tensorflow的MNIST教程
Posted liangxiyang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了tensorflow的MNIST教程相关的知识,希望对你有一定的参考价值。
(ps:根据自己的理解,提炼了一下官方文档的内容,错误的地方希望大佬们多多指正。。。。。)
0x01:数据集的获取和表示
数据集的获取,可以通过代码自动下载。这里的数据就是各种手写数字图片和图片对应的标签(告诉我们这个数字是几,比如下面的是5,0,4,1)。
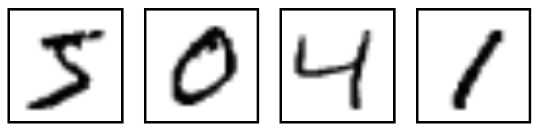
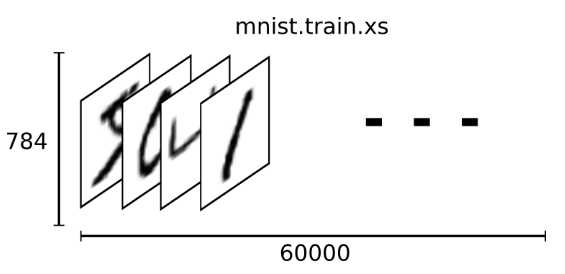
下载下来的数据集被分成两部分:60000行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test),而每一个数据集都有两部分组成:一张包含手写数字的图片(xs)和一个对应的标签(ys)。训练数据集和测试数据集都包含xs和ys,比如训练数据集的图片是 mnist.train.images ,训练数据集的标签是 mnist.train.labels。根据图片像素点把图片展开为向量,再进一步操作,识别图片上的数值。那这60000个训练数据集是怎么表示的呢?在MNIST训练数据集中,mnist.train.images 是一个形状为 [60000, 784] 的张量(至于什么是张量,小伙伴们可以手都搜一下,加深一下印象),第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。在此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于0和1之间。
0x02:代码运行
代码分为两部分,一个是用于下载数据的 input_data.py, 另一个是主程序 mnist.py,


1 # Copyright 2015 Google Inc. All Rights Reserved. 2 # 3 # Licensed under the Apache License, Version 2.0 (the "License"); 4 # you may not use this file except in compliance with the License. 5 # You may obtain a copy of the License at 6 # 7 # http://www.apache.org/licenses/LICENSE-2.0 8 # 9 # Unless required by applicable law or agreed to in writing, software 10 # distributed under the License is distributed on an "AS IS" BASIS, 11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 12 # See the License for the specific language governing permissions and 13 # limitations under the License. 14 # ============================================================================== 15 """Functions for downloading and reading MNIST data.""" 16 from __future__ import absolute_import 17 from __future__ import division 18 from __future__ import print_function 19 import gzip 20 import os 21 import tensorflow.python.platform 22 import numpy 23 from six.moves import urllib 24 from six.moves import xrange # pylint: disable=redefined-builtin 25 import tensorflow as tf 26 SOURCE_URL = ‘http://yann.lecun.com/exdb/mnist/‘ 27 def maybe_download(filename, work_directory): 28 """Download the data from Yann‘s website, unless it‘s already here.""" 29 if not os.path.exists(work_directory): 30 os.mkdir(work_directory) 31 filepath = os.path.join(work_directory, filename) 32 if not os.path.exists(filepath): 33 filepath, _ = urllib.request.urlretrieve(SOURCE_URL + filename, filepath) 34 statinfo = os.stat(filepath) 35 print(‘Successfully downloaded‘, filename, statinfo.st_size, ‘bytes.‘) 36 return filepath 37 def _read32(bytestream): 38 dt = numpy.dtype(numpy.uint32).newbyteorder(‘>‘) 39 return numpy.frombuffer(bytestream.read(4), dtype=dt)[0] 40 def extract_images(filename): 41 """Extract the images into a 4D uint8 numpy array [index, y, x, depth].""" 42 print(‘Extracting‘, filename) 43 with gzip.open(filename) as bytestream: 44 magic = _read32(bytestream) 45 if magic != 2051: 46 raise ValueError( 47 ‘Invalid magic number %d in MNIST image file: %s‘ % 48 (magic, filename)) 49 num_images = _read32(bytestream) 50 rows = _read32(bytestream) 51 cols = _read32(bytestream) 52 buf = bytestream.read(rows * cols * num_images) 53 data = numpy.frombuffer(buf, dtype=numpy.uint8) 54 data = data.reshape(num_images, rows, cols, 1) 55 return data 56 def dense_to_one_hot(labels_dense, num_classes=10): 57 """Convert class labels from scalars to one-hot vectors.""" 58 num_labels = labels_dense.shape[0] 59 index_offset = numpy.arange(num_labels) * num_classes 60 labels_one_hot = numpy.zeros((num_labels, num_classes)) 61 labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1 62 return labels_one_hot 63 def extract_labels(filename, one_hot=False): 64 """Extract the labels into a 1D uint8 numpy array [index].""" 65 print(‘Extracting‘, filename) 66 with gzip.open(filename) as bytestream: 67 magic = _read32(bytestream) 68 if magic != 2049: 69 raise ValueError( 70 ‘Invalid magic number %d in MNIST label file: %s‘ % 71 (magic, filename)) 72 num_items = _read32(bytestream) 73 buf = bytestream.read(num_items) 74 labels = numpy.frombuffer(buf, dtype=numpy.uint8) 75 if one_hot: 76 return dense_to_one_hot(labels) 77 return labels 78 class DataSet(object): 79 def __init__(self, images, labels, fake_data=False, one_hot=False, 80 dtype=tf.float32): 81 """Construct a DataSet. 82 one_hot arg is used only if fake_data is true. `dtype` can be either 83 `uint8` to leave the input as `[0, 255]`, or `float32` to rescale into 84 `[0, 1]`. 85 """ 86 dtype = tf.as_dtype(dtype).base_dtype 87 if dtype not in (tf.uint8, tf.float32): 88 raise TypeError(‘Invalid image dtype %r, expected uint8 or float32‘ % 89 dtype) 90 if fake_data: 91 self._num_examples = 10000 92 self.one_hot = one_hot 93 else: 94 assert images.shape[0] == labels.shape[0], ( 95 ‘images.shape: %s labels.shape: %s‘ % (images.shape, 96 labels.shape)) 97 self._num_examples = images.shape[0] 98 # Convert shape from [num examples, rows, columns, depth] 99 # to [num examples, rows*columns] (assuming depth == 1) 100 assert images.shape[3] == 1 101 images = images.reshape(images.shape[0], 102 images.shape[1] * images.shape[2]) 103 if dtype == tf.float32: 104 # Convert from [0, 255] -> [0.0, 1.0]. 105 images = images.astype(numpy.float32) 106 images = numpy.multiply(images, 1.0 / 255.0) 107 self._images = images 108 self._labels = labels 109 self._epochs_completed = 0 110 self._index_in_epoch = 0 111 @property 112 def images(self): 113 return self._images 114 @property 115 def labels(self): 116 return self._labels 117 @property 118 def num_examples(self): 119 return self._num_examples 120 @property 121 def epochs_completed(self): 122 return self._epochs_completed 123 def next_batch(self, batch_size, fake_data=False): 124 """Return the next `batch_size` examples from this data set.""" 125 if fake_data: 126 fake_image = [1] * 784 127 if self.one_hot: 128 fake_label = [1] + [0] * 9 129 else: 130 fake_label = 0 131 return [fake_image for _ in xrange(batch_size)], [ 132 fake_label for _ in xrange(batch_size)] 133 start = self._index_in_epoch 134 self._index_in_epoch += batch_size 135 if self._index_in_epoch > self._num_examples: 136 # Finished epoch 137 self._epochs_completed += 1 138 # Shuffle the data 139 perm = numpy.arange(self._num_examples) 140 numpy.random.shuffle(perm) 141 self._images = self._images[perm] 142 self._labels = self._labels[perm] 143 # Start next epoch 144 start = 0 145 self._index_in_epoch = batch_size 146 assert batch_size <= self._num_examples 147 end = self._index_in_epoch 148 return self._images[start:end], self._labels[start:end] 149 def read_data_sets(train_dir, fake_data=False, one_hot=False, dtype=tf.float32): 150 class DataSets(object): 151 pass 152 data_sets = DataSets() 153 if fake_data: 154 def fake(): 155 return DataSet([], [], fake_data=True, one_hot=one_hot, dtype=dtype) 156 data_sets.train = fake() 157 data_sets.validation = fake() 158 data_sets.test = fake() 159 return data_sets 160 TRAIN_IMAGES = ‘train-images-idx3-ubyte.gz‘ 161 TRAIN_LABELS = ‘train-labels-idx1-ubyte.gz‘ 162 TEST_IMAGES = ‘t10k-images-idx3-ubyte.gz‘ 163 TEST_LABELS = ‘t10k-labels-idx1-ubyte.gz‘ 164 VALIDATION_SIZE = 5000 165 local_file = maybe_download(TRAIN_IMAGES, train_dir) 166 train_images = extract_images(local_file) 167 local_file = maybe_download(TRAIN_LABELS, train_dir) 168 train_labels = extract_labels(local_file, one_hot=one_hot) 169 local_file = maybe_download(TEST_IMAGES, train_dir) 170 test_images = extract_images(local_file) 171 local_file = maybe_download(TEST_LABELS, train_dir) 172 test_labels = extract_labels(local_file, one_hot=one_hot) 173 validation_images = train_images[:VALIDATION_SIZE] 174 validation_labels = train_labels[:VALIDATION_SIZE] 175 train_images = train_images[VALIDATION_SIZE:] 176 train_labels = train_labels[VALIDATION_SIZE:] 177 data_sets.train = DataSet(train_images, train_labels, dtype=dtype) 178 data_sets.validation = DataSet(validation_images, validation_labels, 179 dtype=dtype) 180 data_sets.test = DataSet(test_images, test_labels, dtype=dtype) 181 return data_sets
# 这两行用来下载数据集 import input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) import tensorflow as tf # 设置变量 x = tf.placeholder("float", [None, 784]) # 占位符 w = tf.Variable(tf.zeros([784, 10])) # 权重值 b = tf.Variable(tf.zeros([10])) # 偏置值 # 创建模型,用tf.matmul(??X,W)表示x乘以W y = tf.nn.softmax(tf.matmul(x,w) + b) # 用于输入正确值,为了下面计算交叉熵 y_ = tf.placeholder("float", [None,10]) # 计算交叉熵 # 用 tf.log 计算 y 的每个元素的对数,然后把 y_ 的每一个元素和 tf.log(y_) 的对应元素相乘再用 tf.reduce_sum 计算张量的所有元素的总和 cross_entropy = -tf.reduce_sum(y_ * tf.log(y)) # 进行训练,以0.01的学习速率最小化交叉熵 train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy) # 初始化创建的变量 init = tf.initialize_all_variables() # 在一个Session里面启动模型,并初始化变量 sess = tf.Session() sess.run(init) # 开始训练模型,训练1000次 for i in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step,feed_dict={x:batch_xs, y_:batch_ys}) # 用 tf.equal 来检测我们的预测是否真实标签匹配 correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) # 上一行代码会返回一组布尔2值,为了正确预测,把布尔值转换成浮点数 accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) # 计算正确率 print(sess.run(accuracy, feed_dict={x:mnist.test.images, y_:mnist.test.labels}))
第一次运行主程序时会有点久,因为需要下载数据。最后,,会输出测试的准确率,大概91%左右。
0x03:图片识别过程
为了得到一张给定图片属于某个特定数字类的证据(evidence),我们对图片像素值进行加权求和。如果这个像素具有很强的证据说明这张图片不属于该类,那么相应的权值为负数,相反如果这个像素拥有有利的证据支持这张图片属于这个类,那么权值是正数。下面的图片显示了一个模型学习到的图片上每个像素对于特定数字类的权值。红色代表负数权值,蓝色代表正数权值。(我的理解是:将0-9抽象成10个数据类,红色的表示不属于这个数据类的“属性”,蓝色的表示属于这个数据类的“属性”,在一张图片中,如果符合蓝色“属性”的多些,则这张图片符合这个数据类的概率就高些(下面的softmax函数计算概率),个人理解,希望大佬们指正错误。。。)
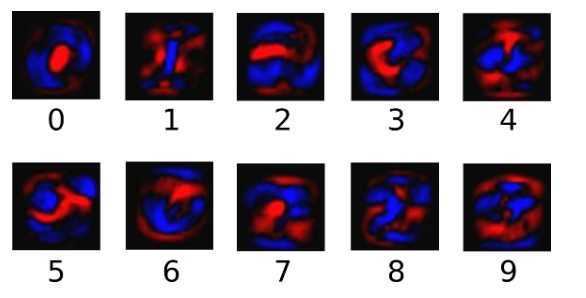
我们也需要加入一个额外的偏置量(bias),因为输入往往会带有一些无关的干扰量。因此对于给定的输入图片 x 它代表的是数字 i 的证据可以表示为(这句比较重要):
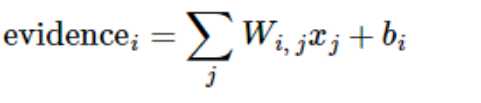
(这个公式结合下面第一个彩色图一起看比较容易理解些。)
其中  代表权重,
代表权重, 代表数字 i 类的偏置量,j 代表给定图片 x 的像素索引用于像素求和(还记得前面那个[60000, 784]的张量嘛)。然后用softmax函数可以把这些证据转换成概率 y(这句也是是关键):
代表数字 i 类的偏置量,j 代表给定图片 x 的像素索引用于像素求和(还记得前面那个[60000, 784]的张量嘛)。然后用softmax函数可以把这些证据转换成概率 y(这句也是是关键):
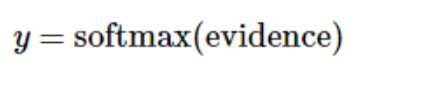
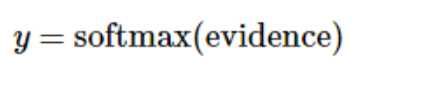
这里的softmax可以看成是一个激励(activation)函数或者链接(link)函数,把我们定义的线性函数的输出转换成我们想要的格式,也就是关于10个数字类的概率分布。因此,给定一张图片,它对于每一个数字的吻合度可以被softmax函数转换成为一个概率值。softmax函数可以定义为:
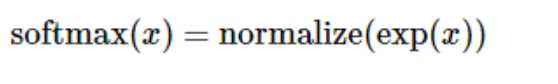
展开等式右边的子式,可以得到:
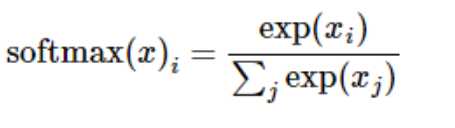
但是更多的时候把softmax模型函数定义为前一种形式:把输入值当成幂指数求值,再正则化这些结果值。这个幂运算表示,更大的证据对应更大的假设模型(hypothesis)里面的乘数权重值。反之,拥有更少的证据意味着在假设模型里面拥有更小的乘数系数。假设模型里的权值不可以是0值或者负值。Softmax然后会正则化这些权重值,使它们的总和等于1,以此构造一个有效的概率分布。(更多的关于Softmax函数的信息,可以参考Michael Nieslen的书里面的这个部分,其中有关于softmax的可交互式的可视化解释。)
对于softmax回归模型可以用下面的图解释,对于输入的xs加权求和,再分别加上一个偏置量,最后再输入到softmax函数中:
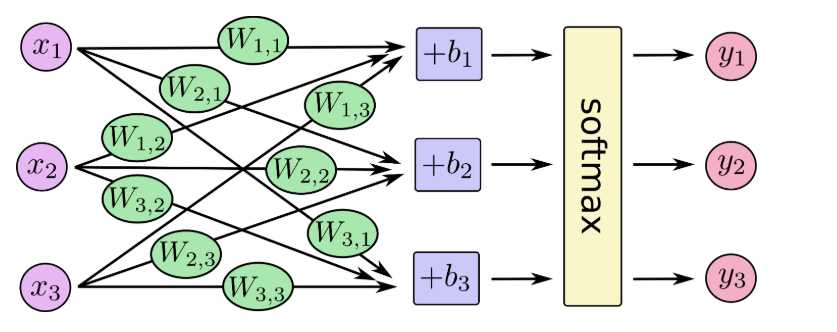
如果把它写成一个等式,我们可以得到:
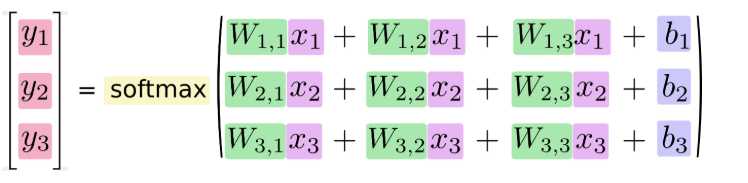
我们也可以用向量表示这个计算过程:用矩阵乘法和向量相加。这有助于提高计算效率。(也是一种更有效的思考方式)
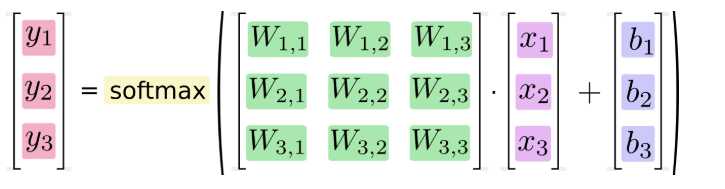
更进一步,可以写成更加紧凑的方式:
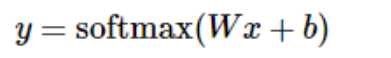
参考文章:http://www.tensorfly.cn/tfdoc/tutorials/mnist_beginners.html
********************不积跬步无以至千里********************
以上是关于tensorflow的MNIST教程的主要内容,如果未能解决你的问题,请参考以下文章
Tensorflow学习教程------普通神经网络对mnist数据集分类
Tensorflow学习教程------利用卷积神经网络对mnist数据集进行分类_训练模型