Flink使用——记一次Flink Session任务反复重启
Posted love-yh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink使用——记一次Flink Session任务反复重启相关的知识,希望对你有一定的参考价值。
前言
环境: JDK 1.8+Flink 1.6+Hadoop 2.7.3
文中若有表述不正确,欢迎大伙留言指出,谢谢!
1、现象
使用yarn-session在yarn上启动flink集群并提交任务后,在Flink Web UI 上发现任务的state个数每十分钟左右会从0到10左右后又重复从0开始,但输出的结果没有问题。
2、分析过程
2.1 检查checkpoint过程(不是最终原因)
最开始以为是checkpoint的状态(RockDB方式)未设置好,检查配置未发现问题。使用yarn logs命令查找任务日志,发现没有没有Error,详细分析日志发现:
1 INFO:yarn.YarnApplicationMasterRunner:RECEIVER SIGNAL 15: SIGTERM. Shutting down as requested
操作系统为什么会发送请求kill掉容器了?从日志中没有找到有用信息,在网上查找前辈们的使用经验[1],发现当任务逻辑中有keyBy(key),其key变化时会导致窗口状态无法清理导致物理内存溢出容器被kill,但是我们的checkpoint的状态个数到10左右就又重新从0开始,而且每个state的大小只有几KB,所以可以排除是因为物理内存溢出导致的。
2.2 虚拟内存溢出(不是最终原因)
既然从任务日志本身没有发现问题,容器又被kill掉,所以打算从容器的日志出发去分析原因。分析容器本身的日志,就要去查看yarn的对应日志,通过任务日志中获取的容器信息找到集群对应的节点然后再分析对应时间短的容器日志,发现虚拟内存超过了申请,如下:

虚拟内存一般是申请内存的2.1倍(Hadoop中默认),博主为每个容器申请的内存为1G,所以对应的虚拟内存是2.1G,遇到这种情况最好的解决办法是扩大申请的资源比如2G,扩大资源后发现问题还是存在。为什么会用到这么多虚拟内存了?组里的前辈提示可能是JDK 1.8内存模型的原因,但是申请1G之前是可以测试的,而且我测试仅使用yarn-session在yarn上申请Flink集群,但不提交任务,问题还是存在,所以没有沿着这个方向去分析(后续还是得扩展学习的)。
在yarn的任务页面查看任务的状态时发现其有多个Attempt ID,其对应web UI和端口都是变化的,具体如下图:
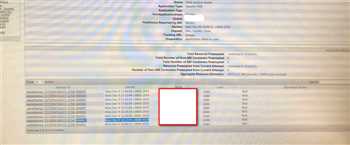
AM为什么会重启这么多次了?AM的重启的最大次数是由yarn.resourcemanager.am.max-attempts确定,而集群中该参数为2。说明该参数未生效。
2.3 继续容器日志分析
继续分析容器日志发现如下:

容器10min会timeout被干掉,该值是由yarn上yarn.resourcemanager.container.liveness-monitor.interval-ms=600000ms(yarn-default.xml)确定的[2],到此,10min state重启的原因找到了,但是为什么AM重启的次数未被限制住了?在日志中找到信息如下:

从日志中发现,任务重启次数是统计在10秒钟中任务重启的次数,超过10重启的次数就不会被统计,该值在Flink中是由akka.ask.timeout=10s决定的[3]。到此,AM多次重启的原因也找到了。但是,是什么原因导致的AM失败还是没有找到,后台找到ERROR如下:

该信息仅显示NodeManager的心跳信息未上报成功,但原因未知。
3、尝试输出yarn对应类的Debug信息
设置是在浏览器中yarn的ResourceManager active 节点的8088端口后加上logLevel,如:127.0.0.1:8088/logLevel,在页面上指定类名和日志级别,然后在对应节点的ResourceManager日志中就可以找到对应的debug日志。本问题中设置类名为org.apache.hadoop.yarn.server.resourcemanager.mnode,结果没有找到有用信息。
4、解决办法
在排除问题过程中发现同集群上Spark任务AM的attempt ID已经重启到1600+了,所以到此判断是Yarn的问题导致,但是什么问题还是没有找到。
解决办法:重启yarn集群即可。
后记:
哎,真是一顿操作猛如虎啊,到头啥原因还是没有定位出来。不过在这个过程中涉及的思考过程和涉及的参数还是值得记录下来的,所以有了这篇博客,对不住了各位看官,愿勿恼!
Ref:
[1]https://blog.csdn.net/TripleDangClark/article/details/89146895
[2]http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
[3]https://ci.apache.org/projects/flink/flink-docs-release-1.6/ops/jobmanager_high_availability.html
以上是关于Flink使用——记一次Flink Session任务反复重启的主要内容,如果未能解决你的问题,请参考以下文章