Data语意学
Posted tianzeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Data语意学相关的知识,希望对你有一定的参考价值。
先看一段代码
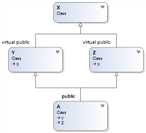
class X {}; class Y : public virtual X {}; class Z : public virtual X {}; class A : public Y, public Z {}; // sizeof(X)的结果为1 // sizeof(Y)的结果为8 // sizeof(Z)的结果为8 // sizeof(A)的结果为12
实际上,class X并不为空,它被编译器安插了一个隐藏的1 byte,这样使得class X的每个object在内存中拥有不同的地址。但是为什么class Y,class Z的sizeof大小是8呢?
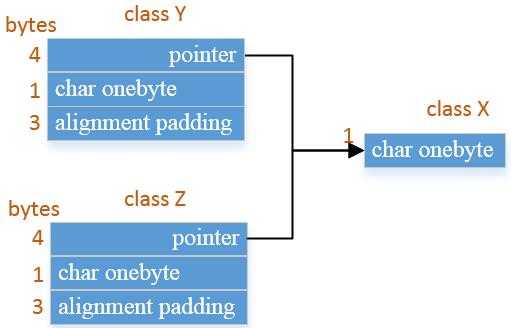
class Y,class Z的大小受到三个因素的影响:
- 语言本身造成的额外负担:当语言支持virtual base classes特性时,就会需要一些额外的负担来实现,这表现在某种形式的pointer上,在32位机器上,指针占有4 bytes,它或指向virtual base class object,或指向一个相关的表格,该表格中存放的若不是virtual base class object的地址,就是偏移位置(offset)。
- 编译器对于特殊情况提供的优化处理:virtual base class object的1 bytes也出现在class Y,class Z中,传统上它被放在derived class的尾部部分。
- Alignment的限制:class Y,class Z的大小本应为5 bytes,但为了使在内存中更有效的存取,会将其调整为某数的整数倍,在32位机器上调整为4 bytes的整数倍。
某些编译器(例如我用的vs2013)为我们提供了对empty virtual base class的特殊支持,就是将一个empty virtual base class视为derived class object最开头的一部分,也就是说derived class现在有member了,它不再是空了,也就不需要编译器安插那1 byte,自然也就不必为alignment padding提供3 bytes了。
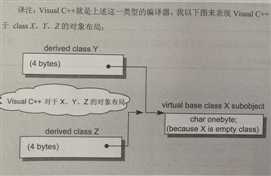
现在它们的格局是上图这样的了。class Y,class Z的sizeof就是4 bytes了,当然class X还是一个empty class编译器依然会安插1 byte。那么class A的sizeof又会是8 bytes,因为它不存在base class subobject那1 bytes了。

对于virtual inheritance(虚拟继承)而言,在一个derived class中只会存在一份virtual base class subobject,因此,class A的大小由以下几点决定:
- 被大家共享的唯一一个class X实例,大小为1 byte;
- base class Y大小减去“因virtual base class X而配置”的4 bytes,剩下的大小为4 bytes;base class Z同理;
- class A自己的大小为0
- class A的Alignment边界调整,4+4+1=9,做调整后为12
通过上面三点,可知class A的大小为12 bytes了。
c++ Standard并不强制规定“base class subobject的排列顺序”或“不同存取层级的data members的排列顺序”。data members是整个class在程序执行时的某种状态,nonstatic data members放置的是“个别的class object”感兴趣的数据。
一、Data Member的绑定
早期的c++程序设计风格:
- 把所有的data members放在class 声明起头处,以保证正确的绑定
- 把所有的inline functions不管大小都放在class声明外
一个inline函数实体,在整个class声明未被完全看见前,是不会被评估求值的。如果inline在函数体内部,那么对函数的分析直至class声明的右大括号出现才开始。所以在inline member function躯体之内的一个data member绑定操作,会在整个class声明后才发生。即:
- inline member functin躯体之内的一个data member绑定操作会在整个class声明完成之后才发生。
- argument list中的名称还是会在它们第一次遭遇时被适当地决议。
- 为避免错误,早期出现三种防御性代码风格,把data members放在class声明开始处,把inline functions放在class声明之外,把nested type声明放在class的起始处。
二、Data Member的布局
- static data members放在程序的data segment中,和class objects无关。
- 同一个access section中的data members的排列符合较晚出现的data members在class object中有较高的地址(因为可能存在边界调整导致地址不连续)。
- 允许多个access section中的data members自由排列(但是没有编译器这么做)。
- derived class members和base classes members可以自由排列。
- 在大部分编译器上头,base class members总是先出现,但属于virtual base class的除外。
- 编译器内部产生出来的data members可自由地放在任何位置上。
三、Data Member的存取
- 通过对象、引用或指针存取一个static data member的成本是一样的,存取不会招致任何空间上或时间上的额外负担(因为member不在class object中,所以存取不需通过object)。
- 通过对象、引用或指针存取一个nonstatic data member的成本,其效率和存取一个C struct member或一个nonderived class的member(单一继承或多重继承)是一样的(多重继承的时候,members的位置在编译时就固定了,存取members只是一个简单的offset运算)。
- 通过引用或指针比通过对象存取一个virtual base class的member的速度会稍慢(因为不知道这个引用或指针指向哪一种class type,也就不知道编译期这个member真正的offset的位置,所以这个存取操作必须延迟至执行期,经由一个额外的间接导引,才能够解决)。
若取一个static data member地址,会得到得到数据类型的指针,而不是指向class member的指针,因为static member并不在任何一个class object。
若存取nonstatic data member,编译器需要把class object的起始地址+data member的偏移位置(offset)
origin.y=0.0; //那么&origin.y将等于 &origin+(&Point3d::y-1);
指向data member的指针,其offset值总是被加上1,这样编译器可以区分出“一个指向data member的指针,用以指向class的第一个member”和“一个指向data member的指针,没有指向任何member”两种情况。
以上是关于Data语意学的主要内容,如果未能解决你的问题,请参考以下文章