,我们必须显式地声明 write() 函数的类型 (writerFunc)。如果不这样做,Go语言就会将其类型定义为 func(string, . . . interface{}) error(当然,它本来就是这种类型),并且不允许我们在其上调用 writerFunc 方法(除非我们使用类型转换的方法将其转换成 writerFunc 类型)。
有了方便的 write() 函数(及其方法),我们就可以开始写入文件类型和文件版本(后者使得容易适应数据的改变)。然后,我们迭代每一个发票项,针对每一次迭代,我们调用 write() 函数的 writeinvoice() 方法。
const noteSep = ":"
type writerFunc func(string, ..interface{}) error
func (write writerFunc) writeinvoice(invoice *Invoice) error {
note := ""
if invoice.Note != "" {
note = noteSep + "" + invoice.Note
}
if err := write("INVOICE ID=%d CUSTOMER=%d RAISED=%s DUE=%s" +
"PAID=%t%s
", invoice.Id, invoice.Customerld,
invoice.Raised.Format(dateFormat),
invoice.Due.Format(dateFormat), invoice.Paid, note); err != nil {
return err
}
if err := write.writeitems(invoice.Items); err != nil {
return err
}
return write ("f
")
}该方法用于写每一个发票项。它接受一个要写的发票项,同时使用作为接收器传入的 write() 函数来写数据。
发票数据一次性就可以写入,如果给出了注释文本,我们就在其前面加入冒号以及空格来将其写入。对于日期/时间(即 time.Time值),我们使用 time.Time.Format() 方法,跟我们以 JSON 和 XML 格式写入数据时一样。而对于布尔值,我们使用 %t 格式指令,也可以使用 %v 格式指令或 strconv.FormatBol() 函数。
一旦发票行写好了,就开始写发票项。最后,我们写入分页符和一个换行符,表示发票数 据的结束。
func (write writerFunc) writelterns(items []*Item) error {
for _, item := range items {
note :=""
if item.Note != "" {
note = noteSep + " " + item.Note
}
if err := write("ITEM ID=%s PRICE=%.2f QUANTITY=%d%s
", item.Id, item.Price, item.Quantity, note); err != nil {
return err
}
}
return nil
}该 writeltems() 方法接受发票的发票项,并使用作为接收器传入的 write() 函数来写数据。它迭代每一个发票项并将其写入,并且也跟写入发票数据一样,如果其注释文档为空则无需写入。
读纯文本文件
打开并读取一个纯文本格式的数据跟写入纯文本格式数据一样简单。要解析文本来重建原始数据可能稍微复杂,这需根据格式的复杂性而定。
有 4 种方法可以使用。前 3 种方法包括将每行切分,然后针对非字符串的字段使用转换函数如 strconv.Atoi() 和 time.Parse()。这些方法是:
- 第一,手动解析(例如,一个字母一个字母或者一个字一个字地解析),这样做实现起来烦琐,不够健壮并且也慢;
- 第二,使用 fmt.Fields() 或者 fmt.Split() 函数来将每行切分;
- 第三,使用正则表达式。对于该 invoicedata 程序,我们使用
- 第四,无需将每行切分或者使用转换函数,因为我们所 需的功能都能够交由fmt包的扫描函数处理。
func (TxtMarshaler) Unmarshallnvoices(reader io.Reader) ([]*Invoice, error) {
bufferedReader := bufio.NewReader(reader)
if err := checkTxtVersion(bufferedReader); err != nil {
return nxl, err
}
var invoices []*Invoice
eof := false
for lino := 2; !eof; lino++ {
line, err := bufferedReader.Readstring('
)
if err == io.EOF{
err = nil // io.EOF不是一个真正的错误
eof = true //下一次迭代的时候会终止循环
} else if err != nil {
return nilz err //遇到真正的错误则立即停止
}
if invoices, err = parseTxtLine(lino, line, invoices); err != nil {
return nil, err
}
}
return invoices, nil
}针对所传入的 io.Reader,该方法创建了一个带缓冲的 reader,并将其中的每一行轮流传入解析函数中。通常,对于文本文件,我们会对 io.EOF 进行特殊处理,以便无论它是否以新行结尾其最后一行都能被读取。(当然,对于这种格式,这样做相当自由。)
按照常规,从行号 1 开始,该文件被逐行读取。第一行用于检查文件是否有个合法的类型和版本号,因此处理实际数据时,行号 (lino) 从 2 开始读起。
由于我们逐行工作,并且每一个发票文件都表示成两行甚至多行(一行 INVOICE 行和一行或者多行 ITEM 行),我们需跟踪当前发票,以便每读一行就可以将其添加到当前发票数据中。这很容易做到,因为所有的发票数据都被追加到一个发票切片中,因此当前发票永远是处于位置 invoices[len(invoices)-1] 处的发票。
当 parseTxtLine() 函数解析一个 INVOICE 行时,它会创建一个新的 Invoice 值,并将一个指向该值的指针追加到 invoices 切片中。
如果要在一个函数内部往一个切片中追加数据,有两种技术可以使用。第一种技术是传入一个指向切片的指针,然后在所指向的切片中操作。第二种技术是传入切片值,同时返回(可能被修改过的)切片给调用者,以赋值回原始切片。parseTxtLine() 函数使用第二种技术。
func parseTxtLine(lino int, line string, invoices []*Invoice) ([]*Invoicer error) {
var err error
if strings.HasPrefix(line, "INVOICE") {
var invoice *Invoice
invoice, err = parseTxtlnvoice(lino, line)
invoices = append(invoices, invoice)
} else if strings.HasPrefix(line, "ITEM") {
if len(invoices) == 0 {
err = fmt.Errorf("item outside of an invoice line %dM, lino)
} else {
var item *Item
item, err = parseTxtItem(lino, line)
items := &invoices[len(invoices)-1].Items
*items = append(*items, item)
}
}
return invoices, err
}该函数接受一个行号(lino,用于错误报告),需被解析的行,以及我们需要填充的发票切片。
如果该行以文本“INVOICE”开头,我们就调用 parseTxtInvoice() 函数来解析该行,并创建一个 Invoice 值,并返回一个指向它的指针。然后,我们将该 *Inovice 值追加到 invoices 切片中,并在最后返回该 invoices 切片和 nil 值或者错误值。
需要注意的是,这里的发票信息是不完整的,我们只有它的 ID、客户 ID、创建和持续时间、是否支付以及注释信息,但是没有任何发票项。
如果该行以“ITEM”开头,我们首先检查当前发票是否存在(即 invoices 切片不为空)。如果存在,我们调用 parseTxtItem() 函数来解析该行并创建一个 Item 值,然后返回一个指向该值的指针。然后我们将该项添加到当前发票的项中。这可以通过取得指向当前发票项的指针以及将指针的值设置为追加新 *Item 后的结果来达到。当然,我们本可以使用 invoices[len(invoices)-1].Items = append(invoices[len(invoices)-1].Items, item) 来直接添加 *Item。
任何其他的行(例如空和换页行)都被忽略。顺便提一下,理论上而言,如果我们优先处理“ITEM”的情况该函数会更快,因为数据中发票项的行数远比发票和空行的行数多。
func parseTxtHnvoice(lino int, line string) (invoice *Invoice, err error) {
invoice = &Invoice{}
var raised, due string
if _, err = fmt.Sscanf (line, "INVOICE ID=%d CUSTOMER=%d" +
"RAISED=%s DUE=%s PAID=%t", &invoice.Id, &invoice.CustomerTd,
&raised, &due, &invoice.Paid); err != nil {
return nil, fmt.Errorf("invalid invoice %v line %d", err, lino)
}
if invoice.Raised, err = time.Parse(dateFormat, raised); err != nil {
return nil, fmt.Errorf("invalid raised %v line %d", err, lino)
}
if invoice.Due, err = time.Parse(dateFormat, due); err != nil {
return nil, fmt.Errorf ("invalid due %v line %d", err, lino)
}
if i := strings.Index(line, noteSep); i > -1 {
invoice.Note = strings.TrimSpace(line[i+len(noteSep):])
}
return invoice, nil
}函数开始处,我们创建了一个 0 值的 Invoice 值,并将指向它的指针赋值给 invoice 变量(类型为 *Invoice)。扫描函数可以处理字符串、数字以及布尔值,但不能处理 time.Time 值,因此我们将创建以及持续时间以字符串的形式输入,并单独解析它们。下表中列岀了 fmt 中的扫描函数。
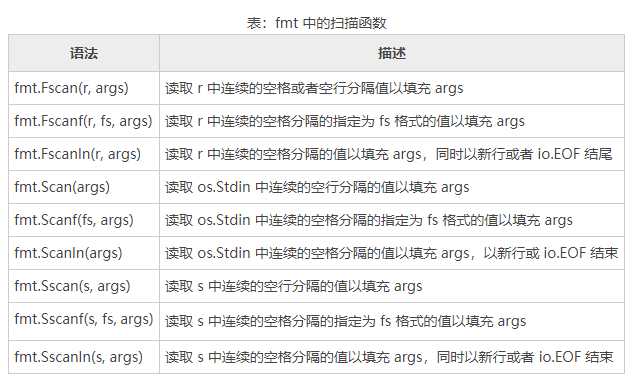
其中:参数 r 是一个从其中读数据的 io.Reader,s 是一个从其中读数据的字符串,fs 是一个用于 fmt 包中打印函数的格式化字符串,args 表示一个或者多个需填充的值的指针。所有这些扫描函数返回成功解析(即填充)项的数量,以及另一个空或者非空的错误值。
如果 fmt.Sscanf() 函数不能读入与我们所提供的值相同数量的项,或者如果发生了错误(例如,读取错误),函数就会返回一个非空的错误值。
日期使用 time.Parse() 函数来解析,这在之前的节中已有阐述。如果发票行有冒号,则意味着该行末尾处有注释,那么我们就删除其空白符,并将其返回。我们使用了表达式 line[i+1:] 而非 line[i+len(noteSep):],因为我们知道 noteSep 的冒号字符占用了一个 UTF-8 字节,但为了更为健壮,我们选择了对任何字符都有效的方法,无论它占用多少字节。
func parseTxtltem(lino int, line string) (item *Item, err error) {
item = &Item{}
if _, err = £mt.Sscanf(line, "ITEM ID=%s PRICE=%f QUANTITY=%d",
&itern. Id, &item. Price, &item.Quantity); err ! = nil {
return nil, fmt.Errorf("invalid item %v line %d", err, lino)
}
i£ i := strings.Index(line, noteSep); i > -1 {
item.Note = strings.TrimSpace(line[i+len(noteSep):])
}
return item, nil
}该函数的功能如我们所见过的 parseTxtInvoice() 函数一样,区别在于除了注释文本之外,所有的发票项值都可以直接扫描。
func checkTxtversion(bufferReader *buffio.Reader) error{
var version int
if _, err := fmt.Fscanf(bufferedReader,"INVOICES %d
",&version);
err != nil{
retrun errors.New("cannot read non-invoices text file")
} else if version > fileVersion {
return fmt.Erroff("version %d is too new to read", version)
}
return nil
}该函数用于读取发票文本文件的第一行数据。它使用 fmt.Fscanf() 函数来直接读取 bufio.Reader。如果该文件不是一个发票文件或者其版本太新而不能处理,就会报告错误。否则,返回 nil 值。
使用 fmt 包的打印函数来写文本文件比较容易。解析文本文件却挑战不小,但是 Go语言的 regexp 包中提供了 strings.Fields() 和 strings.Split() 函数,fmt 包中提供了扫描函数,使得我们可以很好的解决该问题。
Go语言二进制文件的读写操作
Go语言的二进制 (gob) 格式是一个自描述的二进制序列。从其内部表示来看,Go语言的二进制格式由一个 0 块或者更多块的序列组成,其中的每一块都包含一个字节数,一个由 0 个或者多个 typeId-typeSpecification 对组成的序列,以及一个 typeId-value 对。
如果 typeId-value 对的 typeId 是预先定义好的(例如,bool、int 和 string 等),则这些 typeId-typeSpecification 对可以省略。否则就用类型对来描述一个自定义类型(如一个自定义的结构体)。类型对和值对之间的 typeId 没有区别。
正如我们将看到的,我们无需了解其内部结构就可以使用 gob 格式, 因为 encoding/gob 包会在幕后为我们打理好一切底层细节。
encoding/gob 包也提供了与 encoding/json 包一样的编码解码功能,并且容易使用。通常而言,如果对肉眼可读性不做要求,gob 格式是 Go语言上用于文件存储和网络传输最为方便的格式。
写 Go语言二进制文件
下面有个方法用于将整个 []*invoice 项的数据以 gob 的格式写入一个打开的文件(或者是任何满足 io.Writer 接口的值)中。
type GobMarshaler struct{}
func (GobMarshaler) MarshalInvoices(writer io.Writer, invoices []*Invoice) error {
encoder := gob.NewEncoder(writer)
if err := encoder.Encode(magicNumber); err != nil {
return err
}
if err := encoder.Encode(fileVersion); err != nil {
return err
}
return encoder.Encode(invoices)
}在方法开始处,我们创建了一个包装了 io.Writer 的 gob 编码器,它本身是一个 writer,让我们可以写数据。
我们使用 gob.Encoder.Encode() 方法来写数据。该方法能够完美地处理我们的发票切片,其中每个发票切片包含它自身的发票项切片。该方法返回一个空或者非空的错误值。如果发生错误,则立即返回给它的调用者。
往文件写入幻数 (magic number) 和文件版本并不是必需的,但正如将在练习中所看到的那样,这样做可以在后期更方便地改变文件格式。
需注意的是,该方法并不真正关心它编码数据的类型,因此创建类似的函数来写 gob 数据区别不大。此外,GobMarshaler.MarshalInvoices() 方法无需任何改变就可以写新数据格式。
由于 Invoice 结构体的字段都是布尔值、数字、字符串、time.Time 值以及包含布尔值、数字、字符串和 time.Time 值的结构体(如 Item),这里的代码可以正常工作。
如果我们的结构体包含某些不可用 gob 格式编码的字段,那么就必须更改该结构体以便满足 gob.GobEncoder 和 gob.GobDecoder 接口。该 gob 编码器足够智能来检查它需要编码的值是不是一个 gob.GobEncoder,如果是,那么编码器就使用该值自身的 GobEncode() 方法而非编码器内置的编码方法来编码。
相同的规则也作用于解码时,检查该值是否定义了 GobDecode() 方法以满足 gob.GobDecoder 接口。(该 invoicedata 例子的源代码 gob.go 文件中包含了相应的代码,将 Invoice 定义成一个编码器和解码器。因为这些代码不是必须的,因此我们将其注释掉,只是为了演示如何做。)让一个结构体满足这些接口会极大地降低 gob 的读写速度,也会产生更大的文件。
读 Go语言二进制文件
读 gob 数据和写一样简单,如果我们的目标数据类型与写时相同。GobMarshaler.UnmarshalInvoices() 方法接受一个 io.Reader(例如,一个打开的文件),并从中读取 gob 数据。
func (GobMarshaler) UnmarshalInvoices(reader io.Reader)([]*Invoicer, error) {
decoder := gob.NewDecoder(reader)
var magic int
if err := decoder.Decode(&magic); err != nil {
return nil, err
}
if magic != magicNumber {
return nil, errors.New("cannot read non-invoices gob file")
}
var version int
if err := decoder.Decode(&version); err != nil {
return nil, err
}
if version > fileVersion {
return nil, fmt.Errorf("version %d is too new to read", version)
}
var invoices []*Invoice
err := decoder.Decode(&invoices)
return invoices, err
}我们有 3 项数据要读:幻数、文件版本号以及所有发票数据。gob.Decoder.Decode() 方法接受一个指向目标值的指针,返回一个空或者非空的错误值。我们使用头两个变量(幻数和版本号)来确认我们得到的是一个 gob 格式的发票文件,并且该文件的版本是我们可以处理的。
然后,我们读取发票文件,在此过程中,gob.Decoder.Decode() 方法会根据所读取的发票数据增加 invoices 切片的大小,并根据需要来将指向函数实时创建的 Invoices 数据(及其发票项)的指针保存在 invoices 切片中。最后,该方法返回 invoices 切片,以及一个空的错误值,或者如果发生问题则返回非空的错误值。
如果发票数据由于添加了导出字段被更改了,针对布尔值、整数、字符串、time.Time 值以及包含这些类型值的结构体,该方法还能继续工作。当然,如果数据包含其他类型,那就必须更新方法以满足 gob.GobEncoder 和 gob.GobDecoder 接口。
处理结构体类型时,gob 格式非常灵活,能够无缝地处理一些不同的数据结构。例如,如果一个包含某值的结构体被写成 gob 格式,那么就必然可以从 gob 格式中将该值读回到此结构体,甚至也读回到许多其他类似的结构体,比如包含指向该值指针的结构体,或者结构体中的值类型兼容也可(比如 int 相对于 uint,或者类似的情况)。
同时,正如 invoicedata 示例所示,gob 格式可以处理嵌套的数据。gob 的文档中给出了它能处理的格式以及该格式的底层存储结构,但如果我们使用相同的类型来进行读写,正如上例中所做的那样,我们就不必关心这些。
Go语言自定义二进制文件的读写操作
虽然 Go语言的 encoding/gob 包非常易用,而且使用时所需代码量也非常少,我们仍有可能需要创建自定义的二进制格式。自定义的二进制格式有可能做到最紧凑的数据表示,并且读写速度可以非常快。
不过,在实际使用中,我们发现以 Go语言二进制格式的读写通常比自定义格式要快非常多,而且创建的文件也不会大很多。但如果我们必须通过满足 gob.GobEncoder 和 gob.GobDecoder 接口来处理一些不可被 gob 编码的数据,这些优势就有可能会失去。
在有些情况下我们可能需要与一些使用自定义二进制格式的软件交互,因此了解如何处理二进制文件就非常有用。
下图给出了 .inv 自定义二进制格式如何表示一个发票文件的概要。整数值表示成固定大小的无符号整数。布尔值中的 true 表示成一个 int8 类型的值 1,false 表示成 0。字符串表示成一个字节数(类型为 int32)后跟一个它们的 UTF-8 编码的字节切片 []byte。
对于日期,我们采取稍微非常规的做法,将一个 ISO-8601 格式的日期(不含连字符)当成一个数字,并将其表示成 int32 值。例如,我们将日期 2006-01-02 表示成数字 20 060 102。每一个发票项表示成一个发票项的总数后跟各个发票项。
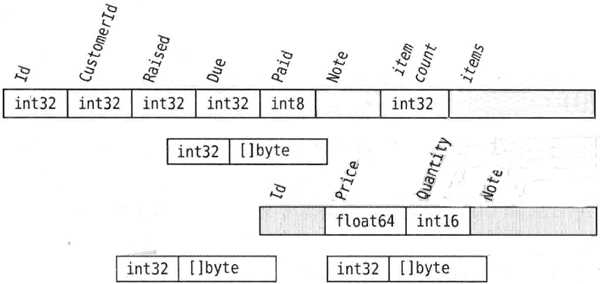
图:.inv 自定义二进制格式
写自定义二进制文件
encoding/binary 包中的 binary.Write() 函数使得以二进制格式写数据非常简单。
type InvMarshaler struct{}
var byteOrder = binary.LittleEndian
func (InvMarshaler) MarshalInvoices(writer io.Writer, invoices []*Invoice) error {
var write invWriterFunc = func(x interface{}) error {
return binary.Write(writer, byteOrder, x)
}
if err := write(uint32(magicNumber)); err != nil {
return err
}
if err := write(uintl6(fileVersion)); err != nil {
return err
}
if err := write(int32(len(invoices))); err != nil {
return err
}
for _, invoice := range invoices {
if err := write.writeInvoice(invoice); err != nil {
return err
}
}
return nil
}该方法将所有发票项写入给定的 io.Writer 中。它开始时创建了一个便捷的 write() 函数,该函数能够捕获我们要使用的 io.Writer 和字节序。正如处理上 .txt 格式所做的那样,我们将 write() 函数定义为一个特定的类型 (invWriterFunc),并且为该 write() 函数创建了一些方法(例如 invWriterFunc.Writeinvoices()),以便后续使用。
需注意的是,读和写二进制数据时其字节序必须一致。(我们不能将 byteOrder 定义为一个常量,因为 binary.LittleEndian 或者 binary.BigEndian 不是像字符串或者整数这样的简单值。)
这里,写数据的方式与我们之前在看到写其他格式数据的方式类似。一个非常重要的不同在于,将幻数和文件版本写入后,我们写入了一个表示发票数量的数字。(也可以跳过而不写该数字,而只是简单地将发票写入。然后,读数据的时候,持续地依次读入发票直到遇到 io.EOF。)
type invWriterFunc func(interface{}) error
func (write invWriterFunc) writeinvoice(invoice *Invoice) error {
for _, i := range []int{invoice.Id, invoice.Customerld} {
if err := write(int32(i)); err != nil {
return err
}
}
for date := range []time.Time{invoice.Raised, invoice.Due} {
if err := write.writeDate(date); err != nil {
return err
}
}
if err := write.writeBool(invoice.Paid); err != nil {
return err
}
if err := write.writeString(invoice.Note); err != nil {
return err
}
if err := write(int32(len(invoice.Items))); err != nil {
return err
}
for item := range invoice.Items {
if err := write.writeitem(item); err != nil {
return err
}
}
return nil
}对于每—个发票数据,writeInvoice() 方法都会被调用一遍。它接受一个指向被写发票数据的指针,并使用作为接收器的 write() 函数来写数据。
该方法开始处以 int32 写入了发票 ID 及客户 ID。当然,以纯 int 型写入数据是合法的,但底层机器以及所使用的 Go语言版本的改变都可能导致 int 的大小改变,因此写入时非常重要的一点是确定整型的符号和大小,如 uintf32 和 int32 等。
接下来,我们使用自定义的 writeDate() 方法写入创建和过期时间,然后写入表示是否支付的布尔值和注释字符串。最后,我们写入了一个代表发票中有多少发票项的数字,随后再使用 writeItem() 方法写入发票项。
const invDateFormat = ”20060102” // 必须总是使用该日期值
func (write invWriterFunc) writeDate(date time.Time) error {
i, err := strconv.Atoi(date.Format(invDateFormat))
if err != nil {
return err
}
return write(int32(i))
}前文中我们讨论了 time.Time.Format() 函数以及为何必须在格式字符串中使用特定的日期 2006-01-02。这里,我们使用了类 ISO-8601 格式,并去除连字符以便得到一个八个数字的字符串,其中如果月份和天数为单一数字则在其前面加上 0。
然后,将该字符串转换成数字。例如,如果日期是 2012-08-05,则将其转换成一个等价的数字,即 20120805,然后以 int32 的形式将该数字写入。
值得一提的是,如果我们想存储日期/时间值而非仅仅是日期值,或者只想得到一个更快的计算,我们可以将对该方法的调用替换成调用 write(int64 (date.Unix ())),以存储一个 Unix 新纪元以来的秒数。相应的读取数据的方法则类似于
var d int64; if err := binary.Read(reader, byteOrder, &d); err != nil { return err }; date := time.Unix(d, 0)
func (write invWriterFunc) writeBool(b bool) error {
var v int8
if b {
v = 1
}
return write(v)
}encoding/binary 包不支持读写布尔值,因此我们创建了该简单方法来处理它们。顺便提一下,我们不必使用类型转换(如 int8(v)),因为变量 v 已经是一个有符号并且固定大小的类型了。
func (write invWriterFunc) writeString(s string) error {
if err := write(int32(len(s))); err != nil {
return err
}
return write([]byte(s))
}字符串必须以它们底层的 UTF-8 编码字节的形式来写入。这里,我们首先写入了所需写入的字节总数,然后再写入所有字节。(如果数据是固定宽度的,就不需要写入字节数。当然,前提是,读取数据时,我们创建了一个存储与写入的数据大小相同的空切片 []byte。)
func (write invWriterFunc) writeitem(item *Item) error {
if err := write.writeString(item.Id); err != nil {
return err
}
if err := write(item.Price); err != nil {
return err
}
if err := write(intl6(item.Quantity)); err != nil {
return err
}
return write.writeString(item.Note)
}该方法用于写入一个发票项。对于字符串 ID 和注释文本,我们使用 invWriterFunc.writeString() 方法,对于物品数量,我们使用无符号的大小固定的整数。但是对于价格,我们就以它原始的形式写入,因为它本来就是个固定大小的类型 (float64)。
往文件中写入二进制数据并不难,只要我们小心地将可变长度数据的大小在数据本身前面写入,以便读数据时知道该读多少。当然,使用 gob 格式非常方便,但是使用一个自定义的二进制格式所产生的文件更小。
读自定义二进制文件
读取自定义的二进制数据与写自定义二进制数据一样简单。我们无需解析这类数据,只需使用与写数据时相同的字节顺序将数据读进相同类型的值中。
func (InvMarshaler) Unmarshallnvoices(reader io.Reader) ([]*Invoice, error){
if err := checkInvVersion(reader); err != nil {
return nil, err
}
count, err := readIntFromInt32(reader)
if err != nil {
return nil, err
}
invoices := make([]*Invoice, 0, count)
for i := 0; i < count; i++ {
invoice, err := readInvInvoice(reader)
if err != nil {
return nil, err
}
invoices = append(invoices, invoice)
}
return invoices, nil
}该方法首先检查所给定版本的发票文件能否被处理,然后使用自定义的 readIntFromInt32() 函数从文件中读取所需处理的发票数量。我们将 invoices 切片的长度设为 0 (即当前还没有发票),但其容量正好是我们所需要的。然后,轮流读取每一个发票并将其存储在 invoices 切片中。
另一种可选的方法是使用 make([] *Invoice, count) 代替 make(),使用 invoices[i]=invoice 代替 append()。不管怎样,我们倾向于使用所需的容量来创建切片,因为与实时增长切片相比,这样做更有潜在的性能优势。
毕竟,如果我们再往一个其长度与容量相等的切片中追加数据,切片会在背后创建一个新的容量更大的切片,并将起原始切片数据复制至新切片中。然而,如果其容量一开始就足够,后面就没必要进行复制。
func checklnvVersion(reader io.Reader) error {
var magic uint32
if err := binary.Read(reader, byteOrder, &magic); err != nil {
return err
}
if magic ! = magicNuntber {
return errors.New("cannot read non-invoices inv file")
}
var version uintl6
if err := binary.Read(reader, byteOrder, &version); err != nil {
return err
}
if version > fileVerson {
return fmt.Errorf("version %d is too new to read", version)
}
return nil
}该函数试图从文件中读取其幻数及版本号。如果该文件格式可接受,则返回 nil;否则返回非空错误值。
其中的 binary.Read() 函数与 binary.Write() 函数相对应,它接受一个从中读取数据的 io.Reader、一个字节序以及一个指向特定类型的用于保存所读数据的指针。
func readIntFromInt32(reader io.Reader) (int, error) {
var i32 int32
err := binary.Read(reader, byteOrder, &i32)
return int(i32), err
}该辅助函数用于从二进制文件中读取一个 int32 值,并以 int 类型返回。
func readInvInvoice(reader io.Reader) (invoice *Invoice, err error) {
invoice = &Invoice{}
for _, pId := range []*int{&invoice.Id, &invoice.Customerld} {
if *pId, err = readIntFromInt32(reader); err != nil {
return nil, err
}
}
for _, pDate := range []*time.Time{&invoice.Raised, &invoice.Due} {
if *pDate, err = readInvDate(reader); err != nil {
return nil, err
}
}
if invoice.Paid, err = readBoolFromInt8(reader); err != nil {
return nil, err
}
if invoice.Note, err = readlnvString(reader); err != nil {
return nil, err
}
var count int
if count, err = readIntFromInt32(reader); err != nil {
return nil, err
}
invoice.Items, err = readInvItems(reader, count)
return invoice, err
}每次读取发票文件的时候,该函数都会被调用。函数开始处创建了一个初始化为零值的 Invoice 值,并将指向它的指针保存在 invoice 变量中。
发票 ID 和客户 ID 使用自定义的 readIntFromInt32() 函数读取。这段代码的微妙之处在于,我们迭代那些指向发票 ID 和客户 ID 的指针,并将返回的整数赋值给指针 (pId) 所指的值。
一个可选的方案是单独处理每一个 ID。例如,if invoice.Id, err = readIntFromInt32(reader) ; err ! = nil { return err}等。
读取创建及过期日期的流程与读取 ID 的流程完全一样,只是这次我们使用的是自定义的 readInvDate() 函数。
正如读取 ID 一样,我们也可以以更加简单的方式单独处理日期。例如,if invoice.Due, err = readlnvDate(reader); err != nil { return err }等。
稍后将看到,我们使用一些辅助函数读取是否支付的标志和注释文本。发票数据读完之后,我们再读取有多少个发票项,然后调用 readInvIterns() 函数读取全部发票项,传递给该函数一个用于读取的 io.Reader 值和一个表示需要读多少项的数字。
func readlnvDate(reader io.Reader) (time.Time, error) {
var n int32
if err := binary.Read(reader, byteOrder, &n); err != nil {
return time.Time{}, err
}
return time.Parse(invDateFormat, fmt.Sprint(n))
}该函数用于读取表示日期的 int32 值(如 20130501),并将该数字解析成字符串表示的日期值,然后返回对应的 time.Time 值(如 2013-05-01)。
func readBoolFromInt8(reader io.Reader) (bool, error) {
var i8 int8
err := binary.Read(reader, byteOrder, &i8)
return i8 == 1, err
}该简单的辅助函数读取一个 int8 数字,如果该数字为 1 则返回 true,否则返回 false。
func readInvString(reader io.Reader) (string, error) {
var length int32
if err := binary.Read(reader, byteOrder, &length); err != nil {
return "", nil
}
raw := make([]byte, length)
if err := binary.Read(reader, byteOrder, &raw); err != nil {
return "", err
}
return string(raw), nil
}该函数读取一个 []byte 切片,但它的原理适用于任何类型的切片,只要写入切片之前写明了切片中包含多少项元素。
函数首先将切片项的个数读到一个 length 变量中。然后创建一个长度与此相同的切片。给 binary.Read() 函数传入一个指向切片的指针之后,它就会往该切片中尽可能地读入该类型的项(如果失败则返回一个非空的错误值)。需注意的是,这里重要的是切片的长度,而非其容量(其容量可能等于或者大于长度)。
在本例中,该 []byte 切片保存了 UTF-8 编码的字节,我们将其转换成字符串后将其返回。
func readInvItems(reader io.Reader, count int) ([]*Item, error) {
items := make([]*Item, 0, count)
for i := 0; i < count; i++ {
item, err := readInvItem(reader)
if err != nil {
return nil, err
}
items = append(items, item)
}
return items, nil
}该函数读入发票的所有发票项。由于传入了一个计数值,因此它知道应该读入多少项。
func readlnvltem(reader io.Reader) (item Ttem, err error) {
item = &Item{}
if item.Id, err = readInvString(reader); err != nil {
return nil, err
}
if err = binary.Read(reader, byteOrder, &item.Price); err != nil {
return nil, err
}
if item.Quantity, err = readIntFromInt16(reader); err != nil {
return nil, err
}
item.Note, err = readInvString(reader)
return item, nil
}该函数读取单个发票项。从结构上看,它与 readInvInvoice() 函数类似,首先创建一个初始化为零值的 Item 值,并将指向它的指针存储在变量 item 中,然后填充该 item 变量的字段。价格可以直接读入,因为它是以 float64 类型写入文件的,是一个固定大小的类型。
Item.Price 字段的类型也一样。(我们省略了 readIntFromInt16() 函数,因为它与我们前文所描述的 readIntFromInt32() 函数基本相同。)
至此,我们完成了对自定义二进制数据的读和写。只要小心选择表示长度的整数符号和大小,并将该长度值写在变长值(如切片)的内容之前,那么使用二进制数据进行工作并不难。
Go语言对二进制文件的支持还包括随机访问。这种情况下,我们必须使用 os.OpenFile() 函数来打开文件(而非 os.Open()),并给它传入合理的权限标志和模式(例如,os.O_RDWR 表示可读写)参数。
然后,就可以使用 os.File.Seek() 方法来在文件中定位并读写,或者使用 os.File.ReadAt() 和 os.File.WriteAt() 方法来从特定的字节偏移中读取或者写入数据。
Go语言还提供了其他常用的方法,包括 os.File.Stat() 方法,它返回的 os.FileInfo 包含了文件大小、权限以及日期时间等细节信息。
Go语言zip归档文件的读写操作
Go语言的标准库提供了对几种压缩格式的支持,其中包括 gzip,因此 Go 程序可以无缝地读写 .gz 扩展名的 gzip 压缩文件或非 .gz 扩展名的非压缩文件。此外,标准库也提供了读和 写 .zip 文件、tar 包文件 (.tar 和 .tar.gz ),以及读 .bz2 文件(即 .tar .bz2 文件)的功能。
本节我们将主要介绍 zip 归档文件的读写操作。
创建 zip 归档文件
要使用 Zip 包来压缩文件,我们首先必须打开一个用于写的文件,然后创建一个 zip.Writer 值来往其中写入数据。然后,对于每一个我们希望加入 .zip 归档文件的文件,我们必须读取该文件并将其内容写入 zip.Writer 中。该 pack 程序使用了 createZip() 和 writeFileToZip() 两个函数以这种方式来创建一个 .zip 文件。
func createZip(filename string, files []string) error {
file, err := os.Create(filename)
if err != nil {
return err
}
defer file.Close()
zipper := zip.NewWriter(file)
defer zipper.Close()
for _, name := range files {
if err := writeFileToZip(zipper, name); err != nil {
return err
}
}
return nil
}该 createZip() 函数和 writeFileToZip() 函数都比较简短,因此容易让人觉得应该写入一个函数中。这是不明智的,因为在该 for 循环中我们可能打开一个又一个的文件(即 files 切片中的所有文件),从而可能超出操作系统允许的文件打开数上限。这点我们在前面章节中己有简短的阐述。
当然,我们可以在每次迭代中调用。s.File.Close(),而非延迟执行它,但这样做还必须保证程序无论是否出错文件都必须关闭。因此,最为简便而干净的解决方案是,像这里所做的那样,总是创建一个独立的函数来处理每个独立的文件。
func writeFileToZip(zipper *zip.Writer, filename string) error {
file, err := os.Open(filename)
if err != nil {
return err
}
defer file.Close()
info, err := file.Stat()
if err != nil {
return err
}
header, err := zip.FilelnfoHeader(info)
if err != nil {
return err
}
header.name = sanitizedName(filename)
writer, err := zipper.CreateHeader(header)
if err != nil {
return err
}
_, err = io.Copy(writer, file)
return err
}首先我们打开需要归档的文件以供读取,然后延迟关闭它。这是我们处理文件的老套路了。
接下来,我们调用 os.File.Stat() 方法来取得包含时间戳和权限标志的 os.Fileinfo 值。然后,我们将该值传给 zip.FileInfoHeader() 函数,该函数返回一个 zip.FileHeader 值,其中保存了时间戳、权限以及文件名。在压缩文件中,我们无需使用与原始文件名一样的文件名,因此这里我们使用净化过的文件名来覆盖原始文件名(保存在 zip.FileHeader.Name 字段中)。
头部设置好之后,我们将其作为参数调用 zip.CreateHeader() 函数。这会在 .zip 压缩文件中创建一个项,其中包含头部的时间戳、权限以及文件名,并返回一个 io.Writer,我们可以往其中写入需要被压缩的文件的内容。
为此,我们使用了 io.Copy() 函数,它能够返回所复制的字节数,以及一个为空或者非空的错误值。
如果在任何时候发生错误,该函数就会立即返回并由调用者处理错误。如果最终没有错误发生,那么该 .zip 压缩文件就会包含该给定文件。
func sanitizedName(filename string) string{
if len(filename) > 1 && filename[1] == ':' && runtime.GOOS == *'windows" {
filename = filename[2:]
}
filename = filepath.ToSlash(filename)
filename = strings. TrimLef t( filename, "/.**)
return strings.Replace(filename, ".?/", -1)
}如果一个归档文件中包含的文件带有绝对路径或者含有“..”路径组件,我们就有可能在解开归档的时候意外覆盖本地重要文件。为了降低这种风险,我们对保存在归档文件里每个文件的文件名都做了相应的净化。
该 sanitizedName() 函数会删除路径头部的盘符以及冒号(如果有的话),然后删除头部任何目录分隔符、点号以及任何路径组件,并将文件分隔符强制转换成正向斜线。
解开 zip 归档文件
解开一个 .zip 归档文件与创建一个归档文件一样简单,只是如果归档文件中包含带有路径的文件名,就必须重建目录结构。
func unpackZip(filename string) error {
reader, err := zip.OpenReader(filename)
if err != nil {
return err
}
defer reader.Close()
for _, zipFile := range reader.Reader.File {
name := san it izedName (zipFiJLe.Name)
mode := zipFile.Mode()
if mode.IsDir() {
if err = os.MkdirAl1(name, 0755); err != nil {
return err
}
} else {
if err = unpackZippedFile(name, zipFile); err != nil {
return err
}
}
}
return nil
}该函数打开给定的 .zip 文件用于读取。这里没有使用 os.Open() 函数来打开文件后调用 zip.NewReader(),而是使用 zip 包提供的 zip.OpenReader() 函数,它可以方便地打开并返回一个 *zip.ReadCloser 值让我们使用。
zip.ReadCloser 最为重要的一点是它包含了导出的 zip.Reader 结构体字段,其中包含一个包含指向 zip.File 结构体指针的 []*zip.File 切片,其中的每一项表示 .zip 压缩文件中的一个文件。
我们迭代访问该 reader 的 zip.File 结构体,并创建一个净化过的文件及目录名(使用我们在 pack 程序中用到的 sanitizedName() 函数),以降低覆盖重要文件的风险。
如果遇到一个目录(由 *zip.File 的 os.FileMode 的 IsDir() 方法报告),我们就创建一个目录。os.MkdirAll() 函数传入了有用的属性信息,会自动创建必要的中间目录以创建特定的目标目录,如果目录已经存在则会安全地返回 nil 而不执行任何操作。如果遇到的是一个文件,则交由自定义的 unpackZippedFile() 函数进行解压。
func unpackZippedFile(filename string, zipFile *zipFile) error {
writer, err := os.Create(filename)
if err != nil {
return err
}
defer writer.Close()
reader, err := zipFile.Open()
if err != nil {
return err
}
defer reader.Close()
if _, err = io.Copy(writer, reader); err != nil {
return err
}
if filename == zipFile.Name {
fm.Println(filename)
} else {
fmt.Printf("%s [%s]
", filename, zipFile.Name)
}
return nil
}unpackZippedFile() 函数的作用就是将 .zip 归档文件里的单个文件抽取出来,写到 filename 指定的文件里去。首先它创建所需要的文件,然后,使用 zip.File.Open() 函数打开指定的归档文件,并将数据复制到新创建的文件里去。
最后,如果没有错误发生,该函数会往终端打印所创建文件的文件名,如果处理后的文件名与原始文件名不一样,则将原始文件名包含在方括号中。
值得注意的是,该 *zip.File 类型也有一些其他的方法,如 zip.File.Mode()(在前面的 unpackZip() 函数中已有使用),zip.File.ModTime()(以 time.Time 值返回文件的修改时间)以及返回文件的 os.Fileinfo 值的 zip.Fileinfo()。
Go语言tar归档文件的读写操作
在上一节《创建 .zip 归档文件》中我们介绍了 zip 归档文件的创建和读取,那么接下来介绍一下 tar 归档文件的创建及读取。
创建可压缩的 tar 包
创建 tar 归档文件与创建 .zip 归档文件非常类似,主要不同点在于我们将所有数据都写入相同的 writer 中,并且在写入文件的数据之前必须写入完整的头部,而非仅仅是一个文件名。
我们在该 pack 程序的实现中使用了 createTar() 和 writeFileToTar() 函数。
func createTar(filename string, files []string) error {
file, err := os.Create(filename)
if err != nil {
return err
}
defer file.Close()
var fileWriter io.WriterCloser = file
if strings.HasSuffix(filename, ".gz") {
fileWriter = gzip.NewWriter(file)
defer fileWriter.Close()
}
writer := tar.NewWriter(fileWriter)
defer writer.Close()
for name := range files {
if err := writeFileToTar(writer, name); err != nil {
return err
}
}
return nil
}该函数创建了包文件,而且如果扩展名显示该 tar 包需要被压缩则添加一个 gzip 过滤。gzip.NewWriter() 函数返回一个 gzip.Writer 值,它满足 io.WriteCloser 接口(正如打开的 os.File 一样)。
一旦文件准备好写入,我们创建一个 *tar.Writer 往其中写入数据。然后迭代所有文件并将每一个写入归档文件。
func writeFileToTar(writer *tar.Writer, filename string) error {
file, err := os.Open(filename)
if err != nil {
return err
}
defer file.Close()
stat, err := file.Stat()
if err != nil {
return err
}
header := &tar.Header{
Name: sanitizedName(filename),
Mode: int64(stat.Mode()),
Uid: os.Getuid(),
Gid: os.Getuid(),
Size: stat.Size(),
ModTime: stat.ModTime(),
}
if err = writer.WriteHeader(header); err != nil {
return err
}
err = io.Copy(writer, file)
return err
}函数首先打开需要处理的文件并设置延迟关闭。然后调用 Stat() 方法取得文件的模式、大小以及修改日期/时间。这些信息用于填充 *tar.Header,每个文件都必须创建一个 tar.Header 结构并写入到 tar 归档文件里,(此外,我们设置了头部的用户以及组 ID,这会在类 Unix 系统中用到。)我们必须至少设置头部的文件名(其 Name 字段)以及表示文件大小的 Size 字段,否则这个 .tar 包就是非法的。
当 *tar.Header 结构体创建好后,我们将它写入归档文件,再接着写入文件的内容。
解开 tar 归档文件
解开 tar 归档文件比创建 tar 归档文档稍微简单些。然而,跟解开 .zip 文件一样,如果归档文件中的某些文件名包含路径,必须重建目录结构。
func unpackTar(filename string) error {
file, err := os.Open(filename)
if err != nil {
return err
}
defer file.Close()
var fileReader io.ReadCloser = file
if strings.HasSuffix(filename, ".gz") {
if fileReader, err = gzip.NewReader(file); err != nil {
return err
}
defer fileReader.Close()
}
reader := tar.NewReader(fileReader)
return unpackTarFiles(reader)
}该方法首先按照 Go语言的常规方式打开归档文件,并延迟关闭它。如果该文件使用了 gzip 压缩则创建一个 gzip 解压缩过滤器并延迟关闭它。gzip.NewReader() 函数返回一个 gzip.Reader 值,正如打开一个常规文件(类型为 os.File)一样,它也满足 io.ReadCloser 接口。
设置好了文件 reader 之后,我们创建一个 *tar.Reader 来从中读取数据,并将接下来的工作交给一个辅助函数。
func unpackTarFiles(reader *tar.Reader) error {
for {
header, err := reader.Next()
if err != nil {
if err == io.EOF {
return nil // OK
}
return err
}
filename := sanitizedName(header.Name)
switch header.Typeflag {
case tar.TypeDir:
if err = os.MkdirAll(filename, 0755); err != nil {
return err
}
case tar.TypeReq:
if err = unpackTarFile(filename, heaer.Name, reader); err != nil{
return err
}
}
}
return nil
}该函数使用一个无限循环来迭代读取归档文档中的每一项,直到遇到 io.EOF(或者直到遇到错误)。tar.Next() 方法返回压缩文档中第一项或者下一项的 *tar.Header 结构体,失败则报告错误。如果错误值为 io.EOF,则意味着读取文件结束,因此返回一个空的错误值。
得到 *tar.Header 后,根据该头部的 Name 字段创建一个净化过的文件名。然后,通过该项的类型标记来进行 switch。对于该简单示例,我们只考虑目录和常规文件,但实际上,归档文件中还可以包含许多其他类型的项(如符号链接)。
如果该项是一个目录,我们按照处理 .zip 文件时所采用的方法创建该目录。而如果该项是一个常规文件,我们将其工作交给另一个辅助函数。
func unpackTarFile(filename, tarFilename string, reader *tar.Reader) error{
writer, err := os.Create(filename)
if err != nil {
return err
}
defer writer.Close()
if err := io.Copy(writer, reader); err != nil {
return err
}
if filename == tarFilename {
fmt.Printin(filename)
} else {
fmt.Printf("%s [%s]
", filename, tarFilename)
}
return nil
}针对归档文件中的每一项,该函数创建了一个新文件,并延迟关闭它。然后,它将归档文件的下一项数据复制到该文件中。同时,正如在 unpackZippedFile() 函数中所做的那样,我们将刚创建文件的文件名打印到终端,如果净化过的文件名与原始文件名不同,则在方括号中给出原始文件名。
至此,我们完成了对压缩和归档文件及常规文件处理的介绍。Go语言使用 io.Reader、io.ReadCloser、io.Writer 和 io.WriteCloser 等接口处理文件的方式让开发者可以使用相同的编码模式来读写文件或者其他流(如网络流或者甚至是字符串),从而大大降低了难度。
Go语言使用buffer读取文件
在下面的例子中,我们联合使用了缓冲读取文件和命令行 flag 解析这两项技术。如果不加参数,那么你输入什么屏幕就打印什么。
参数被认为是文件名,如果文件存在的话就打印文件内容到屏幕。命令行执行 cat test 测试输出。
package main
import (
"bufio"
"flag"
"fmt"
"io"
"os"
)
func cat(r *bufio.Reader) {
for {
buf, err := r.ReadBytes('
')
if err == io.EOF {
break
}
fmt.Fprintf(os.Stdout, "%s", buf)
}
return
}
func main() {
flag.Parse()
if flag.NArg() == 0 {
cat(bufio.NewReader(os.Stdin))
}
for i := 0; i < flag.NArg(); i++ {
f, err := os.Open(flag.Arg(i))
if err != nil {
fmt.Fprintf(os.Stderr, "%s:error reading from %s: %s
", os.Args[0], flag.Arg(i), err.Error())
continue
}
cat(bufio.NewReader(f))
}
}Go语言使用切片读写文件
切片提供了 Go语言中处理 I/O 缓冲的标准方式,下面 cat 函数的第二版中,在一个切片缓冲内使用无限 for 循环(直到文件尾部 EOF)读取文件,并写入到标准输出(os.Stdout)。
func cat(f *os.File) {
const NBUF = 512
var buf [NBUF]byte
for {
switch nr, err := f.Read(buf[:]); true {
case nr < 0:
fmt.Fprintf(os.Stderr, "cat: error reading: %s
", err.Error())
os.Exit(1)
case nr == 0: // EOF
return
case nr > 0:
if nw, ew := os.Stdout.Write(buf[0:nr]); nw != nr {
fmt.Fprintf(os.Stderr, "cat: error writing: %s
", ew.Error())
}
}
}
}下面的代码使用了 os 包中的 os.file 和 Read 方法;与上一节示例代码具有同样的功能。
package main
import (
"flag"
"fmt"
"os"
)
func cat(f *os.File) {
const NBUF = 512
var buf [NBUF]byte
for {
switch nr, err := f.Read(buf[:]); true {
case nr < 0:
fmt.Fprintf(os.Stderr, "cat: error reading: %s
", err.Error())
os.Exit(1)
case nr == 0: // EOF
return
case nr > 0:
if nw, ew := os.Stdout.Write(buf[0:nr]); nw != nr {
fmt.Fprintf(os.Stderr, "cat: error writing: %s
", ew.Error())
}
}
}
}
func main() {
flag.Parse() // 扫描arg列表并设置标志
if flag.NArg() == 0 {
cat(os.Stdin)
}
for i := 0; i < flag.NArg(); i++ {
f, err := os.Open(flag.Arg(i))
if f == nil {
fmt.Fprintf(os.Stderr, "cat: can't open %s: error %s
", flag.Arg(i), err)
os.Exit(1)
}
cat(f)
f.Close()
}
}示例:并发目录遍历
在本节中,我们构建一个程序,根据命令行指定的输入,报告一个或多个目录的磁盘使用情况,类似于 UNIX du 命令。大多数的工作由下面的 walkDir 函数完成,它使用 dirents 辅助函数来枚举目录中的条目。
// wakjDir 递归地遍历以 dir 为根目录的整个文件树
// 并在 filesizes 上发送每个已找到的文件的大小
func walkDir(dir string, fileSizes chan<- int64) {
for _, entry := range dirents(dir) {
if entry.IsDir() {
subdir := filepath.Join(dir, entry.Name())
walkDir(subdir, fileSizes)
} else {
fileSizes <- entry.Size()
}
}
}
// dirents 返回 dir 目录中的条目
func dirents(dir string) []os.FileInfo {
entries, err := ioutil.ReadDir(dir)
if err != nil {
fmt.Fprintf(os.Stderr, "du1: %v
", err)
return nil
}
return entries
}ioutil.ReadDir 函数返回一个 os.FileInfo 类型的 slice,针对单个文件同样的信息可以通过调用 os.Stat 函数来返回。对每一个子目录,walkDir 递归调用它自己,对于每一个文件,walkDir 发送一条消息到 fileSizes 通道。消息是文件所占用的字节数。
如下所示,main 函数使用两个 goroutine。后台 goroutine 调用 walkDir 遍历命令行上指定的每一个目录,最后关闭 fileSizes 通道。主 goroutine 计算从通道中接收的文件的大小的和,最后输出总数。
// du1 计算目录中文件占用的磁盘空间大小
package main
import (
"flag"
"fmt"
"io/ioutil"
"os"
"path/filepath"
)
func main() {
// 确定初始目录
flag.Parse()
roots := flag.Args()
if len(roots) == 0 {
roots = []string{"."}
}
// 遍历文件树
fileSizes := make(chan int64)
go func() {
for _, root := range roots {
walkDir(root, fileSizes)
}
close(fileSizes)
}()
// 输出结果
var nfiles, nbytes int64
for size := range fileSizes {
nfiles++
nbytes += size
}
printDiskUsage(nfiles, nbytes)
}
func printDiskUsage(nfiles, nbytes int64) {
fmt.Printf("%d files %.1f GB
", nfiles, float64(nbytes)/1e9)
}在输出结果前,程序等待较长时间:
$ go build gopl>io/ch8/du1
$ ./du1 $HOME /usr/bin/etc
213201 files 62.7 GB如果程序可以通知它的进度,将会更友好。但是仅把 printDiskUsage 调用移动到循环内部会使它输出数千行结果。
下面这个 du 的变种周期性地输出总数,只有在 -v 标识指定的时候才输出,因为不是所有的用户都想看进度消息。后台 goroutine 依然从根部开始迭代。
主 goroutine 现在使用一个计时器每 500ms 定期产生事件,使用一个 select 语句或者等待一个关于文件大小的消息,这时它更新总数,或者等待一个计时事件,这时它输出当前的总数。如果 -v 标识没有指定,tick 通道依然是 nil,它对应的情况在 select 中实际上被禁用。
var verbose = flag.Bool("v", false, "show verbose progress messages")
func main() {
// ...启动后台 goroutine...
// 确定初始目录
flag.Parse()
roots := flag.Args()
if len(roots) == 0 {
roots = []string{"."}
}
// 遍历文件树
fileSizes := make(chan int64)
go func() {
for _, root := range roots {
walkDir(root, fileSizes)
}
close(fileSizes)
}()
// 定期打印结果
var tick <-chan time.Time
if *verbose {
tick = time.Tick(500 * time.Millisecond)
}
var nfiles, nbytes int64
loop:
for {
select {
case size, ok := <-fileSizes:
if !ok {
break loop // fileSizes 关闭
}
nfiles++
nbytes += size
case <-tick:
printDiskUsage(nfiles, nbytes)
}
}
printDiskUsage(nfiles, nbytes) // 最终总数
}因为这个程序没有使用 range 循环,所以第一个 select 情况必须显式判断 fileSizes 通道是否已经关闭,使用两个返回值的形式进行接收操作。如果通道已经关闭,程序退出循环。标签化的 break 语句将跳出 select 和 for 循环的逻辑;没有标签的 break 只能跳出 select 的逻辑,导致循环的下一次迭代。
程序提供给我们一个从容不迫的更新流:
$ go build gop1.io/ch8/du2
$ ./du2 -v $HOME/usr/bin/etc
28608 files 8.3 GB
54147 files 10.3 GB
93591 files 15.1 GB
127169 files 52.9 GB
175931 files 62.2 GB
213201 files 62.7 GB但是它依然耗费太长的时间。这里没有理由不能并发调用 walkDir 从而充分利用磁盘系统的并行机制。第三个版本的 du 为每一个 walkDir 的调用创建一个新的 goroutine。它使用 sync.WaitGroup 来为当前存活的 walkDir 调用计数,一个关闭者 goroutine 在计数器减为 0 的时候关闭 fileSizes 通道。
func main() {
// ...确定根目录...
flag.Parse()
// 确定初始目录
roots := flag.Args()
if len(roots) == 0 {
roots = []string{"."}
}
// 并行遍历每一个文件树
fileSizes := make(chan int64)
var n sync.WaitGroup
for _, root := range roots {
n.Add(1)
go walkDir(root, &n, fileSizes)
}
go func() {
n.Wait()
close(fileSizes)
}()
// 定期打印结果
var tick <-chan time.Time
if *verbose {
tick = time.Tick(500 * time.Millisecond)
}
var nfiles, nbytes int64
loop:
for {
select {
case size, ok := <-fileSizes:
if !ok {
break loop // fileSizes 关闭
}
nfiles++
nbytes += size
case <-tick:
printDiskUsage(nfiles, nbytes)
}
}
printDiskUsage(nfiles, nbytes) // 最终总数
}
func walkDir(dir string, n *sync.WaitGroup, fileSizes chan<- int64) {
defer n.Done()
for _, entry := range dirents(dir) {
if entry.IsDir() {
n.Add(1)
subdir := filepath.Join(dir, entry.Name())
go walkDir(subdir, n, fileSizes)
} else {
fileSizes <- entry.Size()
}
}
}因为程序在高峰时创建数千个 goroutine,所以我们不得不修改 dirents 函数来使用计数信号量,以防止它同时打开太多的文件:
// sema是一个用于限制目录并发数的计数信号量
var sema = make(chan struct{}, 20)
// dirents返回directory目录中的条目
func dirents(dir string) []os.FileInfo {
sema <- struct{}{} // 获取令牌
defer func() { <-sema }() // 释放令牌
entries, err := ioutil.ReadDir(dir)
if err != nil {
fmt.Fprintf(os.Stderr, "du: %v
", err)
return nil
}
return entries
}尽管系统与系统之间有很多的不同,但是这个版本的速度比前一个版本快几倍。
示例:从INI配置文件中读取需要的值
INI 文件格式是一种古老的配置文件格式。一些操作系统、虚幻游戏引擎、GIT 版本管理中都在使用 INI 文件格式。下面用从 GIT 版本管理的配置文件中截取的一部分内容,展示 INI 文件的样式。
[core]
repositoryformatversion = 0
filemode = false
bare = false
logallrefupdates = true
symlinks = false
ignorecase = true
hideDotFiles = dotGitOnly
[remote "origin"]
url = https://github.com/davyxu/cellnet
fetch = +refs/heads/*:refs/remotes/origin/*
[branch "master"]
remote = origin
merge = refs/heads/masterINI 文件的格式
INI 文件由多行文本组成,整个配置由“[]”拆分为多个“段”(section)。每个段中又以“=”分割为“键”,和“值”。
INI 文件以“;”置于行首视为注释,本行将不会被处理和识别。INI 文件格式如下:
[sectionl]
key1=value1
key2=value2
[section2]从 INI 文件中取值的函数
熟悉了 INI 文件的格式后,开始准备读取 INI 文件,并从文件中获取需要的数据。完整的示例代码如下所示:
package main
import (
"bufio"
"fmt"
"os"
"strings"
)
// 根据文件名,段名,键名获取ini的值
func getValue(filename, expectSection, expectKey string) string {
// 打开文件
file, err := os.Open(filename)
// 文件找不到,返回空
if err != nil {
return ""
}
// 在函数结束时,关闭文件
defer file.Close()
// 使用读取器读取文件
reader := bufio.NewReader(file)
// 当前读取的段的名字
var sectionName string
for {
// 读取文件的一行
linestr, err := reader.ReadString('
')
if err != nil {
break
}
// 切掉行的左右两边的空白字符
linestr = strings.TrimSpace(linestr)
// 忽略空行
if linestr == "" {
continue
}
// 忽略注释
if linestr[0] == ';' {
continue
}
// 行首和尾巴分别是方括号的,说明是段标记的起止符
if linestr[0] == '[' && linestr[len(linestr)-1] == ']' {
// 将段名取出
sectionName = linestr[1 : len(linestr)-1]
// 这个段是希望读取的
} else if sectionName == expectSection {
// 切开等号分割的键值对
pair := strings.Split(linestr, "=")
// 保证切开只有1个等号分割的简直情况
if len(pair) == 2 {
// 去掉键的多余空白字符
key := strings.TrimSpace(pair[0])
// 是期望的键
if key == expectKey {
// 返回去掉空白字符的值
return strings.TrimSpace(pair[1])
}
}
}
}
return ""
}
func main() {
fmt.Println(getValue("example.ini", "remote "origin"", "fetch"))
fmt.Println(getValue("example.ini", "core", "hideDotFiles"))
}本例并不是将整个 INI 文件读取保存后再获取需要的字段数据并返回,这里使用 getValue() 函数,每次从指定文件中找到需要的段(Section)及键(Key)对应的值。
getValue() 函数的声明如下:
func getValue(filename, expectSection, expectKey string) string参数说明如下。
filename:INI 文件的文件名。
expectSection:期望读取的段。
expectKey:期望读取段中的键。
getValue() 函数的实际使用例子参考代码如下:
func main() {
fmt.Println(getValue("example.ini", "remote "origin"", "fetch"))
fmt.Println(getValue("example.ini", "core", "hideDotFiles"))
}运行完整代码后输出如下:
+refs/heads/*:refs/remotes/origin/*
dotGitOnly代码输出中,“+refs/heads/:refs/remotes/origin/”表示 INI 文件中 "remote" 和 "origin" 的 "fetch" 键对应的值:dotGitOnly 表示 INI 文件中 "core" 段中的键为 "hideDotFiles" 的值。
注意代码第 2 行中,由于段名中包含双引号,所以使用“\”进行转义。
getValue() 函数的逻辑由 4 部分组成:即读取文件、读取行文本、读取段和读取键值组成。接下来分步骤了解 getValue() 函数的详细处理过程。
读取文件
Go语言的 OS 包中提供了文件打开函数 os.Open()。文件读取完成后需要及时关闭,否则文件会发生占用,系统无法释放缓冲资源。参考下面代码:
// 打开文件
file, err := os.Open(filename)
// 文件找不到,返回空
if err != nil {
return ""
}
// 在函数结束时,关闭文件
defer file.Close()代码说明如下:
第 2 行,filename 是由 getValue() 函数参数提供的 INI 的文件名。使用 os.Open() 函数打开文件,如果成功打开,会返回文件句柄,同时返回打开文件时可能发生的错误:err。
第 5 行,如果文件打开错误,err 将不为 nil,此时 getValue() 函数返回一个空的字符串,表示无法从给定的 INI 文件中获取到需要的值。
第 10 行,使用 defer 延迟执行函数,defer 并不会在这一行执行,而是延迟在任何一个 getValue() 函数的返回点,也就是函数退出的地方执行。调用 file.Close() 函数后,打开的文件就会被关闭并释放系统资源。
INI 文件已经打开了,接下来就可以开始读取 INI 的数据了。
读取行文本
INI 文件的格式是由多行文本组成,因此需要构造一个循环,不断地读取 INI 文件的所有行。Go语言总是将文件以二进制格式打开,通过不同的读取方式对二进制文件进行操作。Go语言对二进制读取有专门的代码抽象,bufio 包即可以方便地以比较常见的方式读取二进制文件。
// 使用读取器读取文件
reader := bufio.NewReader(file)
// 当前读取的段的名字
var sectionName string
for {
// 读取文件的一行
linestr, err := reader.ReadString('
')
if err != nil {
break
}
// 切掉行的左右两边的空白字符
linestr = strings.TrimSpace(linestr)
// 忽略空行
if linestr == "" {
continue
}
// 忽略注释
if linestr[0] == ';' {
continue
}
//读取段和键值的代码
//...
}代码说明如下:
第 2 行,使用 bufio 包提供的 NewReader() 函数,传入文件并构造一个读取器。
第 5 行,提前声明段的名字字符串,方便后面的段和键值读取。
第 7 行,构建一个读取循环,不断地读取文件中的每一行。
第 10 行,使用 reader.ReadString() 从文件中读取字符串,直到碰到“
”,也就是行结束。这个函数返回读取到的行字符串(包括“
”)和可能的读取错误 err,例如文件读取完毕。
第 16 行,每一行的文本可能会在标识符两边混杂有空格、回车符、换行符等不可见的空白字符,使用 strings.TrimSpace() 可以去掉这些空白字符。
第 19 行,可能存在空行的情况,继续读取下一行,忽略空行。
第 24 行,当行首的字符为“;”分号时,表示这一行是注释行,忽略一整行的读取。
读取 INI 文本文件时,需要注意各种异常情况。文本中的空白符就是经常容易忽略的部分,空白符在调试时完全不可见,需要打印出字符的 ASCII 码才能辨别。
抛开各种异常情况拿到了每行的行文本 linestr 后,就可以方便地读取 INI 文件的段和键值了。
读取段
行字符串 linestr 已经去除了空白字符串,段的起止符又以“[”开头, 以“]”结尾,因此可以直接判断行首和行尾的字符串匹配段的起止符匹配时读取的是段,如下图所示。
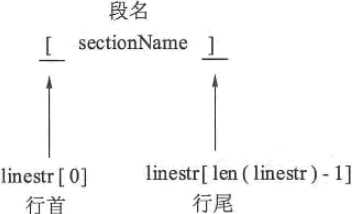
图:INI 文件的段名解析
此时,段只是一个标识,而无任何内容,因此需要将段的名字取出保存在 sectionName(己在之前的代码中定义)中,待读取段后面的键值对时使用。
// 行首和尾巴分别是方括号的,说明是段标记的起止符
if linestr[0] == '[' && linestr[len(linestr)-1] == ']' {
// 将段名取出
sectionName = linestr[1 : len(linestr)-1]
// 这个段是希望读取的
}代码说明如下:
第 2 行,linestr[0] 表示行首的字符,len(linestr)-1 取出字符串的最后一个字符索引随后取出行尾的字符。根据两个字符串是否匹配方括号,断定当前行是否为段。
第 5 行,linestr 两边的“[”和“]”去掉,取出中间的段名保存在 sectionName 中,留着后面的代码用。
读取键值
这里代码紧接着前面的代码。当前行不是段时(不以“[”开头),那么行内容一定是键值对。别忘记此时 getValue() 的参数对段有匹配要求。找到能匹配段的键值对后,开始对键值对进行解析,参考下面的代码:
else if sectionName == expectSection {
// 切开等号分割的键值对
pair := strings.Split(linestr, "=")
// 保证切开只有1个等号分割的简直情况
if len(pair) == 2 {
// 去掉键的多余空白字符
key := strings.TrimSpace(pair[0])
// 是期望的键
if key == expectKey {
// 返回去掉空白字符的值
return strings.TrimSpace(pair[1])
}
}
}代码说明如下:
第 1 行,当前的段匹配期望的段时,进行后面的解析。
第 4 行,对行内容(linestr)通过 strings.Split() 函数进行切割,INI 的键值对使用“=”分割,分割后,strings.Split() 函数会返回字符串切片,类型为 []string。这里只考虑一个“=”的情况,因此被分割后,strings.Split() 函数返回的字符串切片有 2 个元素。
第 7 行,只考虑切割出 2 个元素的情况。其他情况会被忽略, 键值如没有“=”、行中多余一个“=”等情况。
第 10 行,pair[O] 表示“=”左边的键。使用 strings.TrimSpace() 函数去掉空白符,如下图所示。
第 13 行,键值对切割出后,还需要判断键是否为期望的键。
第 16 行,匹配期望的键时,将 pair[1] 中保存的键对应的值经过去掉空白字符处理后作为函数返回值返回。
图:lNI 的键值解析
Go语言文件的写入、追加、读取、复制操作
Go语言中 os 包下面有 OpenFile 函数的原型如下所示:
func OpenFile(name string, flag int,perm FileMode)(file *File,err error)其中 name 是文件的文件名,如果不是当前运行程序的路径下,需要加上路径,flag 是文件的处理的参数,是 int 类型的不同系统具体是多少可能不同,但是作用是相同的。给出通常会用到的几个常数:
- O_RDONLY:只读
- O_WRONLY:只写
- O_RDWR:读写
- O_APPEND:追加
- O_CREATE:不存在,则创建
- O_EXCL:如果文件存在,且标定了 O_CREATE 的话,则产生一个错误
- O_TRUNG:如果文件存在,且它成功地被打开为只写或读写方式,将其长度裁剪唯一。(覆盖)
- O_NOCTTY:如果文件名代表一个终端设备,则不把该设备设为调用进程的控制设备
- O_NONBLOCK:如果文件名代表一个 FIFO,或一个块设备,字符设备文件,则在以后的文件及 I/O 操作中置为非阻塞模式
- O_SYNC:当进行一系列写操作时,每次都要等待上次的 I/O 操作完成再进行。
【示例 1】:创建一个新文件,写入 5 句:hello,Go语言
package main
import (
"fmt"
"os"
"bufio"
)
func main() {
//创建一个新文件,写入内容 5句 hello,Go语言
filePath := "d:/code/abc.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY | os.O_CREATE, 0666)
if err != nil{
fmt.Println("open file err",err)
}
//及时关闭file句柄
defer file.Close()
//写入文件时,使用带缓存的 *Writer
write := bufio.NewWriter(file)
for i := 0; i < 5; i++ {
write.WriteString("hello,Go语言
")
}
//Flush将缓存的文件真正写入到文件中
write.Flush()
}执行之后,可以看出文件已被写入:
【示例 2】:打开一个存在的文件,在原来的内容追加内容:ABC!
package main
import (
"fmt"
"os"
"bufio"
)
func main() {
filePath := "d:/code/abc.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY | os.O_APPEND, 0666)
if err != nil{
fmt.Println("open file err",err)
}
//及时关闭file句柄
defer file.Close()
//写入文件时,使用带缓存的 *Writer
write := bufio.NewWriter(file)
for i := 0; i < 5; i++ {
write.WriteString("ABC!
")
}
//Flush将缓存的文件真正写入到文件中
write.Flush()
}执行之后,发现内容追加成功:
【示例 3】:打开一个存在的文件,将原来的内容读出来,显示在终端,并且追加 5 句:hello,C语言中文网。
package main
import (
"fmt"
"os"
"bufio"
"io"
)
func main() {
filePath := "d:/code/abc.txt"
file, err := os.OpenFile(filePath, os.O_RDWR | os.O_APPEND, 0666)
if err != nil{
fmt.Println("open file err",err)
}
//及时关闭file句柄
defer file.Close()
//读原来文件的内容,并且显示在终端
reader := bufio.NewReader(file)
for {
str, err := reader.ReadString('
')
if err == io.EOF {
break
}
fmt.Print(str)
}
//写入文件时,使用带缓存的 *Writer
write := bufio.NewWriter(file)
for i := 0; i < 5; i++ {
write.WriteString("hello,C语言中文网。
")
}
//Flush将缓存的文件真正写入到文件中
write.Flush()
}执行之后,原来的文件在控制台读取成功,并且在文件中追加成功:
【示例 4】:编写一个程序,将一个文件的内容复制到另外一个文件(注:这两个文件都已存在)
package main
import (
"fmt"
"io/ioutil"
)
func main() {
file1Path := "d:/code/abc.txt"
file2Path := "d:/code/defer.txt"
data, err := ioutil.ReadFile(file1Path)
if err != nil{
fmt.Printf("open file err=%v
",err)
return
}
err = ioutil.WriteFile(file2Path, data,0666)
if err != nil{
fmt.Printf("open file err=%v
",err)
}
}执行,发现内容复制成功:
Go语言文件锁操作
我们使用Go语言开发一些程序的时候,往往出现多个进程同时操作同一份文件的情况,这很容易导致文件中的数据混乱。我们需要采用一些手段来平衡这些冲突:需要锁操作来保证数据的完整性,这里介绍的针对文件的锁,称之为“文件锁”flock。
对于 flock,我们最常见的例子就是 nginx,进程起来后就会把当前的 PID 写入这个文件,当然如果这个文件已经存在了,也就是前一个进程还没有退出,那么 Nginx 就不会重新启动。
flock 是对于整个文件的建议性锁。也就是说,如果一个进程在一个文件(inode)上放了锁,那么其它进程是可以知道的。(建议性锁不强求进程遵守。)最棒的一点是,它的第一个参数是文件描述符,在此文件描述符关闭时,锁会自动释放。而当进程终止时,所有的文件描述符均会被关闭。所以很多时候就不用考虑类似原子锁解锁的事情。
在具体介绍前,先上代码
package main
import (
"fmt"
"os"
"sync"
"syscall"
"time"
)
//文件锁
type FileLock struct {
dir string
f *os.File
}
func New(dir string) *FileLock {
return &FileLock{
dir: dir,
}
}
//加锁
func (l *FileLock) Lock() error {
f, err := os.Open(l.dir)
if err != nil {
return err
}
l.f = f
err = syscall.Flock(int(f.Fd()), syscall.LOCK_EX|syscall.LOCK_NB)
if err != nil {
return fmt.Errorf("cannot flock directory %s - %s", l.dir, err)
}
return nil
}
//释放锁
func (l *FileLock) Unlock() error {
defer l.f.Close()
return syscall.Flock(int(l.f.Fd()), syscall.LOCK_UN)
}
func main() {
test_file_path, _ := os.Getwd()
locked_file := test_file_path
wg := sync.WaitGroup{}
for i := 0; i < 10; i++ {
wg.Add(1)
go func(num int) {
flock := New(locked_file)
err := flock.Lock()
if err != nil {
wg.Done()
fmt.Println(err.Error())
return
}
fmt.Printf("output : %d
", num)
wg.Done()
}(i)
}
wg.Wait()
time.Sleep(2 * time.Second)
}上面的代码我们演示了同时启动 10 个 goroutinue,但在程序运行过程中,只有一个 goroutine 能获得文件锁(flock)。其它的 goroutinue 在获取不到 flock 后,会抛出异常的信息。这样即可达到同一文件在指定的周期内只允许一个进程访问的效果。
代码中文件锁的具体调用:
syscall.Flock(int(f.Fd()), syscall.LOCK_EX|syscall.LOCK_NB)我们采用了 syscall.LOCK_EX,syscall.LOCK_NB,这是什么意思呢?
flock,建议性锁,不具备强制性。一个进程使用 flock 将文件锁住,另一个进程可以直接操作正在被锁的文件,修改文件中的数据,原因在于 flock 只是用于检测文件是否被加锁,针对文件已经被加锁,另一个进程写入数据的情况,内核不会阻止这个进程的写入操作,也就是建议性锁的内核处理策略。
flock 主要三种操作类型:
- LOCK_SH,共享锁,多个进程可以使用同一把锁,常被用作读共享锁;
- LOCK_EX,排他锁,同时只允许一个进程使用,常被用作写锁;
- LOCK_UN,释放锁;
进程使用 flock 尝试锁文件时,如果文件已经被其他进程锁住,进程会被阻塞直到锁被释放掉,或者在调用 flock 的时候,采用 LOCK_NB 参数。在尝试锁住该文件的时候,发现已经被其他服务锁住,会返回错误,errno 错误码为 EWOULDBLOCK。
flock 锁的释放非常具有特色,即可调用 LOCK_UN 参数来释放文件锁,也可以通过关闭 fd 的方式来释放文件锁(flock 的第一个参数是 fd),意味着 flock 会随着进程的关闭而被自动释放掉。
flock 其中的一个使用场景为:检测进程是否已经存在。
以上是关于12. Go 语言文件处理的主要内容,如果未能解决你的问题,请参考以下文章