Pandas使用方法
Posted xiongying4
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pandas使用方法相关的知识,希望对你有一定的参考价值。

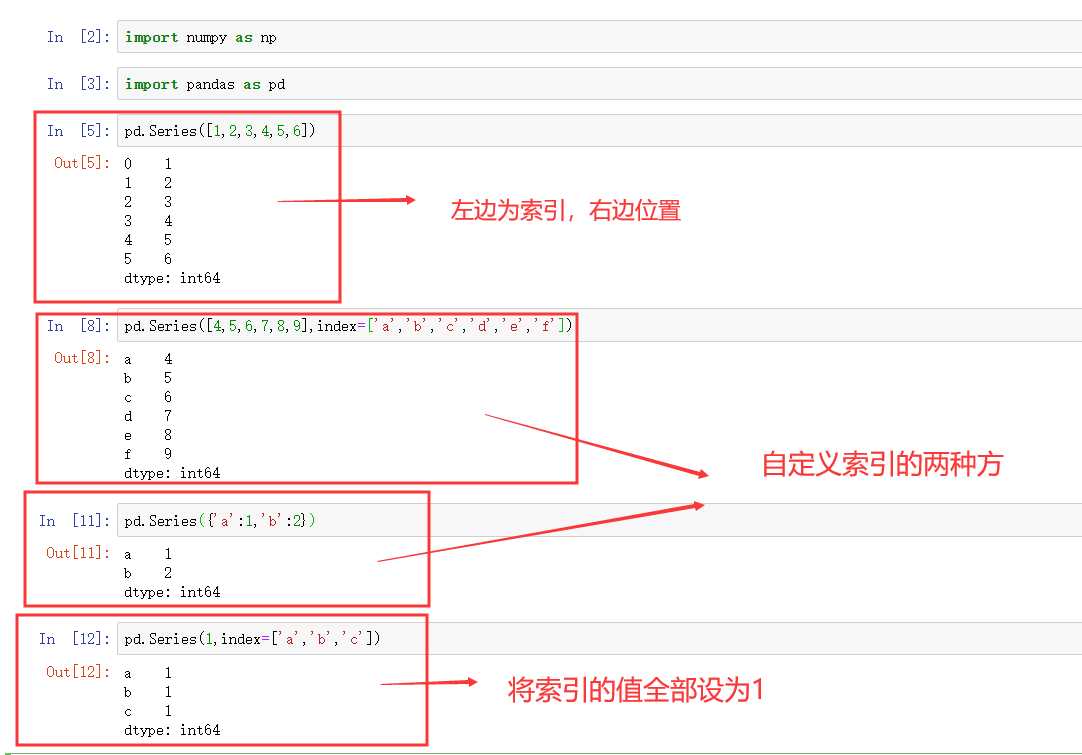
Pandas的主要功能:
- 具备对其功能的数据结构DataFrame,Series
- 集成时间序列功能
- 提供丰富的数学运算和操作
- 灵活处理缺失数据
安装方法:
pip install pandas
引用方法:
import pandas as pd

dropna() # 过滤掉值为NaN的行 fillna() # 填充缺失数据 isnull() # 返回布尔数组,缺失值对应为True notnull() # 返回布尔数组,缺失值对应为False

从ndarray创建Series:Series(arr) 与标量(数字):sr * 2 两个Series运算 通用函数:np.ads(sr) 布尔值过滤:sr[sr>0] 统计函数:mean()、sum()、cumsum()
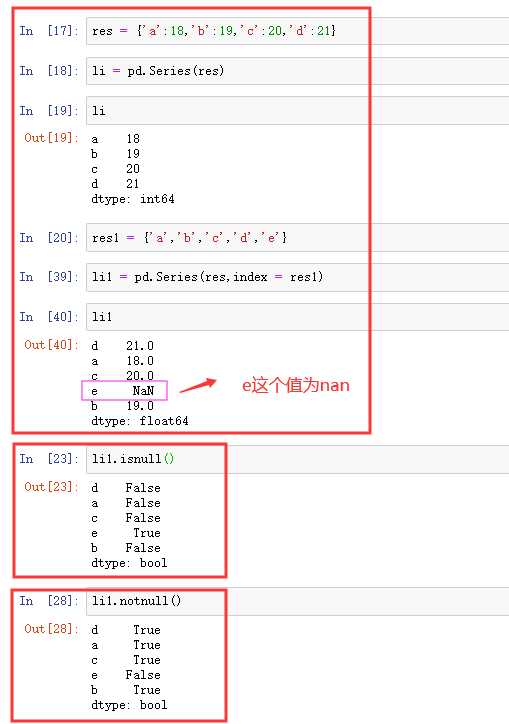
支持字典的特性:
- 从字典创建Series:Series(dic),
- In运算:‘a‘in sr、for x in sr
- 键索引:sr[‘a‘],sr[[‘a‘,‘b‘,‘d‘]]
- 键切片:sr[‘a‘:‘c‘]
- 其他函数:get(‘a‘,default=0)等
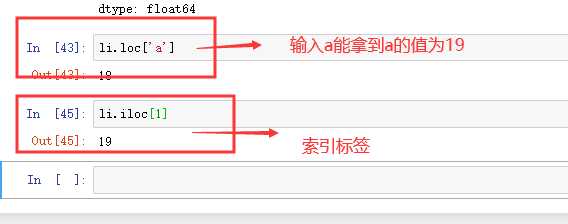
loc属性 # 以标签解释 iloc属性 # 以下标解释
sr1 = pd.Series([12,23,34], index=[‘c‘,‘a‘,‘d‘]) sr2 = pd.Series([11,20,10], index=[‘d‘,‘c‘,‘a‘,]) sr1 + sr2 运行结果: a 33 c 32 d 45 dtype: int64 # 可以通过这种索引对齐直接将两个Series对象进行运算 sr3 = pd.Series([11,20,10,14], index=[‘d‘,‘c‘,‘a‘,‘b‘]) sr1 + sr3 运行结果: a 33.0 b NaN c 32.0 d 45.0 dtype: float64 # sr1 和 sr3的索引不一致,所以最终的运行会发现b索引对应的值无法运算,就返回了NaN,一个缺失值
将两个Series对象相加时将缺失值设为0:
sr1 = pd.Series([12,23,34], index=[‘c‘,‘a‘,‘d‘]) sr3 = pd.Series([11,20,10,14], index=[‘d‘,‘c‘,‘a‘,‘b‘]) sr1.add(sr3,fill_value=0) 运行结果: a 33.0 b 14.0 c 32.0 d 45.0 dtype: float64 # 将缺失值设为0,所以最后算出来b索引对应的结果为14
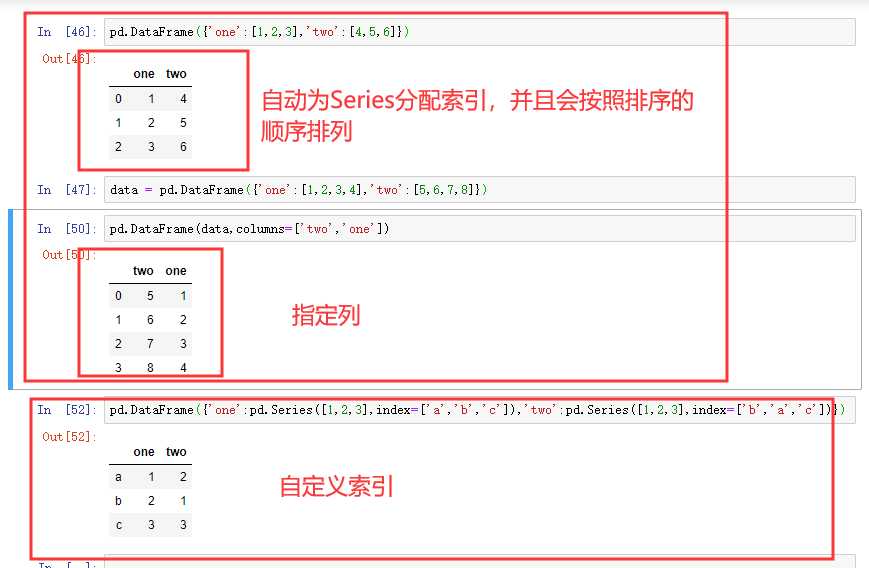
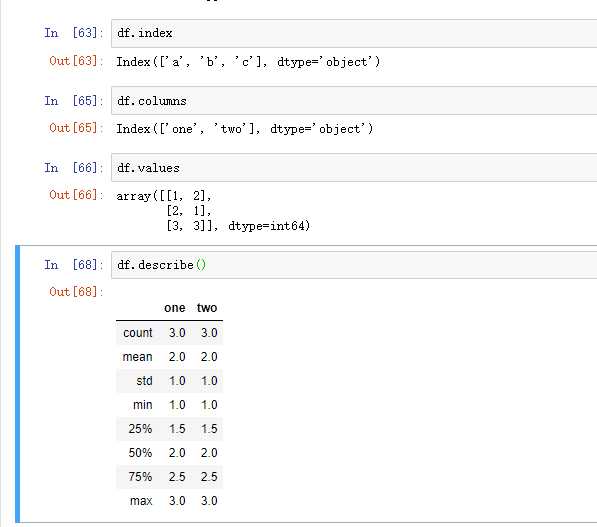
index 获取行索引
columns 获取列索引
T 转置
columns 获取列索引
values 获取值索引
df = pd.read_csv(‘需要读取的文件‘) df.head(‘需要查看的数量‘) df.to_csv(‘保存的文件‘)
以上是关于Pandas使用方法的主要内容,如果未能解决你的问题,请参考以下文章