MQTT---HiveMQ源码详解(十七)Cluster-Consistent Hashing Ring & Node Lifecycle
Posted 西安-PP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MQTT---HiveMQ源码详解(十七)Cluster-Consistent Hashing Ring & Node Lifecycle相关的知识,希望对你有一定的参考价值。
源博客地址:http://blog.csdn.net/pipinet123
MQTT交流群:221405150
Consistent Hashing Ring
基本上只要做Cluster,都会使用到一致性Hash环,具体作用此处就不细讲,我们只了解HiveMQ怎么用它,怎么实现它,这样实现能够带来什么好处。
HiveMQ没有Master/Slave,它只由JGroup View(详情请查阅JGroup)第一个node作为Coordinator,这样就可以达到一个node也可以做集群(虽然这样的集群没有什么卵用)。
HiveMQ采用两个一致性Hash环,来解决脑裂问题,以及脑裂后merge的问题。
每个node 500个虚拟节点,来增加node变化带来的动荡问题。
Primary环:排除joining的node,即只添加RUNNING状态的node。
Minority环:包含joining的node,即添加JOINING、RUNNING、MERGING状态的node。
它的hash算法由net.openhft.hashing.LongHashFunction.xx_r39()提供
ConsistentHashingRing源码
相对来说比较简单,我就不一行一行写注释了,网上针对一致性hash环实现各种版本到处都是,详细讲解也到处都是。
@Singleton
public class ConsistentHashingRing {
private static final Logger LOGGER = LoggerFactory.getLogger(ConsistentHashingRing.class);
private final String name;
public static final int NODE_BUCKET_COUNT = 500;
private final LongHashFunction hashFunction;
private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock(true);
@VisibleForTesting
final NavigableMap<Long, String> buckets;
@VisibleForTesting
final ConcurrentHashMap<String, String> bucketNodes = new ConcurrentHashMap<>();
final Set<String> nodes = Sets.newConcurrentHashSet();
public ConsistentHashingRing(String name, LongHashFunction hashFunction) {
this.name = name;
this.buckets = new ConcurrentSkipListMap();
this.hashFunction = hashFunction;
}
public void add(@NotNull String node) {
Preconditions.checkNotNull(node, "Name must not be null");
LOGGER.trace("Add node {} to the {}.", node, this.name);
Lock lock = this.readWriteLock.writeLock();
lock.lock();
try {
for (int bucketIndex = 0; bucketIndex < NODE_BUCKET_COUNT; bucketIndex++) {
long bucketHash = this.hashFunction.hashChars(node + bucketIndex);
if (this.buckets.containsKey(bucketHash)) {
if (this.buckets.get(bucketHash).compareTo(node + 1) > 0) {
this.buckets.put(bucketHash, node + bucketIndex);
this.nodes.add(node);
this.bucketNodes.put(node + bucketIndex, node);
}
} else {
this.buckets.put(bucketHash, node + bucketIndex);
this.nodes.add(node);
this.bucketNodes.put(node + bucketIndex, node);
}
}
} finally {
lock.unlock();
}
}
public void remove(@NotNull String node) {
Preconditions.checkNotNull(node, "Name must not be null");
LOGGER.trace("Remove node {} from the {}.", node, this.name);
Lock lock = this.readWriteLock.writeLock();
lock.lock();
try {
for (int bucketIndex = 0; bucketIndex < NODE_BUCKET_COUNT; bucketIndex++) {
long bucketHash = this.hashFunction.hashChars(node + bucketIndex);
this.buckets.remove(bucketHash);
this.bucketNodes.remove(node + bucketIndex);
}
this.nodes.remove(node);
} finally {
lock.unlock();
}
}
public Set<String> getReplicaNodes(@NotNull String key, int replicateCount) {
Preconditions.checkNotNull(key, "key must not be null");
int nodeCount = this.nodes.size();
if (replicateCount > nodeCount - 1) {
LOGGER.trace("There are not enough buckets in the consistent hash ring for {} replicas.", replicateCount);
replicateCount = nodeCount - 1;
}
String bucket = getBucket(key);
long bucketHash = this.hashFunction.hashChars(bucket);
Lock lock = this.readWriteLock.readLock();
lock.lock();
Set<String> buckets = new HashSet<>();
try {
for (Map.Entry<Long, String> entry = this.buckets.higherEntry(bucketHash);
buckets.size() < replicateCount;
entry = this.buckets.higherEntry(entry.getKey())) {
if (entry == null) {
entry = this.buckets.firstEntry();
}
if (!this.bucketNodes.get(entry.getValue()).equals(this.bucketNodes.get(bucket))) {
buckets.add(this.bucketNodes.get(entry.getValue()));
}
}
return buckets;
} finally {
lock.unlock();
}
}
public Set<String> getNodes() {
ImmutableSet.Builder<String> builder = ImmutableSet.builder();
Lock lock = this.readWriteLock.readLock();
lock.lock();
try {
return builder.addAll(this.nodes).build();
} finally {
lock.unlock();
}
}
public String getBucket(@NotNull String key) {
Preconditions.checkNotNull(key, "key must not be null");
if (this.buckets.isEmpty()) {
throw new IllegalStateException("Consistent hash ring is empty.");
}
long keyHash = this.hashFunction.hashChars(key);
Lock lock = this.readWriteLock.readLock();
lock.lock();
try {
Map.Entry<Long, String> entry = this.buckets.ceilingEntry(keyHash);
if (entry != null) {
return entry.getValue();
}
return this.buckets.ceilingEntry(Long.MIN_VALUE).getValue();
} finally {
lock.unlock();
}
}
public String getNode(@NotNull String key) {
Preconditions.checkNotNull(key, "key must not be null");
if (this.buckets.isEmpty()) {
throw new IllegalStateException("Consistent hash ring is empty.");
}
long keyHash = this.hashFunction.hashChars(key);
Lock lock = this.readWriteLock.readLock();
lock.lock();
try {
Map.Entry<Long, String> entry = this.buckets.ceilingEntry(keyHash);
if (entry != null) {
return this.bucketNodes.get(entry.getValue());
}
return this.bucketNodes.get(this.buckets.ceilingEntry(Long.MIN_VALUE).getValue());
} finally {
lock.unlock();
}
}
}Node Lifecycle
其实了解了上面HiveMQ Cluster的基础之后,再来看node的生命周期,就是一件简单的事情了。
废话少说,我们直接上状态变化图。
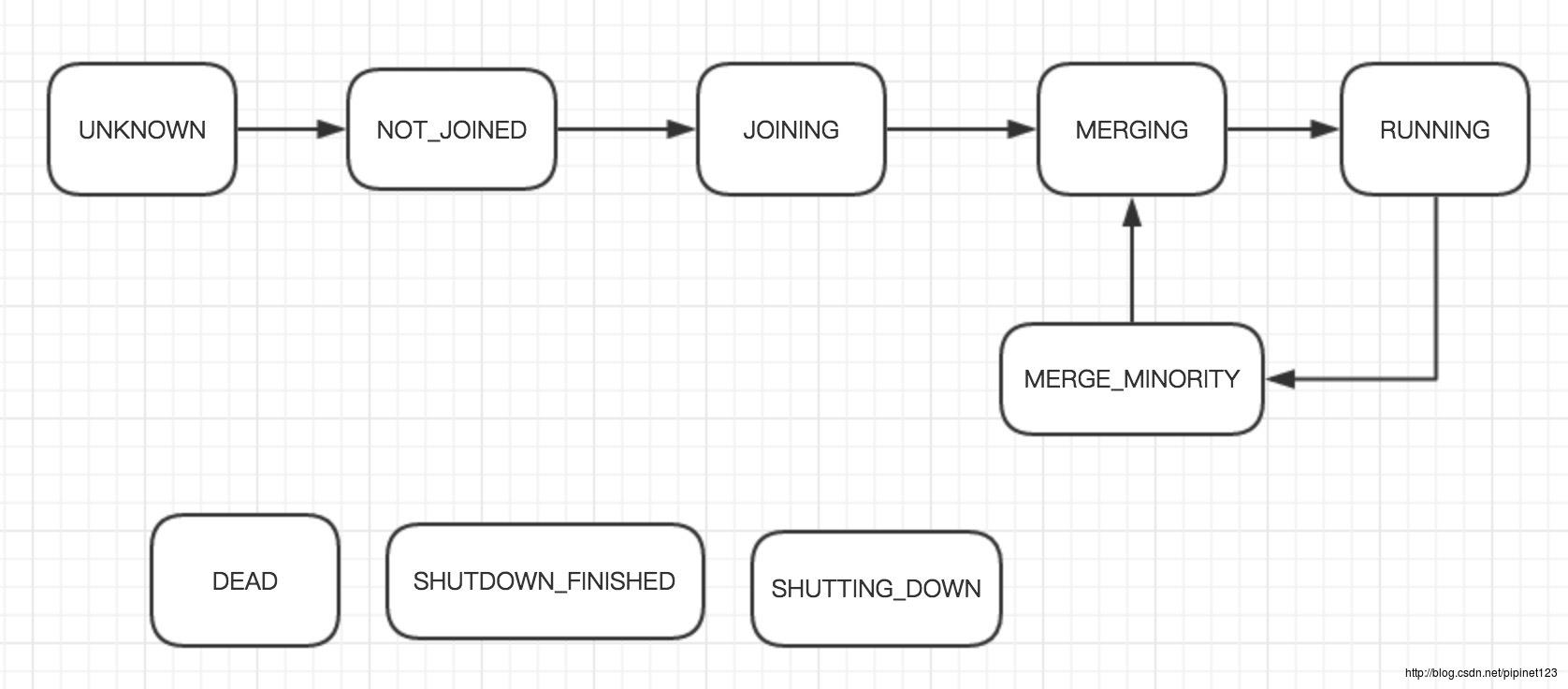
各种状态简介
UNKNOWN
当JGroup通知新的node连接,但在本地不存在,则该node状态标记为UNKNOWN
NOT_JOINED
当node连接上JGroup后,若它不是唯一的node,则它将自己主动标记为NOT_JOINED
JOINING
当node将自己的状态更新至Cluster完成后,它将自己主动标记为JOINING
MERGE_MINORITY
当脑裂后与Coordinator在同组的其他node都将被标记为MERGE_MINORITY;或者加入Primary Group失败后它将自己主动标记为MERGE_MINORITY
MERGING
MERGE_MINORITY会一直去尝试主动将自己标记为MERGING
RUNNING
当MERGING成功后,node将会进行Replicate操作,当Replicate操作完成,就主动将自己标记为RUNNING
SHUTTING_DOWN/SHUTDOWN_FINISHED/DEAD
这三种状态在源码中未被使用,但HiveMQ还这样定义,或许是保留吧,反正博主未搞懂,不过不重要,不懂就算了,^_^。
以上是关于MQTT---HiveMQ源码详解(十七)Cluster-Consistent Hashing Ring & Node Lifecycle的主要内容,如果未能解决你的问题,请参考以下文章