TCP连接建立及相关socket深度探析
Posted lintonw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TCP连接建立及相关socket深度探析相关的知识,希望对你有一定的参考价值。
关于TCP协议
TCP/IP协议分层模型
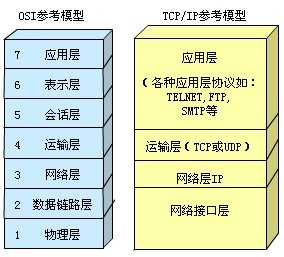
可以看到,TCP协议位于运输层,TCP将用户数据打包构成报文段,它发送数据时启动一个定时器,另一端收到数据进行确认,对失序的数据重新排序,丢弃重复的数据。TCP提供一种面向连接的可靠的字节流服务,面向连接意味着两个使用TCP的应用(B/S)在彼此交换数据之前,必须先建立一个TCP连接,类似于打电话过程,先拨号振铃,等待对方说喂,然后应答。在一个TCP连接中,只有两方彼此通信。
TCP可靠性来自于:
(1)应用数据被分成TCP最合适的发送数据块
(2)当TCP发送一个段之后,启动一个定时器,等待目的点确认收到报文,如果不能及时收到一个确认,将重发这个报文。
(3)当TCP收到连接端发来的数据,就会推迟几分之一秒发送一个确认。
(4)TCP将保持它首部和数据的检验和,这是一个端对端的检验和,目的在于检测数据在传输过程中是否发生变化。(有错误,就不确认,发送端就会重发)
(5)TCP是以IP报文来传送,IP数据是无序的,TCP收到所有数据后进行排序,再交给应用层
(6)IP数据报会重复,所以TCP会去重
(7)TCP能提供流量控制,TCP连接的每一个地方都有固定的缓冲空间。TCP的接收端只允许另一端发送缓存区能接纳的数据。
(8)TCP对字节流不做任何解释,对字节流的解释由TCP连接的双方应用层解释。
TCP建立连接的过程(三次握手)
TCP是一个面向连接的协议,无论哪一方向另一方发送数据之前,都必须先在双方之间建立一条连接,所谓三次握手(Three-Way Handshake)即建立TCP连接,就是指建立一个TCP连接时,需要客户端和服务端总共发送3个包以确认连接的建立。在socket编程中,这一过程由客户端执行connect来触发,整个流程如下图所示:
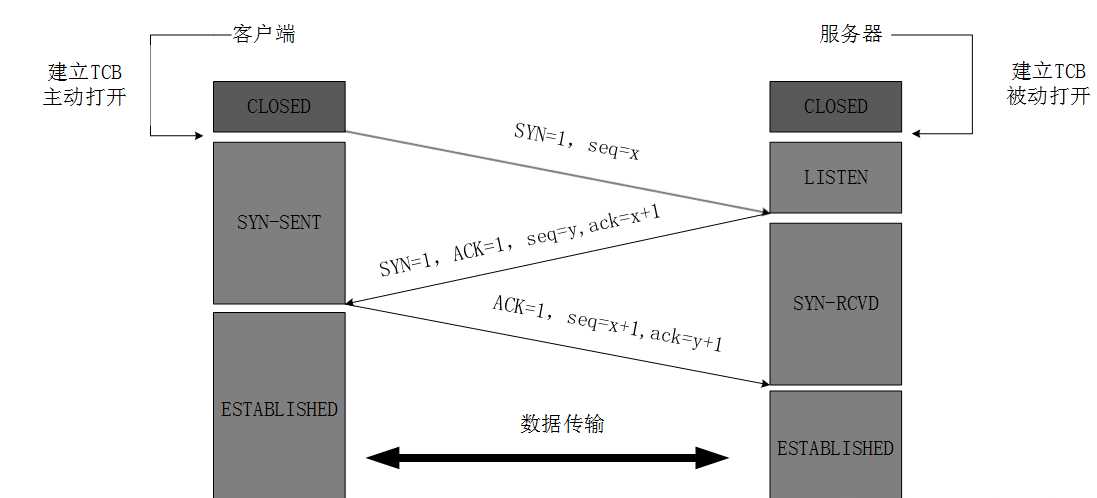
(1)第一次握手:Client将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给Server,Client进入SYN_SENT状态,等待Server确认。
(2)第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态。
(3)第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
简单来说,就是:
1、建立连接时,客户端发送SYN包(SYN=i)到服务器,并进入到SYN-SEND状态,等待服务器确认;
2、服务器收到SYN包,必须确认客户的SYN(ack=i+1),同时自己也发送一个SYN包(SYN=k),即SYN+ACK包,此时服务器进入SYN-RECV状态;
3、客户端收到服务器的SYN+ACK包,向服务器发送确认报ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手,客户端与服务器开始传送数据。
关于SYN泛洪攻击
在三次握手过程中,Server发送SYN-ACK之后,收到Client的ACK之前的TCP连接称为半连接(half-open connect),此时Server处于SYN_RCVD状态,当收到ACK后,Server转入ESTABLISHED状态。SYN攻击就是Client在短时间内伪造大量不存在的IP地址,并向Server不断地发送SYN包,Server回复确认包,并等待Client的确认,由于源地址是不存在的,因此,Server需要不断重发直至超时,这些伪造的SYN包将产时间占用未连接队列,导致正常的SYN请求因为队列满而被丢弃,从而引起网络堵塞甚至系统瘫痪。SYN攻击时一种典型的DDOS攻击,检测SYN攻击的方式非常简单,即当Server上有大量半连接状态且源IP地址是随机的,则可以断定遭到SYN攻击了,使用如下命令可以让之现行:
netstat -nap | grep SYN_RECV
谈了TCP协议连接建立的三次握手后,接下来再复习下linux socket协议栈的相关内容:
关于linux socket
linux网络路径
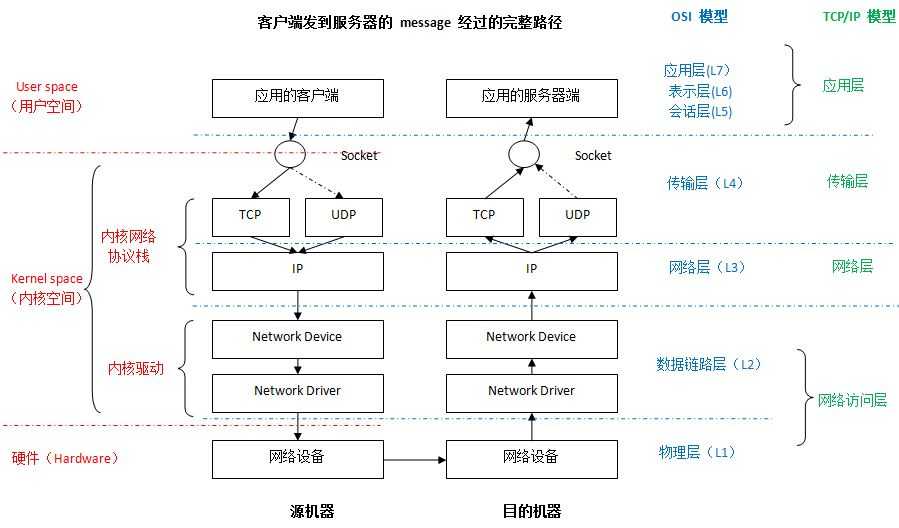
从上图中可以清晰地看到socket在网络分层中的位置,由于socket接口应该划在应用层,而我们日常的网络编程也都基本在应用层上,所以下面将从发送端和接收端两个角度分别对应用层进行分析:
发送端
应用层
(1) Socket
应用层的各种网络应用程序基本上都是通过 Linux Socket 编程接口来和内核空间的网络协议栈通信的。Linux Socket 是从 BSD Socket 发展而来的,它是 Linux 操作系统的重要组成部分之一,它是网络应用程序的基础。从层次上来说,它位于应用层,是操作系统为应用程序员提供的 API,通过它,应用程序可以访问传输层协议。
- socket 位于传输层协议之上,屏蔽了不同网络协议之间的差异
- socket 是网络编程的入口,它提供了大量的系统调用,构成了网络程序的主体
- 在Linux系统中,socket 属于文件系统的一部分,网络通信可以被看作是对文件的读取,使得我们对网络的控制和对文件的控制一样方便。
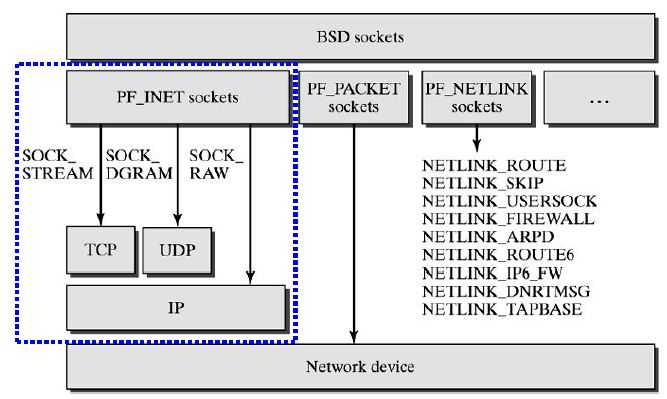
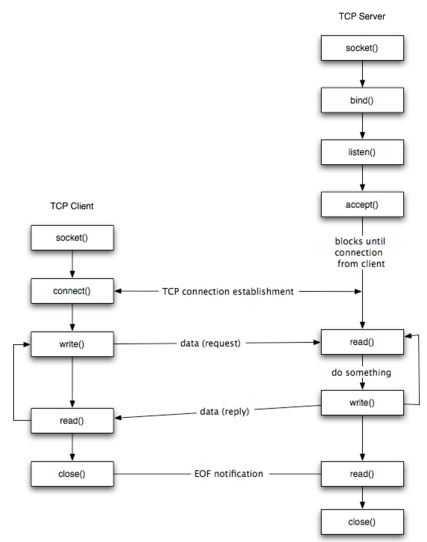
TCP Socket 处理过程
(2) 应用层处理流程
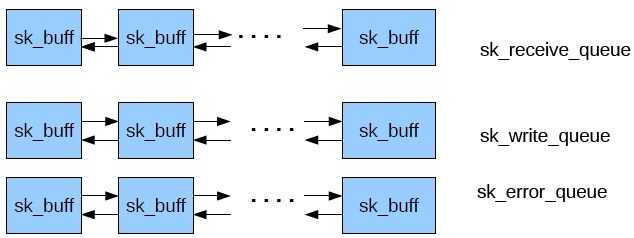
- 网络应用调用Socket API socket (int family, int type, int protocol) 创建一个 socket,该调用最终会调用 Linux system call socket() ,并最终调用 Linux Kernel 的 sock_create() 方法。该方法返回被创建好了的那个 socket 的 file descriptor。对于每一个 userspace 网络应用创建的 socket,在内核中都有一个对应的 struct socket和 struct sock。其中,struct sock 有三个队列(queue),分别是 rx , tx 和 err,在 sock 结构被初始化的时候,这些缓冲队列也被初始化完成;在收据收发过程中,每个 queue 中保存要发送或者接受的每个 packet 对应的 Linux 网络栈 sk_buffer 数据结构的实例 skb。
- 对于 TCP socket 来说,应用调用 connect()API ,使得客户端和服务器端通过该 socket 建立一个虚拟连接。在此过程中,TCP 协议栈通过三次握手会建立 TCP 连接。默认地,该 API 会等到 TCP 握手完成连接建立后才返回。在建立连接的过程中的一个重要步骤是,确定双方使用的 Maxium Segemet Size (MSS)。
- 应用调用 Linux Socket 的 send 或者 write API 来发出一个 message 给接收端
- sock_sendmsg 被调用,它使用 socket descriptor 获取 sock struct,创建 message header 和 socket control message
- _sock_sendmsg 被调用,根据 socket 的协议类型,调用相应协议的发送函数。
对于 TCP ,调用 tcp_sendmsg 函数。
接收端
应用层
- 每当用户应用调用 read 或者 recvfrom 时,该调用会被映射为/net/socket.c 中的 sys_recv 系统调用,并被转化为 sys_recvfrom 调用,然后调用 sock_recgmsg 函数。
- 对于 INET 类型的 socket,/net/ipv4/af inet.c 中的 inet_recvmsg 方法会被调用,它会调用相关协议的数据接收方法。
- 对 TCP 来说,调用 tcp_recvmsg。该函数从 socket buffer 中拷贝数据到 user buffer。
TCP相关源码深度分析及GDB跟踪调试
虚拟机:ubuntu 16.04
内核版本:linux 5.0.1
编译方式:x86-64
模拟器:qemu
基于系统:部署好TCP通信程序的Menu OS系统
相关目录路径:/net/ipv4、/net/socket.c
TCP相关系统接口定义
再次跑起来之前已经部署好TCP通信程序的Menu OS系统,追踪与TCP连接相关的socket、connect、listen、accept函数的系统调用:
首先以调试模式运行Menu OS系统:
cd kernel qemu-system-x86_64 -kernel linux-5.0.1/arch/x86/boot/bzImage -initrd rootfs.img -append nokaslr -s
新打开一个命令行运行GDB进行Menu OS的调试:
cd kernel file linux-5.0.1/vmlinux target remote:1234
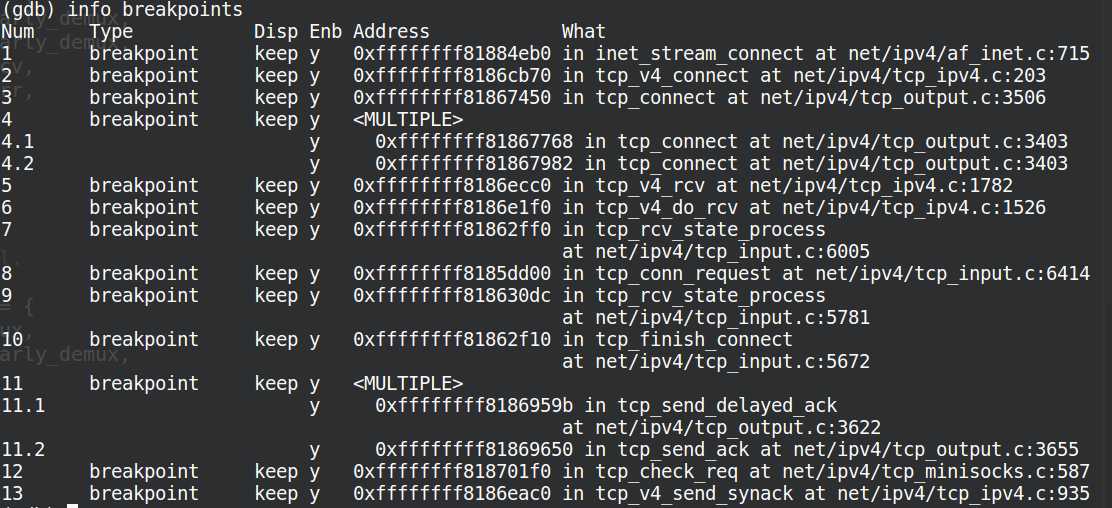
设置相应的断点:
b __sys_socket b __sys_connect b __sys_listen b __sys_accept4 info breakpoints

发现相应的socket系统调用函数都在 net/socket.c目录下,打开该目录,分析源代码,其中socket接口函数都定义在SYSCALL_DEFINE接口里,找到主要的相关SYSCALL_DEFINE定义如下:

1 SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
2 {
3 return __sys_socket(family, type, protocol);
4 }
5
6 SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen)
7 {
8 return __sys_bind(fd, umyaddr, addrlen);
9 }
10
11 SYSCALL_DEFINE2(listen, int, fd, int, backlog)
12 {
13 return __sys_listen(fd, backlog);
14 }
15
16
17 SYSCALL_DEFINE3(accept, int, fd, struct sockaddr __user *, upeer_sockaddr,
18 int __user *, upeer_addrlen)
19 {
20 return __sys_accept4(fd, upeer_sockaddr, upeer_addrlen, 0);
21 }
22
23 SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr,
24 int, addrlen)
25 {
26 return __sys_connect(fd, uservaddr, addrlen);
27 }
28
29 SYSCALL_DEFINE3(getsockname, int, fd, struct sockaddr __user *, usockaddr,
30 int __user *, usockaddr_len)
31 {
32 return __sys_getsockname(fd, usockaddr, usockaddr_len);
33 }
34
35 SYSCALL_DEFINE3(getpeername, int, fd, struct sockaddr __user *, usockaddr,
36 int __user *, usockaddr_len)
37 {
38 return __sys_getpeername(fd, usockaddr, usockaddr_len);
39 }
40
41
42 SYSCALL_DEFINE4(send, int, fd, void __user *, buff, size_t, len,
43 unsigned int, flags)
44 {
45 return __sys_sendto(fd, buff, len, flags, NULL, 0);
46 }
47
48 SYSCALL_DEFINE4(recv, int, fd, void __user *, ubuf, size_t, size,
49 unsigned int, flags)
50 {
51 return __sys_recvfrom(fd, ubuf, size, flags, NULL, NULL);
52 }
逐步分析TCP三次握手的系统级实现
TCP连接前的初始化过程
1)调用__sys_socket, __sys_socket源码如下:
int __sys_socket(int family, int type, int protocol)
{
int retval;
struct socket *sock;
int flags;
/* Check the SOCK_* constants for consistency. */
BUILD_BUG_ON(SOCK_CLOEXEC != O_CLOEXEC);
BUILD_BUG_ON((SOCK_MAX | SOCK_TYPE_MASK) != SOCK_TYPE_MASK);
BUILD_BUG_ON(SOCK_CLOEXEC & SOCK_TYPE_MASK);
BUILD_BUG_ON(SOCK_NONBLOCK & SOCK_TYPE_MASK);
flags = type & ~SOCK_TYPE_MASK;
if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK))
return -EINVAL;
type &= SOCK_TYPE_MASK;
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
retval = sock_create(family, type, protocol, &sock);
if (retval < 0)
return retval;
return sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
}
可以看到,__sys_socket调用了sock_create和sock_map_fd函数;
2)调用sock_create():创建socket结构,针对每种不同的family的socket结构的初始化,就需要调用不同的create函数来完成。对应于inet类型的地址来说,在网络协议初始化时调用sock_register()函数中完成注册的定义如下:
struct net_proto_family inet_family_ops={
PF_INET;
inet_create
};
所以inet协议最后会调用inet_create函数。
3)调用inet_create: 初始化sock的状态设置为SS_UNCONNECTED,申请一个新的sock结构,并且初始化socket的成员ops初始化为inet_stream_ops,而sock的成员prot初始化为tcp_prot。然后调用sock_init_data,将该socket结构的变量sock和sock类型的变量关联起来。
inet_create函数源码如下:
1 static int inet_create(struct net *net, struct socket *sock, int protocol,int kern)
2 {
3 ...
4 /* Look for the requested type/protocol pair. */
5 lookup_protocol:
6 err = -ESOCKTNOSUPPORT;
7 rcu_read_lock();
8
9 // TCP套接字、UDP套接字、原始套接字的inet_protosw实 例都在inetsw_array数组中定义,
10 //这些实例会调inet_register_protosw()注册到inetsw中
11 //根据protocol查找要创建的套接字对应的四层传输协议。
12 list_for_each_entry_rcu(answer, &inetsw[sock->type], list) {
13 ...
14 }
15
16 //如果没有找到,则调用request_module()来尝试加载协议所属的模块,正常情况下不会发生。
17 if (unlikely(err)) {
18 if (try_loading_module < 2) {
19 rcu_read_unlock();
20 ...
21 }
4)调用sock_map_fd()获取一个未被使用的文件描述符,并且申请并初始化对应的file{}结构。
TCP连接的三次握手过程深度解析
接下来通过阅读TCP源代码的方式,一步步地追踪解析系统级TCP三次握手的详细过程。首先从__sys_connect源码开始,逐步向深处探究:
1 int __sys_connect(int fd, struct sockaddr __user *uservaddr, int addrlen)
2 {
3 struct socket *sock;
4 struct sockaddr_storage address;
5 int err, fput_needed;
6 //得到socket对象
7 sock = sockfd_lookup_light(fd, &err, &fput_needed);
8 if (!sock)
9 goto out;
10 //将地址对象从用户空间拷贝到内核空间
11 err = move_addr_to_kernel(uservaddr, addrlen, &address);
12 if (err < 0)
13 goto out_put;
14 //内核相关
15 err =
16 security_socket_connect(sock, (struct sockaddr *)&address, addrlen);
17 if (err)
18 goto out_put;
19 //对于流式套接字,sock->ops为 inet_stream_ops -->inet_stream_connect
20
21 //对于数据报套接字,sock->ops为 inet_dgram_ops --> inet_dgram_connect
22 err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen,
23 sock->file->f_flags);
24 out_put:
25 fput_light(sock->file, fput_needed);
26 out:
27 return err;
28 }
在该函数中做了三件事:
1. 根据文件描述符找到指定的socket对象;
2. 将地址信息从用户空间拷贝到内核空间;
3. 调用指定类型套接字的connect函数。
对应流式套接字的connect函数是inet_stream_connect,接着我们分析该函数:
在GDB中设置断点找到源文件:

1 int inet_stream_connect(struct socket *sock, struct sockaddr *uaddr,
2 int addr_len, int flags)
3 {
4 int err;
5
6 lock_sock(sock->sk);
7 err = __inet_stream_connect(sock, uaddr, addr_len, flags);
8 release_sock(sock->sk);
9 return err;
10 }
11
12 /*
13 * Connect to a remote host. There is regrettably still a little
14 * TCP ‘magic‘ in here.
15 */
16
17 //1. 检查socket地址长度和使用的协议族。
18 //2. 检查socket的状态,必须是SS_UNCONNECTED或SS_CONNECTING。
19 //3. 调用tcp_v4_connect()来发送SYN包。
20 //4. 等待后续握手的完成:
21 int __inet_stream_connect(struct socket *sock, struct sockaddr *uaddr,
22 int addr_len, int flags)
23 ...
24 后面太多便不再展示,可直接看源码
该函数主要做了几件事:
1. 检查socket地址长度和使用的协议族;
2. 检查socket的状态,必须是SS_UNCONNECTED或SS_CONNECTING;
3. 调用实现协议的connect函数,对于流式套接字,实现协议是tcp,调用的是tcp_v4_connect();
4.对于阻塞调用,等待后续握手的完成;对于非阻塞调用,则直接返回 -EINPROGRESS。
我们先关注tcp_v4_connect,同样先在gdb中设置断点,找到源文件所在位置:

1 /* This will initiate an outgoing connection. */
2
3 //对于TCP 协议来说,其连接实际上就是发送一个 SYN 报文,在服务器的应答到来时,回答它一个 ack 报文,也就是完成三次握手中的第一和第三次
4 int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len)
5 {
6 struct sockaddr_in *usin = (struct sockaddr_in *)uaddr;
7 struct inet_sock *inet = inet_sk(sk);
8 struct tcp_sock *tp = tcp_sk(sk);
9 __be16 orig_sport, orig_dport;
10 __be32 daddr, nexthop;
11 struct flowi4 *fl4;
12 struct rtable *rt;
13 int err;
14 struct ip_options_rcu *inet_opt;
15
16 if (addr_len < sizeof(struct sockaddr_in))
17 return -EINVAL;
18
19 if (usin->sin_family != AF_INET)
20 return -EAFNOSUPPORT;
21
22 nexthop = daddr = usin->sin_addr.s_addr;
23 inet_opt = rcu_dereference_protected(inet->inet_opt,
24 lockdep_sock_is_held(sk));
25
26 //将下一跳地址和目的地址的临时变量都暂时设为用户提交的地址。
27 if (inet_opt && inet_opt->opt.srr) {
28 if (!daddr)
29 return -EINVAL;
30 nexthop = inet_opt->opt.faddr;
31 }
32
33 //源端口
34 orig_sport = inet->inet_sport;
35
36 //目的端口
37 orig_dport = usin->sin_port;
38
39 fl4 = &inet->cork.fl.u.ip4;
40
41 //如果使用了来源地址路由,选择一个合适的下一跳地址。
42 rt = ip_route_connect(fl4, nexthop, inet->inet_saddr,
43 RT_CONN_FLAGS(sk), sk->sk_bound_dev_if,
44 IPPROTO_TCP,
45 orig_sport, orig_dport, sk);
46 if (IS_ERR(rt)) {
47 err = PTR_ERR(rt);
48 if (err == -ENETUNREACH)
49 IP_INC_STATS(sock_net(sk), IPSTATS_MIB_OUTNOROUTES);
50 return err;
51 }
52 ...
53 后面较长,不再展示。
在该函数主要完成:
1. 路由查找,得到下一跳地址,并更新socket对象的下一跳地址;
2. 将socket对象的状态设置为TCP_SYN_SENT;
3. 如果没设置序号初值,则选定一个随机初值;
4. 调用函数tcp_connect完成报文构建和发送。
我接着看下tcp_connect:

1 /* Build a SYN and send it off. */
2 //由tcp_v4_connect()->tcp_connect()->tcp_transmit_skb()发送,并置为TCP_SYN_SENT.
3 int tcp_connect(struct sock *sk)
4 {
5 struct tcp_sock *tp = tcp_sk(sk);
6 struct sk_buff *buff;
7 int err;
8
9 //初始化传输控制块中与连接相关的成员
10 tcp_connect_init(sk);
11
12 if (unlikely(tp->repair)) {
13 tcp_finish_connect(sk, NULL);
14 return 0;
15 }
16 //分配skbuff --> 为SYN段分配报文并进行初始化
17 buff = sk_stream_alloc_skb(sk, 0, sk->sk_allocation, true);
18 if (unlikely(!buff))
19 return -ENOBUFS;
20
21 //构建syn报文
22
23 //在函数tcp_v4_connect中write_seq已经被初始化随机值
24 tcp_init_nondata_skb(buff, tp->write_seq++, TCPHDR_SYN);
25
26 tp->retrans_stamp = tcp_time_stamp;
27
28 //将报文添加到发送队列上
29 tcp_connect_queue_skb(sk, buff);
30
31 //显式拥塞通告 --->
32 //路由器在出现拥塞时通知TCP。当TCP段传递时,路由器使用IP首部中的2位来记录拥塞,当TCP段到达后,
33 //接收方知道报文段是否在某个位置经历过拥塞。然而,需要了解拥塞发生情况的是发送方,而非接收方。因
34 //此,接收方使用下一个ACK通知发送方有拥塞发生,然后,发送方做出响应,缩小自己的拥塞窗口。
35 tcp_ecn_send_syn(sk, buff);
36
37 /* Send off SYN; include data in Fast Open. */
38 err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) :
39
40 //构造tcp头和ip头并发送
41 tcp_transmit_skb(sk, buff, 1, sk->sk_allocation);
42 if (err == -ECONNREFUSED)
43 return err;
44
45 /* We change tp->snd_nxt after the tcp_transmit_skb() call
46 * in order to make this packet get counted in tcpOutSegs.
47 */
48 tp->snd_nxt = tp->write_seq;
49 tp->pushed_seq = tp->write_seq;
50 TCP_INC_STATS(sock_net(sk), TCP_MIB_ACTIVEOPENS);
51
52 /* Timer for repeating the SYN until an answer. */
53
54 //启动重传定时器
55 inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
56 inet_csk(sk)->icsk_rto, TCP_RTO_MAX);
57 return 0;
58 }
该函数完成:
1. 初始化套接字跟连接相关的字段;
2. 申请sk_buff空间;
3 . 将sk_buff初始化为syn报文,实质是操作tcp_skb_cb,在初始化TCP头的时候会用到;
4 . 调用tcp_connect_queue_skb()函数将报文sk_buff添加到发送队列sk->sk_write_queue;
5 . 调用tcp_transmit_skb()函数构造tcp头,然后交给网络层;
6. 初始化重传定时器。
接着我们进入tcp_connect_queue_skb:
1 /* This routine actually transmits TCP packets queued in by
2 * tcp_do_sendmsg(). This is used by both the initial
3 * transmission and possible later retransmissions.
4 * All SKB‘s seen here are completely headerless. It is our
5 * job to build the TCP header, and pass the packet down to
6 * IP so it can do the same plus pass the packet off to the
7 * device.
8 *
9 * We are working here with either a clone of the original
10 * SKB, or a fresh unique copy made by the retransmit engine.
11 */
12 static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it,
13 gfp_t gfp_mask)
14 {
15 const struct inet_connection_sock *icsk = inet_csk(sk);
16 struct inet_sock *inet;
17 struct tcp_sock *tp;
18 struct tcp_skb_cb *tcb;
19 struct tcp_out_options opts;
20 unsigned int tcp_options_size, tcp_header_size;
21 struct tcp_md5sig_key *md5;
22 struct tcphdr *th;
23 int err;
24
25 BUG_ON(!skb || !tcp_skb_pcount(skb));
26 tp = tcp_sk(sk);
27
28 //根据传递进来的clone_it参数来确定是否需要克隆待发送的报文
29 if (clone_it) {
30 skb_mstamp_get(&skb->skb_mstamp);
31 TCP_SKB_CB(skb)->tx.in_flight = TCP_SKB_CB(skb)->end_seq
32 - tp->snd_una;
33 tcp_rate_skb_sent(sk, skb);
34
35 //如果一个SKB会被不同的用户独立操作,而这些用户可能只是修改SKB描述符中的某些字段值,如h、nh,则内核没有必要为每个用户复制一份完整
36 //的SKB描述及其相应的数据缓存区,而会为了提高性能,只作克隆操作。克隆过程只复制SKB描述符,同时增加数据缓存区的引用计数,以免共享数
37 //据被提前释放。完成这些功能的是skb_clone()。一个使用包克隆的场景是,一个接收包程序要把该包传递给多个接收者,例如包处理函数或者一
38 //个或多个网络模块。原始的及克隆的SKB描述符的cloned值都会被设置为1,克隆SKB描述符的users值置为1,这样在第一次释放时就会释放掉。同时
39 //将数据缓存区引用计数dataref递增1,因为又多了一个克隆SKB描述符指向它
40
41 if (unlikely(skb_cloned(skb)))
42 //如果skb已经被clone,则只能复制该skb的数据到新分配的skb中
43 skb = pskb_copy(skb, gfp_mask);
44 else
45 skb = skb_clone(skb, gfp_mask);
46 if (unlikely(!skb))
47 return -ENOBUFS;
48 }
49 ...
50 后面较长,不再展示。
可以看到主要是移动sk_buff的data指针,然后填充TCP头,接着的事就是交给网络层,将报文发出。这样三次握手中的第一次握手在客户端的层面完成,报文到达服务端,由服务端处理完毕后,第一次握手完成,客户端socket状态变为TCP_SYN_SENT。下面我们看下服务端的处理。
数据到达网卡的时候,对于TCP协议,将大致要经过这个一个调用链:
网卡驱动 ---> netif_receive_skb() ---> ip_rcv() ---> ip_local_deliver_finish() ---> tcp_v4_rcv()
我们直接看tcp_v4_rcv():

1 /*
2 * From tcp_input.c
3 */
4
5 //网卡驱动-->netif_receive_skb()--->ip_rcv()--->ip_local_deliver_finish()---> tcp_v4_rcv()
6 int tcp_v4_rcv(struct sk_buff *skb)
7 {
8 struct net *net = dev_net(skb->dev);
9 const struct iphdr *iph;
10 const struct tcphdr *th;
11 bool refcounted;
12 struct sock *sk;
13 int ret;
14
15 //如果不是发往本地的数据包,则直接丢弃
16 if (skb->pkt_type != PACKET_HOST)
17 goto discard_it;
18
19 /* Count it even if it‘s bad */
20 __TCP_INC_STATS(net, TCP_MIB_INSEGS);
21
22
23 ////包长是否大于TCP头的长度
24 if (!pskb_may_pull(skb, sizeof(struct tcphdr)))
25 goto discard_it;
26
27 //tcp头 --> 不是很懂为何老是获取tcp头
28 th = (const struct tcphdr *)skb->data;
29 ...
30 后面较长,不再展示。
该函数主要工作就是根据tcp头部信息查到处理报文的socket对象,然后检查socket状态做不同处理,我们这里是监听状态TCP_LISTEN,直接调用函数tcp_v4_do_rcv():

1 /* The socket must have it‘s spinlock held when we get
2 * here, unless it is a TCP_LISTEN socket.
3 *
4 * We have a potential double-lock case here, so even when
5 * doing backlog processing we use the BH locking scheme.
6 * This is because we cannot sleep with the original spinlock
7 * held.
8 */
9
10 //网卡驱动-->netif_receive_skb()--->ip_rcv()--->ip_local_deliver_finish()---> tcp_v4_rcv()
11
12
13 //tcp_v4_do_rcv() -> tcp_rcv_state_process() -> tcp_v4_conn_request() -> tcp_v4_send_synack()
14 int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
15 {
16 struct sock *rsk;
17
18 //如果是连接已建立状态
19 if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */
20 struct dst_entry *dst = sk->sk_rx_dst;
21
22 sock_rps_save_rxhash(sk, skb);
23 sk_mark_napi_id(sk, skb);
24 if (dst) {
25 if (inet_sk(sk)->rx_dst_ifindex != skb->skb_iif ||
26 !dst->ops->check(dst, 0)) {
27 dst_release(dst);
28 sk->sk_rx_dst = NULL;
29 }
30 }
31 tcp_rcv_established(sk, skb, tcp_hdr(skb), skb->len);
32 return 0;
33 }
34 ...
35 后面较长,不再展示。
在这里并没有很多代码,做的东西也不是很多,对于监听状态的套接字,主要是一个SYN FLOOD防范相关的东西,不是我们研究的重点;接着就是调用tcp_rcv_state_process():

1 /*
2 * This function implements the receiving procedure of RFC 793 for
3 * all states except ESTABLISHED and TIME_WAIT.
4 * It‘s called from both tcp_v4_rcv and tcp_v6_rcv and should be
5 * address independent.
6 */
7
8
9 //除了ESTABLISHED和TIME_WAIT状态外,其他状态下的TCP段处理都由本函数实现
10
11 // tcp_v4_do_rcv() -> tcp_rcv_state_process() -> tcp_v4_conn_request() -> tcp_v4_send_synack().
12 int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
13 {
14 struct tcp_sock *tp = tcp_sk(sk);
15 struct inet_connection_sock *icsk = inet_csk(sk);
16 const struct tcphdr *th = tcp_hdr(skb);
17 struct request_sock *req;
18 int queued = 0;
19 bool acceptable;
20
21 switch (sk->sk_state) {
22
23 //SYN_RECV状态的处理
24 case TCP_CLOSE:
25 goto discard;
26
27 //服务端第一次握手处理
28 case TCP_LISTEN:
29 if (th->ack)
30 return 1;
31
32 if (th->rst)
33 goto discard;
34
35 if (th->syn) {
36 if (th->fin)
37 goto discard;
38 // tcp_v4_do_rcv() -> tcp_rcv_state_process() -> tcp_v4_conn_request() -> tcp_v4_send_synack().
39 if (icsk->icsk_af_ops->conn_request(sk, skb) < 0)
40 return 1;
41
42 consume_skb(skb);
43 return 0;
44 }
45 goto discard;
46
47 ...
这是TCP建立连接的核心所在,几乎所有状态的套接字,在收到数据报时都在这里完成处理。对于服务端来说,收到第一次握手报文时的状态为TCP_LISTEN,处理代码为:
1 //服务端第一次握手处理
2 case TCP_LISTEN:
3 if (th->ack)
4 return 1;
5
6 if (th->rst)
7 goto discard;
8
9 if (th->syn) {
10 if (th->fin)
11 goto discard;
12 // tcp_v4_do_rcv() -> tcp_rcv_state_process() -> tcp_v4_conn_request() -> tcp_v4_send_synack().
13 if (icsk->icsk_af_ops->conn_request(sk, skb) < 0)
14 return 1;
15
16 consume_skb(skb);
17 return 0;
18 }
19 goto discard;
接下将由tcp_v4_conn_request函数处理,而tcp_v4_conn_request实际上调用tcp_conn_request:

1 // tcp_v4_do_rcv() -> tcp_rcv_state_process() -> tcp_v4_conn_request() -> tcp_v4_send_synack().
2 int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
3 {
4 /* Never answer to SYNs send to broadcast or multicast */
5 if (skb_rtable(skb)->rt_flags & (RTCF_BROADCAST | RTCF_MULTICAST))
6 goto drop;
7
8 //tcp_request_sock_ops 定义在 tcp_ipv4.c 1256行
9
10 //inet_init --> proto_register --> req_prot_init -->初始化cache名
11 return tcp_conn_request(&tcp_request_sock_ops,
12 &tcp_request_sock_ipv4_ops, sk, skb);
13
14 drop:
15 tcp_listendrop(sk);
16 return 0;
17 }
18 int tcp_conn_request(struct request_sock_ops *rsk_ops,
19 const struct tcp_request_sock_ops *af_ops,
20 struct sock *sk, struct sk_buff *skb)
21 ...
在该函数中做了不少的事情,但是我们这里重点了解两点:
1. 分配一个request_sock对象来代表这次连接请求(状态为TCP_NEW_SYN_RECV),如果没有设置防范syn flood相关的选项,则将该request_sock添加到established状态的tcp_sock散列表(如果设置了防范选项,则request_sock对象都没有,只有建立完成时才会分配);
2. 调用tcp_v4_send_synack回复客户端ack,开启第二次握手。
我们看下该函数:

1 //向客户端发送SYN+ACK报文
2 static int tcp_v4_send_synack(const struct sock *sk, struct dst_entry *dst,
3 struct flowi *fl,
4 struct request_sock *req,
5 struct tcp_fastopen_cookie *foc,
6 enum tcp_synack_type synack_type)
7 {
8 const struct inet_request_sock *ireq = inet_rsk(req);
9 struct flowi4 fl4;
10 int err = -1;
11 struct sk_buff *skb;
12
13 /* First, grab a route. */
14
15 //查找到客户端的路由
16 if (!dst && (dst = inet_csk_route_req(sk, &fl4, req)) == NULL)
17 return -1;
18
19 //根据路由、传输控制块、连接请求块中的构建SYN+ACK段
20 skb = tcp_make_synack(sk, dst, req, foc, synack_type);
21
22 //生成SYN+ACK段成功
23 if (skb) {
24
25 //生成校验码
26 __tcp_v4_send_check(skb, ireq->ir_loc_addr, ireq->ir_rmt_addr);
27
28
29 //生成IP数据报并发送出去
30 err = ip_build_and_send_pkt(skb, sk, ireq->ir_loc_addr,
31 ireq->ir_rmt_addr,
32 ireq->opt);
33 err = net_xmit_eval(err);
34 }
35
36 return err;
37 }
代码较少,查找客户端路由,构造syn包,然后调用ip_build_and_send_pkt,依靠网络层将数据报发出去。至此,第一次握手完成,第二次握手服务端层面完成。
数据报到达客户端网卡,同样经过:网卡驱动-->netif_receive_skb()--->ip_rcv()--->ip_local_deliver_finish()---> tcp_v4_rcv() --> tcp_v4_do_rcv() 。
客户端socket的状态为TCP_SYN_SENT,所以直接进入tcp_rcv_state_process,处理该状态的代码为:
1 //客户端第二次握手处理 2 case TCP_SYN_SENT: 3 tp->rx_opt.saw_tstamp = 0; 4 5 //处理SYN_SENT状态下接收到的TCP段 6 queued = tcp_rcv_synsent_state_process(sk, skb, th); 7 if (queued >= 0) 8 return queued; 9 10 /* Do step6 onward by hand. */ 11 12 //处理完第二次握手后,还需要处理带外数据 13 tcp_urg(sk, skb, th); 14 __kfree_skb(skb); 15 16 //检测是否有数据需要发送 17 tcp_data_snd_check(sk); 18 return 0; 19 }
接着看tcp_rcv_synsent_state_process:

1 //在SYN_SENT状态下处理接收到的段,但是不处理带外数据
2 static int tcp_rcv_synsent_state_process(struct sock *sk, struct sk_buff *skb,
3 const struct tcphdr *th)
4 {
5 struct inet_connection_sock *icsk = inet_csk(sk);
6 struct tcp_sock *tp = tcp_sk(sk);
7 struct tcp_fastopen_cookie foc = { .len = -1 };
8 int saved_clamp = tp->rx_opt.mss_clamp;
9
10 //解析TCP选项并保存到传输控制块中
11 tcp_parse_options(skb, &tp->rx_opt, 0, &foc);
12 if (tp->rx_opt.saw_tstamp && tp->rx_opt.rcv_tsecr)
13 tp->rx_opt.rcv_tsecr -= tp->tsoffset;
14
15 ...
处理三种可能的包:
1. 带ack标志的,这是我们预期的;
2. 带rst标志的,直接丢掉传输控制块;
3. 带syn标志,但是没有ack标志,两者同时发起连接。
我们重点研究第一种情况。首先调用tcp_finish_connect设置sock状态为TCP_ESTABLISHED:

1 void tcp_finish_connect(struct sock *sk, struct sk_buff *skb)
2 {
3 struct tcp_sock *tp = tcp_sk(sk);
4 struct inet_connection_sock *icsk = inet_csk(sk);
5
6 //设置sock状态为TCP_ESTABLISHED
7 tcp_set_state(sk, TCP_ESTABLISHED);
8
9 if (skb) {
10 icsk->icsk_af_ops->sk_rx_dst_set(sk, skb);
11 security_inet_conn_established(sk, skb);
12 }
13 ...
接着延时发送或立即发送确认ack,我们先不去了解延时确认的东西,我们直接看直接发送确认ack,调用tcp_send_ack:

1 //主动连接时,向服务器端发送ACK完成连接,并更新窗口
2 void tcp_send_ack(struct sock *sk)
3 {
4 struct sk_buff *buff;
5
6 /* If we have been reset, we may not send again. */
7 if (sk->sk_state == TCP_CLOSE)
8 return;
9
10 tcp_ca_event(sk, CA_EVENT_NON_DELAYED_ACK);
11 ...
比较简单,无非是构造报文,然后交给网络层发送。至此第二次握手完成,客户端sock状态变为TCP_ESTABLISHED,第三次握手开始。我们之前说到服务端的sock的状态为TCP_NEW_SYN_RECV,报文到达网卡:
网卡驱动-->netif_receive_skb()--->ip_rcv()--->ip_local_deliver_finish()---> tcp_v4_rcv(),报文将被以下代码处理:
1 //网卡驱动-->netif_receive_skb()--->ip_rcv()--->ip_local_deliver_finish()---> tcp_v4_rcv()
2 int tcp_v4_rcv(struct sk_buff *skb)
3 {
4 .............
5
6
7 //收到握手最后一个ack后,会找到TCP_NEW_SYN_RECV状态的req,然后创建一个新的sock进入TCP_SYN_RECV状态,最终进入TCP_ESTABLISHED状态. 并放入accept队列通知select/epoll
8 if (sk->sk_state == TCP_NEW_SYN_RECV) {
9 struct request_sock *req = inet_reqsk(sk);
10 struct sock *nsk;
11
12 sk = req->rsk_listener;
13 if (unlikely(tcp_v4_inbound_md5_hash(sk, skb))) {
14 sk_drops_add(sk, skb);
15 reqsk_put(req);
16 goto discard_it;
17 }
18 ...
看下如何创建新sock,进入tcp_check_req():

1 struct sock *tcp_check_req(struct sock *sk, struct sk_buff *skb,
2 struct request_sock *req,
3 bool fastopen)
4 {
5 struct tcp_options_received tmp_opt;
6 struct sock *child;
7 const struct tcphdr *th = tcp_hdr(skb);
8 __be32 flg = tcp_flag_word(th) & (TCP_FLAG_RST|TCP_FLAG_SYN|TCP_FLAG_ACK);
9 bool paws_reject = false;
10 bool own_req;
11 ...
又回到了函数tcp_rcv_state_process,TCP_SYN_RECV状态的套接字将由一下代码处理:
1 //服务端第三次握手处理
2 case TCP_SYN_RECV:
3 if (!acceptable)
4 return 1;
5
6 if (!tp->srtt_us)
7 tcp_synack_rtt_meas(sk, req);
8
9 /* Once we leave TCP_SYN_RECV, we no longer need req
10 * so release it.
11 */
12 if (req) {
13 inet_csk(sk)->icsk_retransmits = 0;
14 reqsk_fastopen_remove(sk, req, false);
15 } else {
16 /* Make sure socket is routed, for correct metrics. */
17
18 //建立路由,初始化拥塞控制模块
19 icsk->icsk_af_ops->rebuild_header(sk);
20 tcp_init_congestion_control(sk);
21
22 tcp_mtup_init(sk);
23 tp->copied_seq = tp->rcv_nxt;
24 tcp_init_buffer_space(sk);
25 }
26 smp_mb();
27 //正常的第三次握手,设置连接状态为TCP_ESTABLISHED
28 tcp_set_state(sk, TCP_ESTABLISHED);
29 sk->sk_state_change(sk);
30
31 /* Note, that this wakeup is only for marginal crossed SYN case.
32 * Passively open sockets are not waked up, because
33 * sk->sk_sleep == NULL and sk->sk_socket == NULL.
34 */
35
36 //状态已经正常,唤醒那些等待的线程
37 if (sk->sk_socket)
38 sk_wake_async(sk, SOCK_WAKE_IO, POLL_OUT);
39
40 tp->snd_una = TCP_SKB_CB(skb)->ack_seq;
41 tp->snd_wnd = ntohs(th->window) << tp->rx_opt.snd_wscale;
42 tcp_init_wl(tp, TCP_SKB_CB(skb)->seq);
43
44 if (tp->rx_opt.tstamp_ok)
45 tp->advmss -= TCPOLEN_TSTAMP_ALIGNED;
46
47 if (req) {
48 /* Re-arm the timer because data may have been sent out.
49 * This is similar to the regular data transmission case
50 * when new data has just been ack‘ed.
51 *
52 * (TFO) - we could try to be more aggressive and
53 * retransmitting any data sooner based on when they
54 * are sent out.
55 */
56 tcp_rearm_rto(sk);
57 } else
58 tcp_init_metrics(sk);
59
60 if (!inet_csk(sk)->icsk_ca_ops->cong_control)
61 tcp_update_pacing_rate(sk);
62
63 /* Prevent spurious tcp_cwnd_restart() on first data packet */
64
65 //更新最近一次发送数据包的时间
66 tp->lsndtime = tcp_time_stamp;
67
68 tcp_initialize_rcv_mss(sk);
69
70 //计算有关TCP首部预测的标志
71 tcp_fast_path_on(tp);
72 break;
可以看到到代码对sock的窗口,mss等进行设置,以及最后将sock的状态设置为TCP_ESTABLISHED,至此三次握手完成。等待用户调用accept调用,取出套接字使用。
分析过程中的断点设置情况如下图:
现在给出大体的TCP三次握手协议栈从上至下提供的接口,具体的详细过程见上面的分析:
TCP三次握手协议栈从上至下提供的接口
如下图所示:
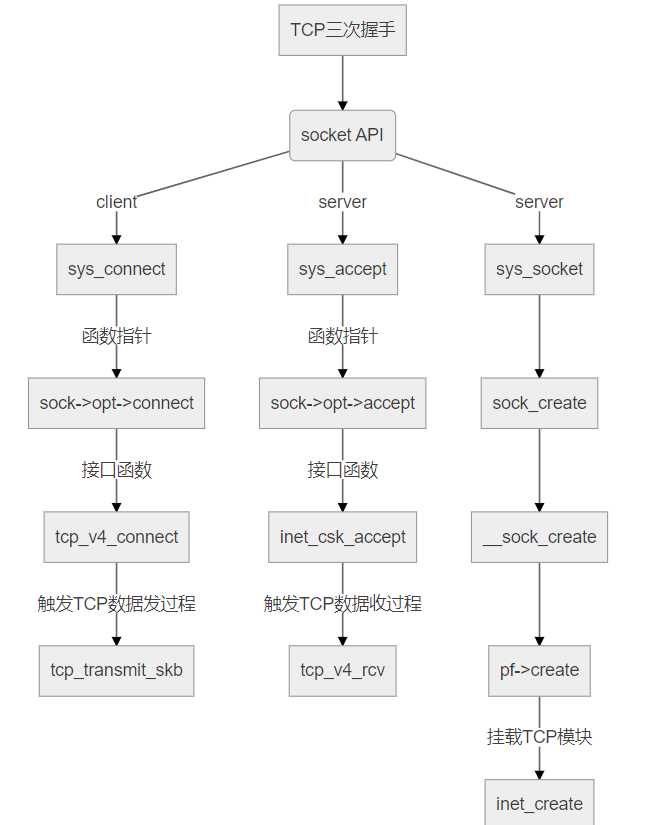
总结
本文内容主要分为三个部分,首先讲述了TCP协议的相关知识,接着谈到了与TCP通信联系密切的linux socket接口函数及应用层处理TCP连接的详细流程,最后通过gdb调试加阅读源码的方式,一步步揭开socket接口函数背后的TCP三次握手的神秘面纱,详细地从linux 系统函数调用的角度理解了TCP连接建立三次握手的过程,相信我们对TCP协议的理解又有了一个新的高度!
以上是关于TCP连接建立及相关socket深度探析的主要内容,如果未能解决你的问题,请参考以下文章