多库取数的性能优化方案
Posted shiguangshiyi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多库取数的性能优化方案相关的知识,希望对你有一定的参考价值。
当数据库表数据量较大时,报表性能往往不高,此时仅针对 SQL 或报表端进行优化,效果往往不明显。这种情况下要显著提升性能,可以考虑采用并行多库的方式,即采用一定规则(如时间)将数据分库分段存储,而报表同时访问多个数据库进行数据计算,最后在报表中进行汇总展现。
不过,一般报表工具并不具备这种并行取数汇总的能力,因此访问多个数据库读取分段数据就需要借助 Java 等高级语言完成,而使用 Java 编写这样的并行程序也并不简单,更何况 Java 本身也缺乏对批量数据计算的基础支持,不支持表达式参数和动态数据结构。凡此种种,使得一般报表工具难以直接使用并行多库的方式提升性能。
本文介绍的润乾报表内置了专门用于数据计算的集算引擎,所提供的并行计算能力允许用户从多个数据库中同时读取数据并在报表端进行汇总展现,从而简单快捷地提升报表性能。
(注:并行多库功能需要结合集算器实现。)
下面通过一个例子简单说明并行多库的使用方法(以 mysql 为例),更多实现细节可以参考润乾报表的相关文档资料:
某电信企业为了提高报表性能,计划将用户服务使用信息按照统计地区分库存储在 4 个 mysql 数据库中,信息统计报表根据指定时间段、品牌等条件过滤查询后,汇总数据。使用润乾报表进行并行分库查询的步骤如下:
1 使用集算器编写并行脚本,实现从多个数据库取数后汇总结果。
并行脚本:
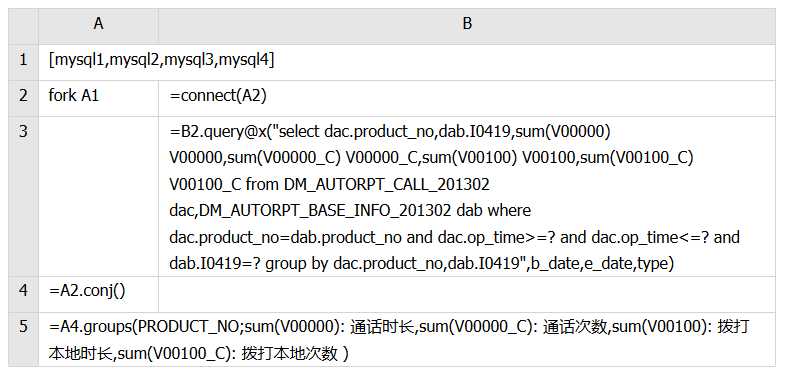
上述脚本启动了 4 个线程同时从 4 个数据库取数计算,最后将结果归并汇总。代码说明如下:
A1:指定了 4 个数据源名称,每个并行线程连接不同的数据库
A2:使用多线程执行本网格中的代码块,这里启动了 4 个子线程
B2:在每个线程中分别连接各自的数据源
B3:向指定数据源发出 SQL 执行进行数据库内的汇总并取回结果。这时 4 个数据库会同时分别执行各自的 SQL 语句,执行后自动关闭连接。
A4:合并子线程返回的结果
A5:再次汇总合并后的结果,该结果将返回给报表。
完成并行多库运算有两个关键点。一是能够让多个数据库并行工作(第 2-3 行完成),这需要报表引擎提供简易的并行程序编写机制。二是能将并行计算的结果再次汇总(第 4,5 行完成),因为各分库的结果可能有重复数据,这就需要报表引擎有较强的批量数据再计算能力。
2 在润乾报表中调用上述集算脚本作为数据集,编辑报表表达式完成报表制作

小结:并行多库适用于源数据量较大,但统计后数据量不大的情况。上面的例子针对每个数据库建立一个连接取数,事实上采用并行程序还可以同时建立多个连接进行查询,从而进一步提高报表查询效率和整体性能。
以上是关于多库取数的性能优化方案的主要内容,如果未能解决你的问题,请参考以下文章