深入理解TCP协议及其源代码
Posted xqqu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解TCP协议及其源代码相关的知识,希望对你有一定的参考价值。
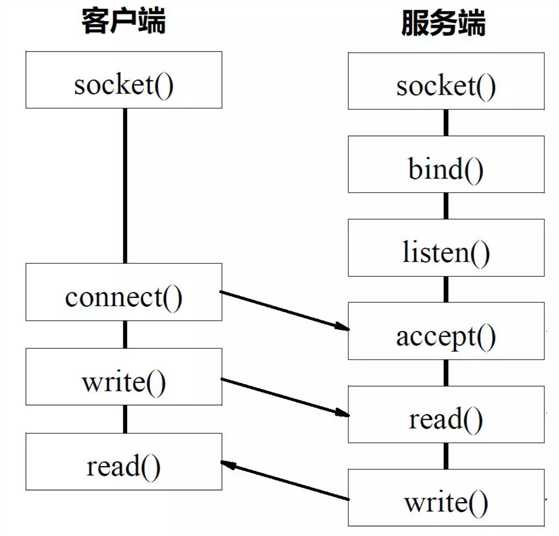
Socket
socket起源于Unix,而Unix/Linux基本哲学之一就是“一切皆文件”,都可以用“打开open –> 读写write/read –> 关闭close”模式来操作。
我的理解就是Socket就是该模式的一个实现:即socket是一种特殊的文件,一些socket函数就是对其进行的操作(读/写IO、打开、关闭)。
Socket()函数返回一个整型的Socket描述符,随后的连接建立、数据传输等操作都是通过该Socket实现的。
Socket通信的数据传输方式,常用的有两种:
a、SOCK_STREAM:表示面向连接的数据传输方式。数据可以准确无误地到达另一台计算机,如果损坏或丢失,可以重新发送,但效率相对较慢。常见的 http 协议就使用 SOCK_STREAM 传输数据,因为要确保数据的正确性,否则网页不能正常解析。
b、SOCK_DGRAM:表示无连接的数据传输方式。计算机只管传输数据,不作数据校验,如果数据在传输中损坏,或者没有到达另一台计算机,是没有办法补救的。也就是说,数据错了就错了,无法重传。因为 SOCK_DGRAM 所做的校验工作少,所以效率比 SOCK_STREAM 高。
TCP协议
TCP协议全称: 传输控制协议, 顾名思义, 就是要对数据的传输进行一定的控制.
先来看看它的报头

连接管理机制
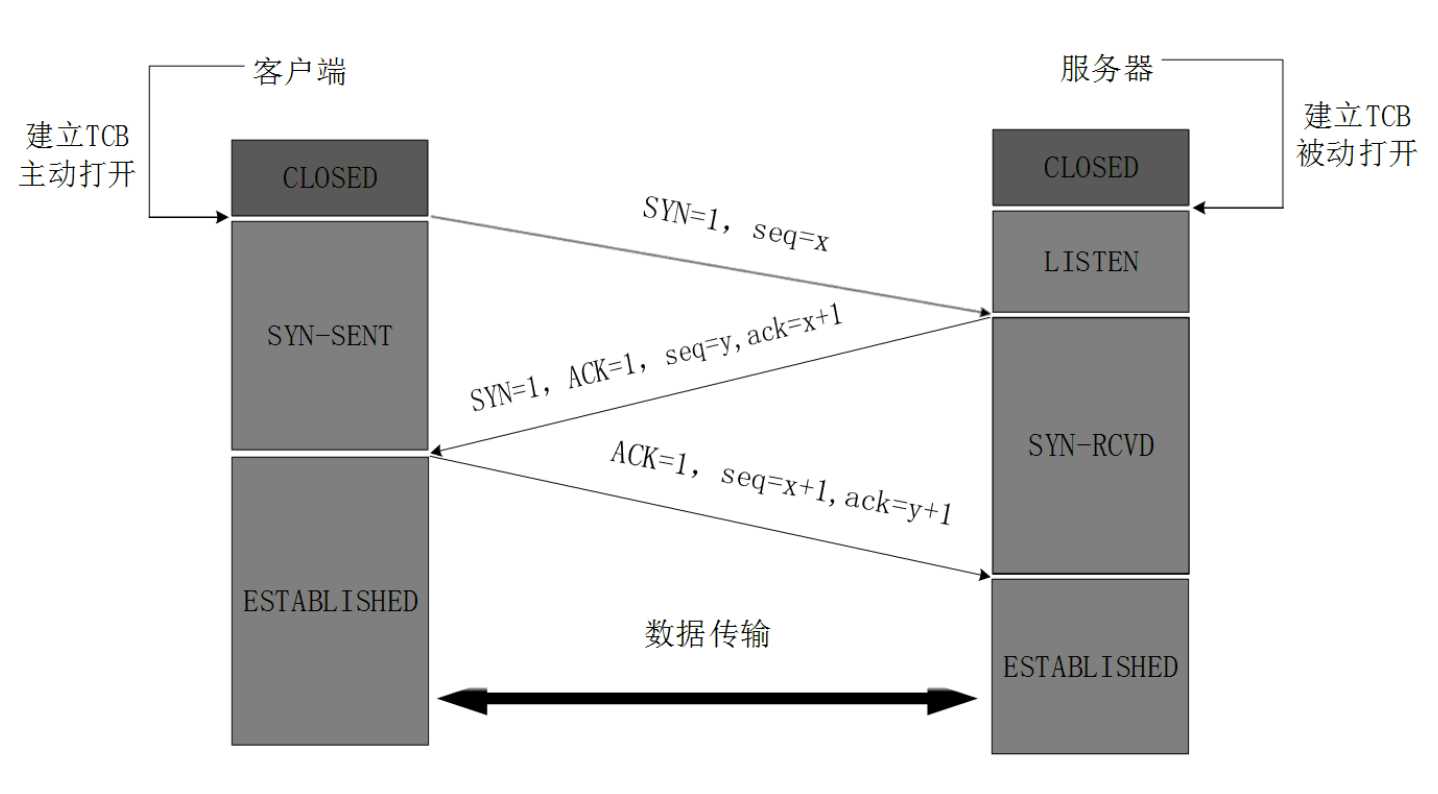
正常情况下, tcp需要经过三次握手建立连接, 四次挥手断开连接.
那么什么是三次握手? 什么是四次挥手呢?
三次握手
第一次:
客户端 - - > 服务器 此时服务器知道了客户端要建立连接了
第二次:
客户端 < - - 服务器 此时客户端知道服务器收到连接请求了
第三次:
客户端 - - > 服务器 此时服务器知道客户端收到了自己的回应
到这里, 就可以认为客户端与服务器已经建立了连接.
再来看个图.
1, 客户端进程发出连接释放报文,并且停止发送数据。
释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
2, 服务器收到连接释放报文,发出确认报文,ACK=1,确认序号为 u+1,并且带上自己的序列号seq=v,此时服务端就进入了CLOSE-WAIT(关闭等待)状态。
TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
3, 客户端收到服务器的确认请求后,此时客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最终数据)
4, 服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,确认序号为v+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
5, 客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,确认序号为w+1,而自己的序列号是u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
6, 服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
TCP初始化
TCP协议相关的代码主要集中在linux-5.0.1/net/ipv4/目录下,在linux-5.0.1/net/ipv4/af_inet.c中可以查看TCP/IP协议栈的初始化的函数入口inet_init:
static int __init inet_init(void)
{
...
rc = proto_register(&tcp_prot, 1);
if (rc)
goto out;
...
/*
* Tell SOCKET that we are alive...
*/
(void)sock_register(&inet_family_ops);
...
/*
* Add all the base protocols.
*/
...
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol
", __func__);
...
/* Register the socket-side information for inet_create. */
for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r)
INIT_LIST_HEAD(r);
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
...
/*
* Set the IP module up
*/
ip_init();
/* Setup TCP slab cache for open requests. */
tcp_init();
...
}
fs_initcall(inet_init);
tcp_prot结构体可在linux-5.0.1/net/ipv4/tcp_ipv4.c中寻得,tcp_prot指定了TCP协议栈的访问接口函数,socket接口层里sock->opt->connect和sock->opt->accept对应的接口函数即是在这里制定的,sock->opt->connect实际调用的是tcp_v4_connect函数,sock->opt->accept实际调用的是inet_csk_accept函数。tcp_init函数可在linux-5.0.1/net/ipv4/tcp.c中寻得,其中关键的工作就是tcp_tasklet_init初始化了负责发送字节流进行滑动窗口管理的tasklet,即创建了线程来专门负责这个工作。相关代码如下所示:
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.pre_connect = tcp_v4_pre_connect,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock,
.destroy = tcp_v4_destroy_sock,
.shutdown = tcp_shutdown,
.setsockopt = tcp_setsockopt,
.getsockopt = tcp_getsockopt,
.keepalive = tcp_set_keepalive,
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
.sendpage = tcp_sendpage,
.backlog_rcv = tcp_v4_do_rcv,
.release_cb = tcp_release_cb,
...
};
void __init tcp_init(void)
{
...
tcp_v4_init();
tcp_metrics_init();
BUG_ON(tcp_register_congestion_control(&tcp_reno) != 0);
tcp_tasklet_init();
}
TCP三次握手跟踪
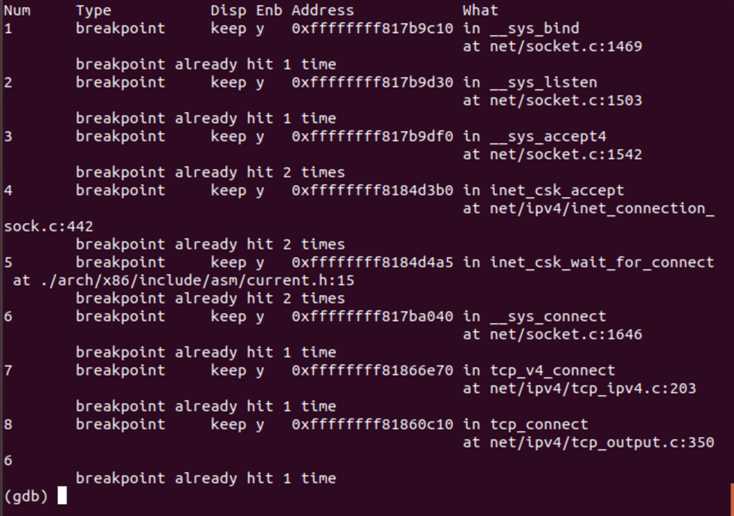
接下来我们对TCP“三次握手”的过程进行跟踪、验证和分析。在一个终端打开qemu启动MenuOS,在另一个终端用gdb读入linux-5.0.1的vmlinux,通过端口1234与qemu建立连接,设置断点如下:
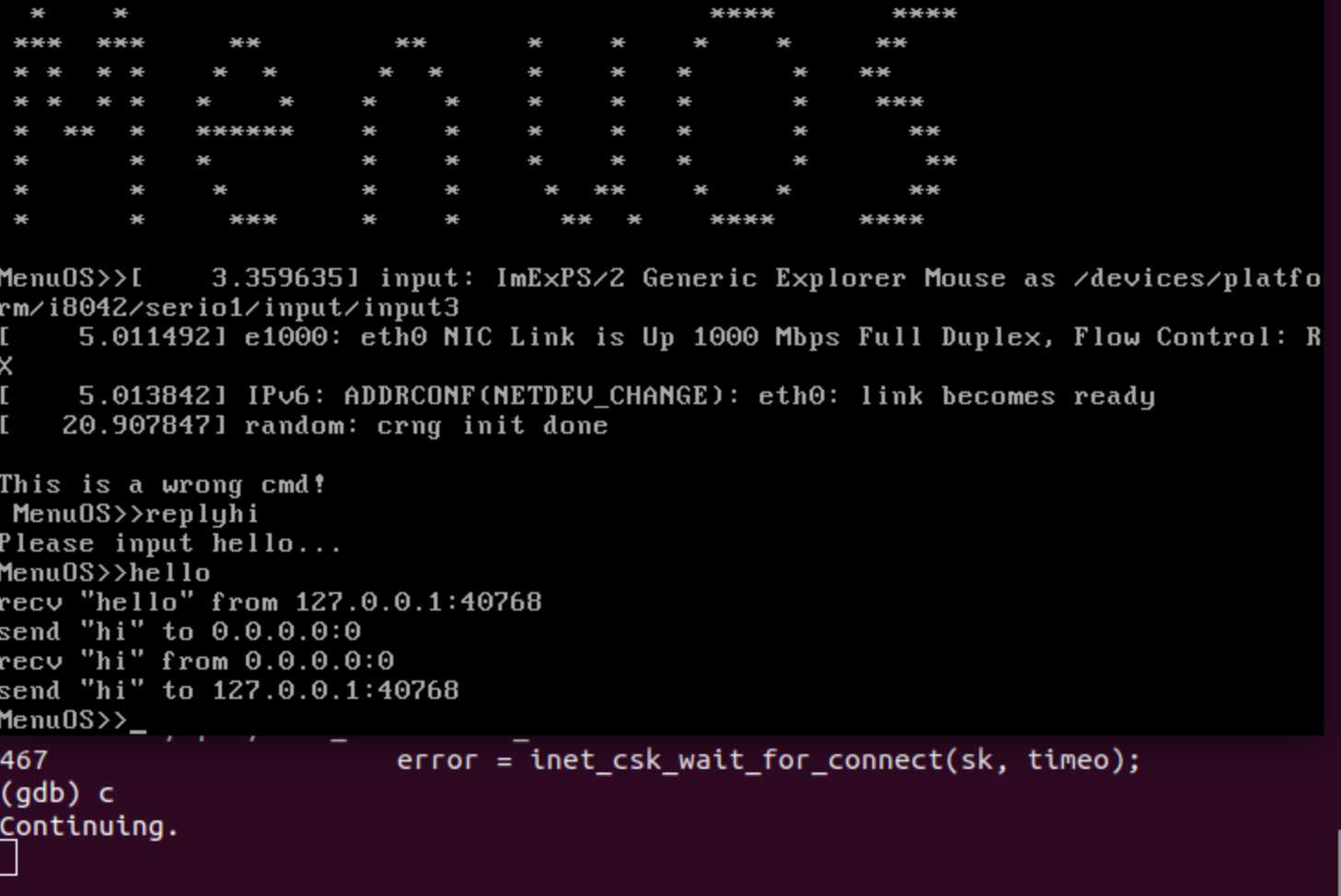
在qemu输入replyhi指令,然后在gdb中持续输入continue指令,直到无法继续;再在qemu中输入hello指令,然后在gdb中持续输入continue指令,直到无法继续。此时,qemu中指令已完成运行如下图所示:
gdb中显示的函数调用顺序如下图所示:
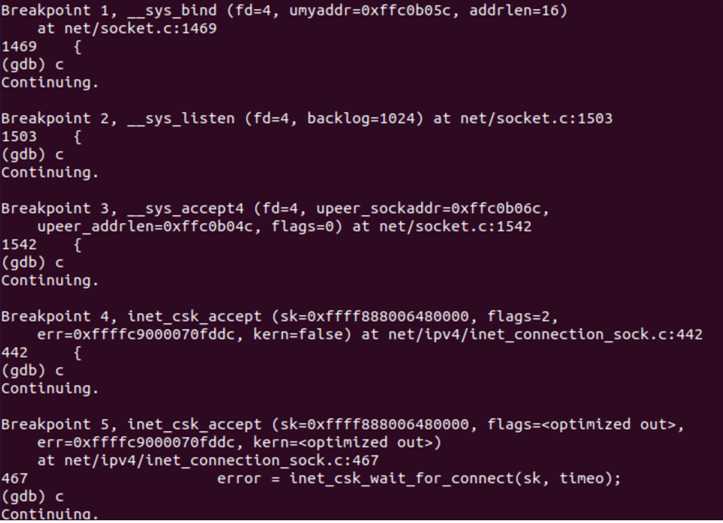
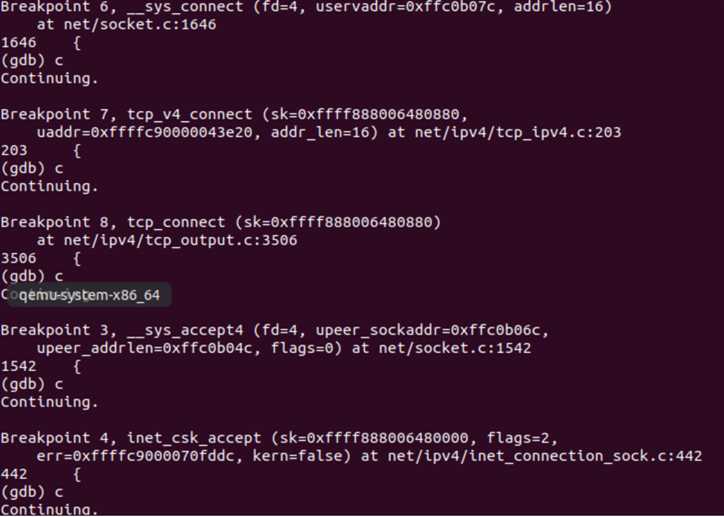
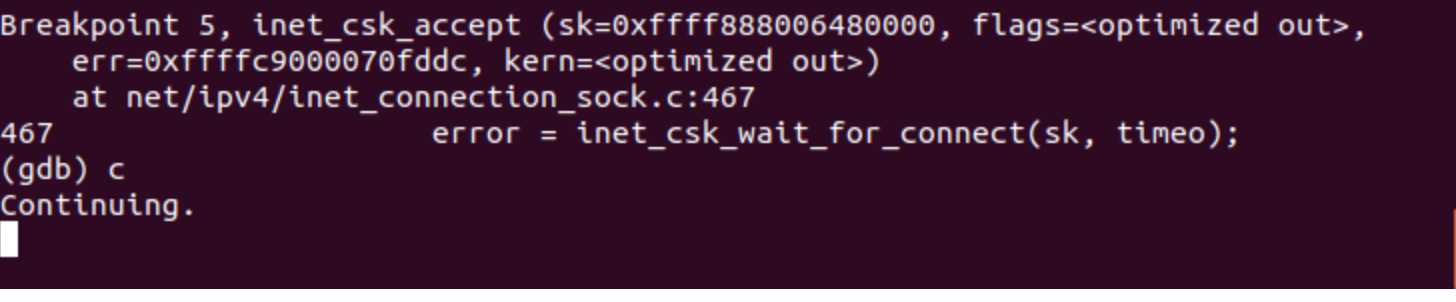
Server端调用的inet_csk_accept函数会请求队列中取出一个连接请求,其源代码可在linux-5.0.1/net/ipv4/tcp_ipv4.c中寻得:
/*
* This will accept the next outstanding connection.
*/
struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct request_sock_queue *queue = &icsk->icsk_accept_queue;
struct request_sock *req;
struct sock *newsk;
int error;
lock_sock(sk);
/* We need to make sure that this socket is listening,
* and that it has something pending.
*/
error = -EINVAL;
if (sk->sk_state != TCP_LISTEN)
goto out_err;
/* Find already established connection */
if (reqsk_queue_empty(queue)) {
long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK);
/* If this is a non blocking socket don‘t sleep */
error = -EAGAIN;
if (!timeo)
goto out_err;
error = inet_csk_wait_for_connect(sk, timeo);
if (error)
goto out_err;
}
req = reqsk_queue_remove(queue, sk);
newsk = req->sk;
if (sk->sk_protocol == IPPROTO_TCP &&
tcp_rsk(req)->tfo_listener) {
spin_lock_bh(&queue->fastopenq.lock);
if (tcp_rsk(req)->tfo_listener) {
/* We are still waiting for the final ACK from 3WHS
* so can‘t free req now. Instead, we set req->sk to
* NULL to signify that the child socket is taken
* so reqsk_fastopen_remove() will free the req
* when 3WHS finishes (or is aborted).
*/
req->sk = NULL;
req = NULL;
}
...return newsk;
...
}
EXPORT_SYMBOL(inet_csk_accept);
在linux-5.0.1/net/ipv4/tcp_ipv4.c中可寻得tcp_v4_connect函数的源代码:
/* This will initiate an outgoing connection. */
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len)
{
...
rt = ip_route_connect(fl4, nexthop, inet->inet_saddr,
RT_CONN_FLAGS(sk), sk->sk_bound_dev_if,
IPPROTO_TCP,
orig_sport, orig_dport, sk);
.../* Socket identity is still unknown (sport may be zero).
* However we set state to SYN-SENT and not releasing socket
* lock select source port, enter ourselves into the hash tables and
* complete initialization after this.
*/
tcp_set_state(sk, TCP_SYN_SENT);
...
rt = ip_route_newports(fl4, rt, orig_sport, orig_dport,
inet->inet_sport, inet->inet_dport, sk);
...
err = tcp_connect(sk);
...
}
EXPORT_SYMBOL(tcp_v4_connect);
tcp_v4_connect函数中调用的tcp_connect函数,源代码可在linux-5.0.1/net/ipv4/tcp_output.c中寻得:
/* Do all connect socket setups that can be done AF independent. */
static void tcp_connect_init(struct sock *sk)
{
const struct dst_entry *dst = __sk_dst_get(sk);
struct tcp_sock *tp = tcp_sk(sk);
__u8 rcv_wscale;
u32 rcv_wnd;
/* We‘ll fix this up when we get a response from the other end.
* See tcp_input.c:tcp_rcv_state_process case TCP_SYN_SENT.
*/
tp->tcp_header_len = sizeof(struct tcphdr);
if (sock_net(sk)->ipv4.sysctl_tcp_timestamps)
tp->tcp_header_len += TCPOLEN_TSTAMP_ALIGNED;
#ifdef CONFIG_TCP_MD5SIG
if (tp->af_specific->md5_lookup(sk, sk))
tp->tcp_header_len += TCPOLEN_MD5SIG_ALIGNED;
#endif
/* If user gave his TCP_MAXSEG, record it to clamp */
if (tp->rx_opt.user_mss)
tp->rx_opt.mss_clamp = tp->rx_opt.user_mss;
tp->max_window = 0;
tcp_mtup_init(sk);
tcp_sync_mss(sk, dst_mtu(dst));
tcp_ca_dst_init(sk, dst);
if (!tp->window_clamp)
tp->window_clamp = dst_metric(dst, RTAX_WINDOW);
tp->advmss = tcp_mss_clamp(tp, dst_metric_advmss(dst));
tcp_initialize_rcv_mss(sk);
/* limit the window selection if the user enforce a smaller rx buffer */
if (sk->sk_userlocks & SOCK_RCVBUF_LOCK &&
(tp->window_clamp > tcp_full_space(sk) || tp->window_clamp == 0))
tp->window_clamp = tcp_full_space(sk);
rcv_wnd = tcp_rwnd_init_bpf(sk);
if (rcv_wnd == 0)
rcv_wnd = dst_metric(dst, RTAX_INITRWND);
tcp_select_initial_window(sk, tcp_full_space(sk),
tp->advmss - (tp->rx_opt.ts_recent_stamp ? tp->tcp_header_len - sizeof(struct tcphdr) : 0),
&tp->rcv_wnd,
&tp->window_clamp,
sock_net(sk)->ipv4.sysctl_tcp_window_scaling,
&rcv_wscale,
rcv_wnd);
tp->rx_opt.rcv_wscale = rcv_wscale;
tp->rcv_ssthresh = tp->rcv_wnd;
sk->sk_err = 0;
sock_reset_flag(sk, SOCK_DONE);
tp->snd_wnd = 0;
tcp_init_wl(tp, 0);
tcp_write_queue_purge(sk);
tp->snd_una = tp->write_seq;
tp->snd_sml = tp->write_seq;
tp->snd_up = tp->write_seq;
tp->snd_nxt = tp->write_seq;
if (likely(!tp->repair))
tp->rcv_nxt = 0;
else
tp->rcv_tstamp = tcp_jiffies32;
tp->rcv_wup = tp->rcv_nxt;
tp->copied_seq = tp->rcv_nxt;
inet_csk(sk)->icsk_rto = tcp_timeout_init(sk);
inet_csk(sk)->icsk_retransmits = 0;
tcp_clear_retrans(tp);
}
static void tcp_connect_queue_skb(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
struct tcp_skb_cb *tcb = TCP_SKB_CB(skb);
tcb->end_seq += skb->len;
__skb_header_release(skb);
sk->sk_wmem_queued += skb->truesize;
sk_mem_charge(sk, skb->truesize);
tp->write_seq = tcb->end_seq;
tp->packets_out += tcp_skb_pcount(skb);
}
以上是关于深入理解TCP协议及其源代码的主要内容,如果未能解决你的问题,请参考以下文章