sqoop--数据库和hdfs之间的搬运工
Posted traditional
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sqoop--数据库和hdfs之间的搬运工相关的知识,希望对你有一定的参考价值。
sqoop简介
sqoop是一款开源的工具,主要用于在hadoop和与传统的数据库之间进行的数据的传递,可以将一个关系型数据库中的数据导入到hadoop的hdfs中,也可以将hdfs的数据导入到关系型数据库中。sqoop的命名由来就是sql?to?hadoop,它的原理就是将导入或者导出命令翻译成MapReduce来实现,在翻译出的MapReduce中对inputformat和outputformat进行定制。
sqoop安装
安装sqoop首先要安装java和hadoop,当然我这里已经安装好了,大数据组件的安装很简单,可以参考我的其他博客。然后我们安装sqoop,这里我采用的是1.4.5版本的,目前sqoop有2.x版本,但是建议使用1.x。另外我使用的是cdh版本的,其实不光是sqoop,基本上所有大数据组件,个人学习的话,都建议使用cdh版本,会自动帮你规避掉很多问题。下载地址:http://archive.cloudera.com/cdh5/cdh/5/,可以去里面找任意的大数据组件。
我这里已经安装好了,我们来看一下目录结构
我们看到这和其他大数据组件的目录结构是类似的,都是里面带一个bin目录,当然hadoop还有sbin,如果只有bin没有sbin,那么可以认为是把sbin目录的内容合并到bin目录里面去了。然后是conf,配置文件存放的目录,docs是文档,lib则是一些jar包等等。
修改配置文件
cd到conf目录下,修改配置文件。

首先修改sqoop-env.sh,但是我们发现没有这个配置文件,不过有一个template,所以要cp一份,然后将其他组件的HOME目录配进去
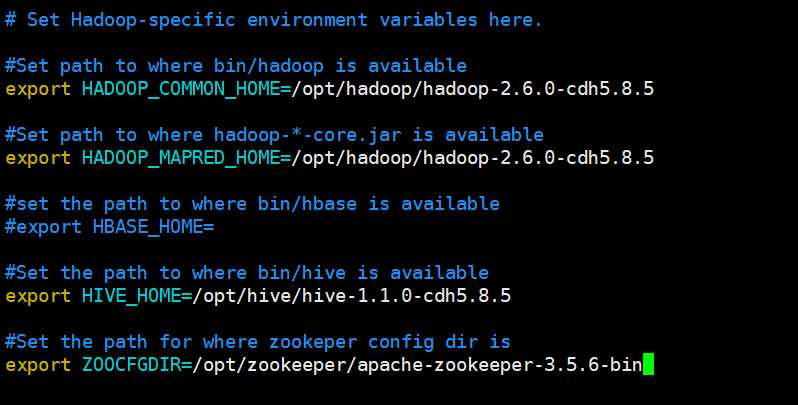
如果没有的话就不需要配,比如我这里没有hbase,所以就不配了。配置哪些就支持哪些,不配的话也不影响其他功能的使用,只是在启动的时候会弹出一些警告。另外我们一会儿会通过sqoop导入导出mysql的数据,所以需要一个mysql的驱动包,这里直接去菜鸟教程里面下载即可,然后丢到lib目录里面即可。
我们可以通过一个命令查看,配置是否正确
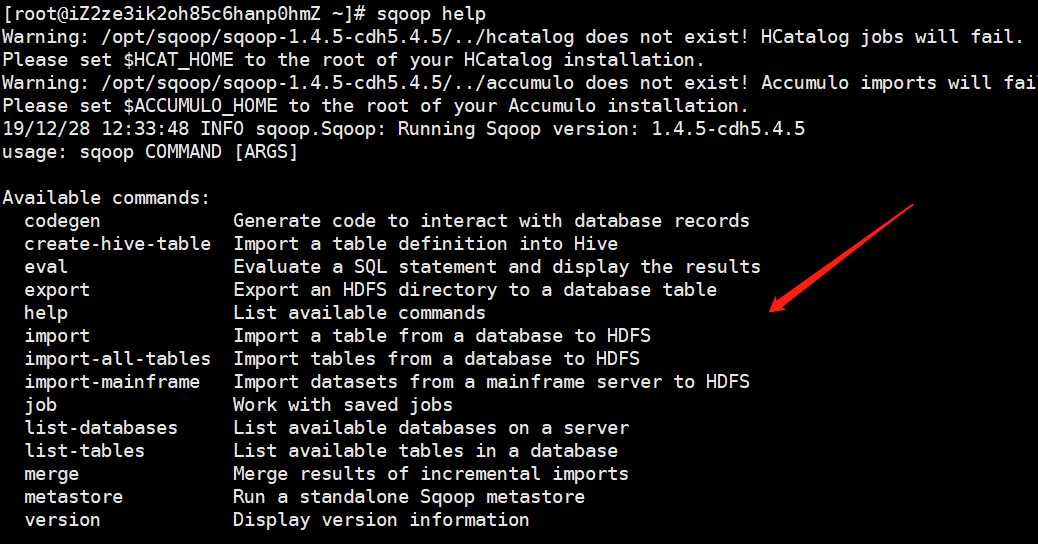
出现如下,说明配置成功。我们看到上面有一些警告,告诉我们有些东西没有配置,不过不影响我们其他功能的使用。
下面我们来连接一下mysql,注意:我们只是丢了一个mysql的驱动包进去,但是没有进行相关的配置,这就意味着我们需要在连接的时候指定。先来看看我的mysql能不能启动
看到是可以连接的,下面我们来使用sqoop连接一下。
命令:sqoop list-databases --connect jdbc:mysql://localhost:3306/ --username root --password 123456
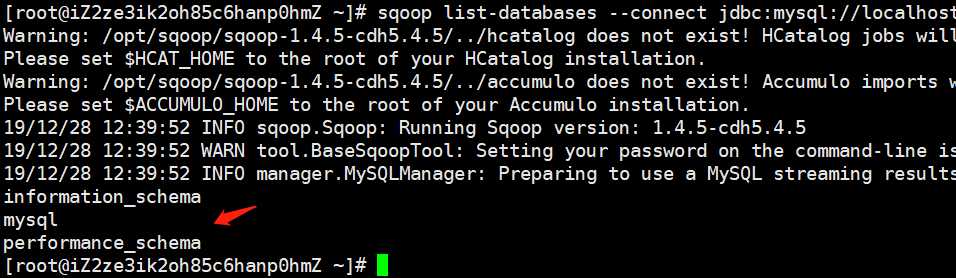
我们看到mysql的数据库信息被打印了出来,证明连接成功
导入数据
在sqoop中,导入和导出的概念比较绝对。从非大数据集群(比如:RDBMS,关系型数据库)向大数据集群(hadoop,hive,hbase)中传输数据,叫做导入。相反叫做导出。
从RDBMS到HDFS
我们在mysql中创建一张表,然后写入一些数据,使用sqoop导入到hdfs中。
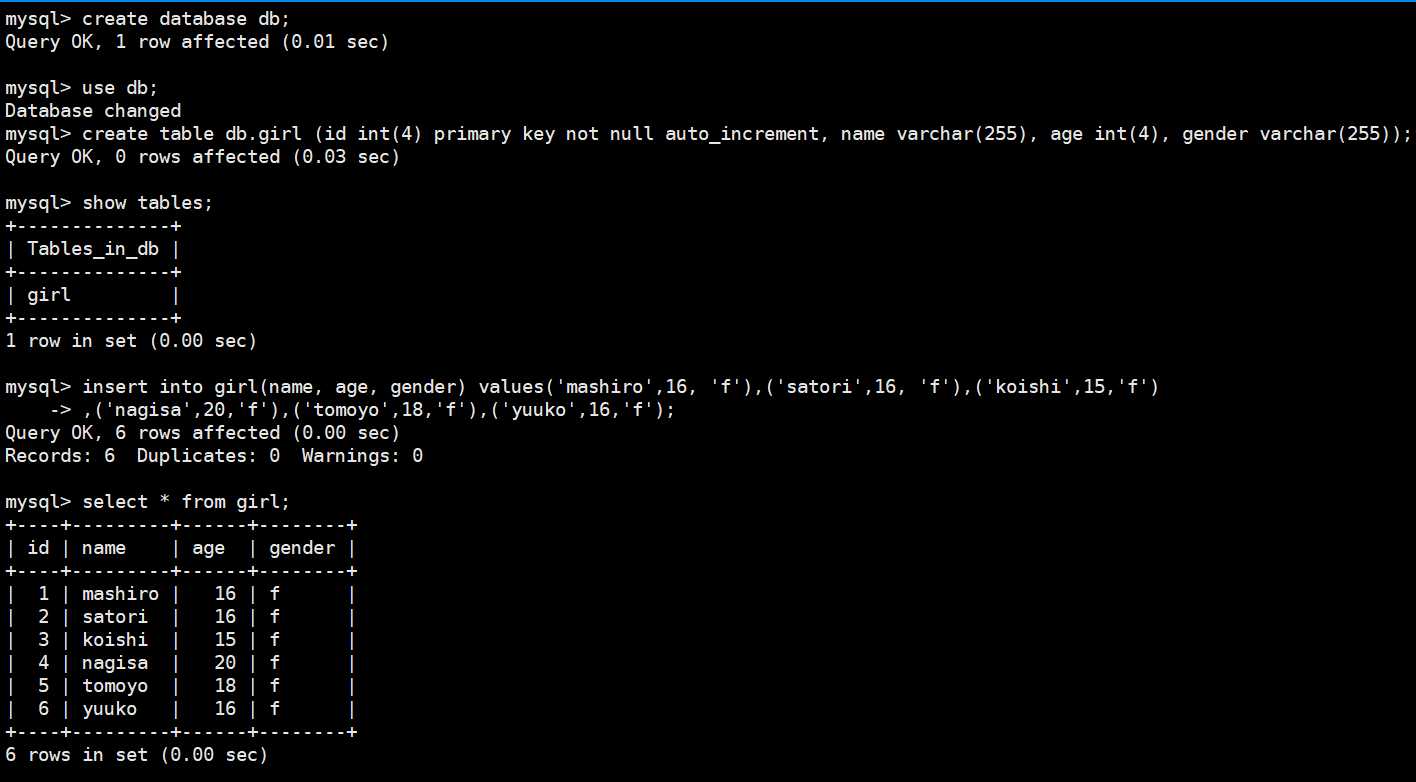
创建db数据库,在db数据库中创建一张girl表,然后写入了6条数据。
然后我们就可以导入数据了,注意:导入是专门指从数据库到hdfs,反过来的话叫做导出。导入有以下几种方式:
全部导入
在linux中如果命令比较长,但是你又想换行执行,那么只需要在结尾加一个即可
为什么要说这个,因为我们这里的命令就比较长
sqoop import --connect jdbc:mysql://localhost:3306/db --username root --password 密码 --table girl --target-dir /user/db --delete-target-dir --num-mappers 1 --fields-terminated-by " "
解释:
sqoop import,表示导入,如果是从hdfs到mysql呢?对叫导出,是export
--connect,还是jdbc驱动连接,不同的是这次我们指定了数据库
--username 用户名
--password 密码
--table 导mysql的哪张表
--target-dir 导入到hdfs那个目录下,没有会创建
--delete-target-dir 如果--target-dir指定的目录存在,则删除,生产上这个选项不要加,存不存在可以实现校验一下
--num-mappers mapper运行计算数量
--fields-terminated-by 分隔符下面我们就来试一下。
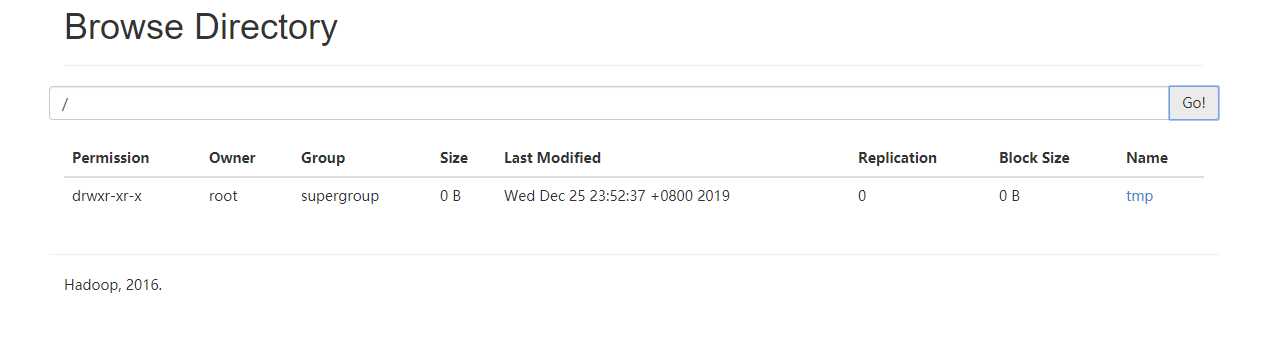
此时我的hdfs上面目前只有一个tmp目录,我们执行之后看看会不会多出一个/user目录
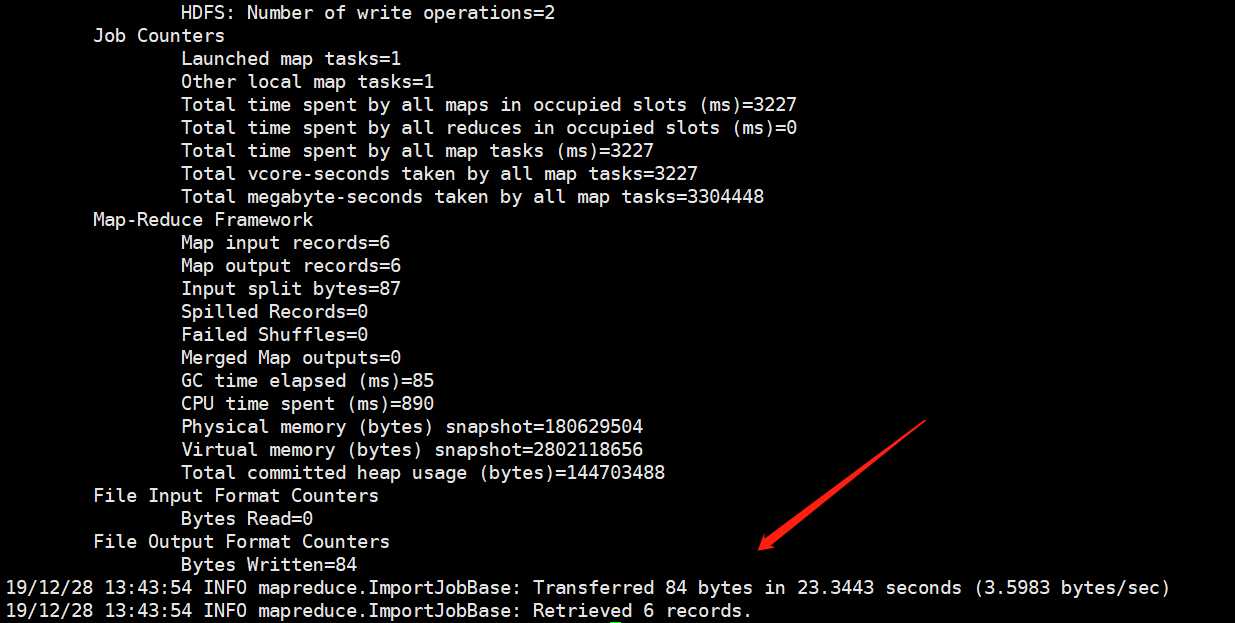
截取一部分,显然命令执行成功了。我们来看一下hdfs目录
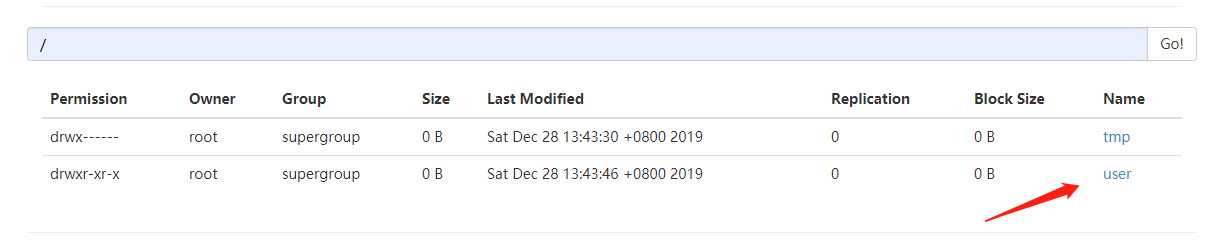
多了一个user目录,当然点进去还有个db目录,再进去就能看到文件了,还可以下载。
查询导入
我们上面的全部导入是把整张表都导入进去了,而显然查询导入是用来指定被导入的记录的。
sqoop import --connect jdbc:mysql://localhost:3306/db --username root --password 密码 --target-dir /user/db --delete-target-dir --num-mappers 1 --fields-terminated-by " " --query 'select id, name, age, gender from girl where id <=3 and $CONDITIONS'
我们发现可以最后面指定一个--query,也就是查询语句,要查询的指定记录插入到hdfs中
而且我们还看到--table已经没有了,因为--query中已经指定了
但是查询语句的where中有一个$CONDITIONS,这是干什么的
我们注意一下这个--num-mappers参数,如果记录比较多的话,我们会指定多个mappers
但是我们希望从mysql导入到hdfs中,顺序是保持一致的。所以sqoop要求是加上这个$CONDITIONS的,否则报错
导入成功
导入指定列
其实这个导入指定列,通过上面的查询导入是完全可以实现的,只不过sqoop也单独支持了另外的方式来导入列。
sqoop import --connect jdbc:mysql://localhost:3306/db --username root --password zgghyys123 --target-dir /user/db --delete-target-dir --num-mappers 1 --fields-terminated-by " " --columns id,name --table girl
如果指定了--xxx,那么顺序是无所谓的,但如果不指定,则必须按照指定的顺序,这个指定的顺序可以去sqoop官网去查
但是个人建议还是指定一下,这样不会因为顺序的问题而出错
另外指定列的时候,多个列之间使用逗号分割,并且逗号前后不能有空格
指定条件导入
sqoop import --connect jdbc:mysql://localhost:3306/db --username root --password 密码 --target-dir /user/db --delete-target-dir --num-mappers 1 --fields-terminated-by " " --columns id,name --table girl
--where "id=1"
只导入id=1的,我们发现条件可以单独写在--where里面,其实--query可以看做是--columns和--where的组合
但是一旦指定了--columns、--where就不可以再指定--query了,会报错的,因为冲突了从RBDMS到HIVE
sqoop import --connect jdbc:mysql://localhost:3306/db --username root --password 密码 --table girl --num-mappers 1 --fields-terminated-by " " --hive-import --hive-overwrite --hive-table hive_girl
解释
--hive-import 其实到hive里面分为两步,第一步还是导入到hdfs,然后迁移到hive
--hive-overwrite,覆盖
--hive-table 导入到hive的哪张表
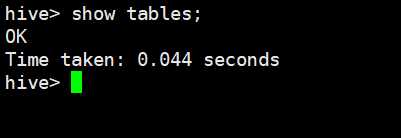
我们注意到:此时hive里面是没有任何表的。然后我们执行上面的命令,但是却报错了,我们定位一下
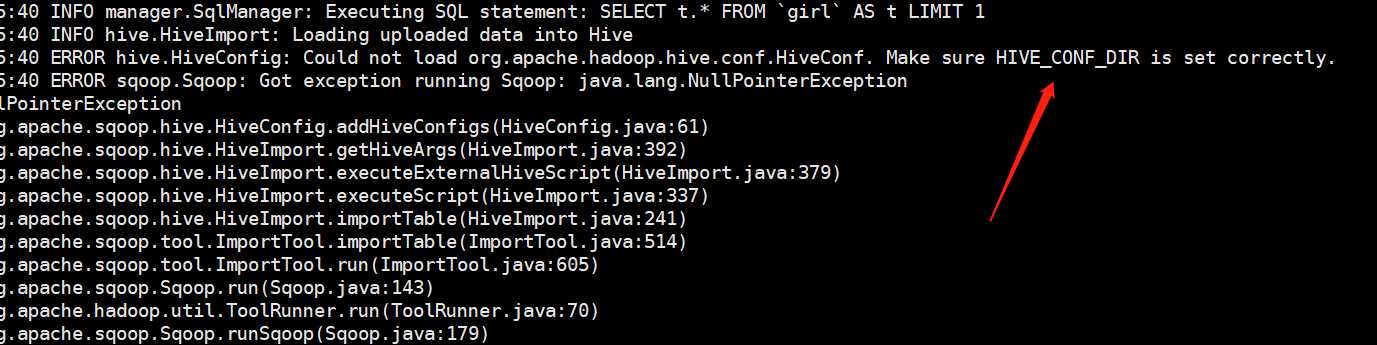
显示我们没有正确设置HIVE_CONF_DIR,显然这是不存在的。解决的办法是:将$HIVE_HOME/lib/hive-exec-**.jar拷贝到sqoop的lib目录里面去。

然后重新执行
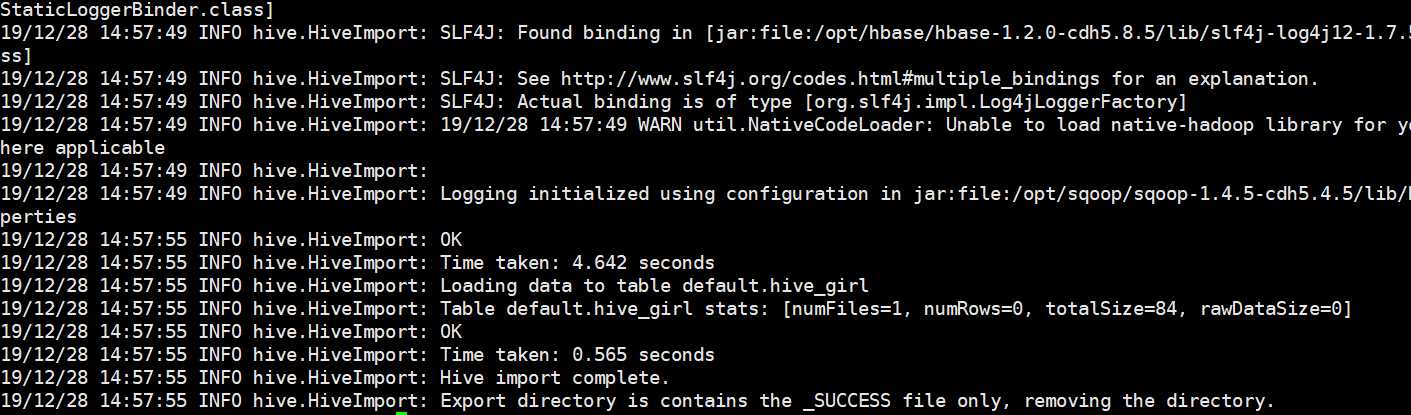
执行成功,而且显示的信息分为两步,一个是导入hdfs,然后是迁移到hive。下面看看表有没有被创建
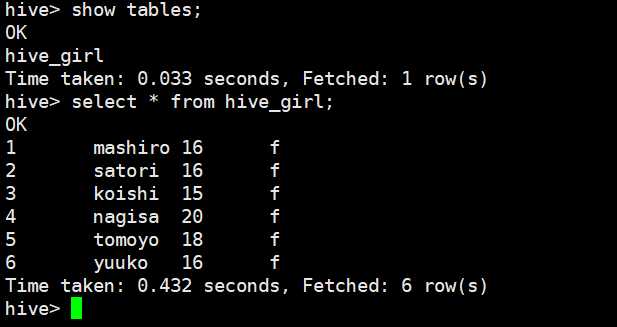
我们看到表已经被创建了,而且记录也是一样的
导出数据
导出数据,从hdfs/hive导入到RDBMS中,sqoop不支持直接从hbase导入到RDBMS,但是支持hdfs和hive,而且导出hdfs和导出hive没有什么区别
sqoop export --connect jdbc:mysql://localhost:3306/db --username root --password 密码 --table girl --num-mappers 1 --export-dir /user/hive/warehouse/hive_girl --input-fields-terminated-by " "
解释
export 导出
--table 原来是从哪张表导入,现在是导出到哪张表,这里是导出到girl这张表
--export-dir hdfs的路径,将那个文件导入到mysql
--input-fields-terminated-by 指定分隔符,原来的数据是什么分隔的,就指定什么
另外如果表不存在,则不会自动创建表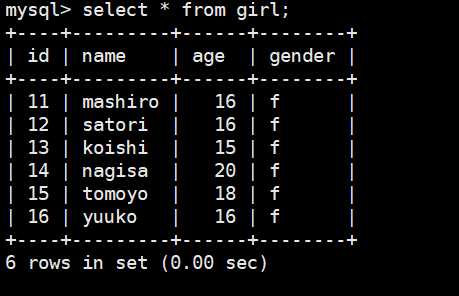
这里我依旧导出到girl这张表,但是hive里面的表,我们导入的时候把主键也导入了,所以再导出的时候,会报出主键重复,所以这里把girl表的主键修改一下,再导入看看记录会不会发生变化。
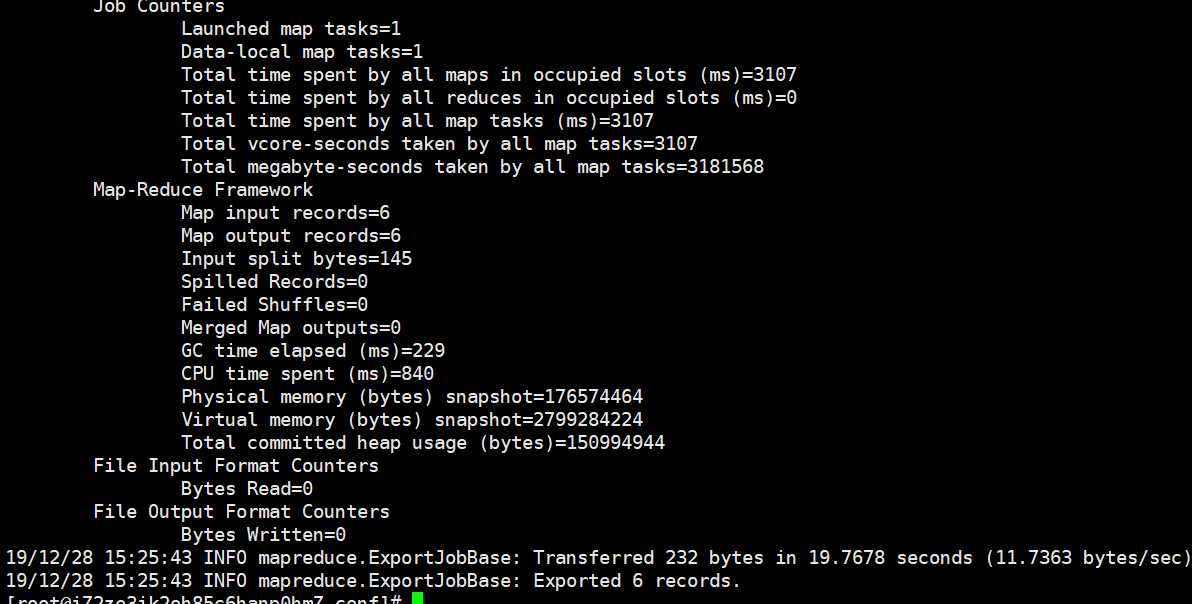
执行成功,我们来看看mysql中的数据有没有变化
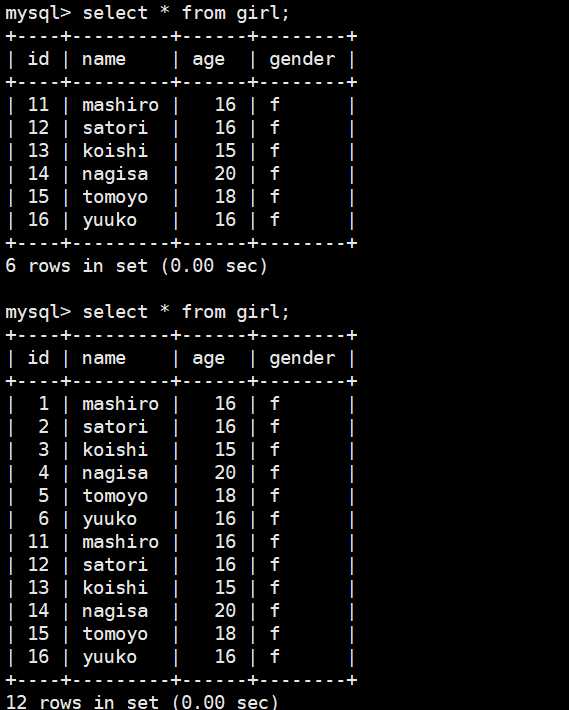
可以看到是导入成功了的。
以上是关于sqoop--数据库和hdfs之间的搬运工的主要内容,如果未能解决你的问题,请参考以下文章