Cassandra 组件
Posted yuxiaohao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Cassandra 组件相关的知识,希望对你有一定的参考价值。
关键结构
- node
- 您在哪里存储数据。它是基本的数据库基础结构组件。
- cluster
- 一组用于存储数据的分布式节点。集群可以具有单个节点,单个数据中心或多个数据中心。
- datacenter
- 在群集内为复制目的一起配置的一组相关节点。数据中心可以是物理数据中心或虚拟数据中心。使用单独的数据中心可防止事务受到其他工作负载的影响并降低延迟。根据复制因素,可以将数据写入多个数据中心。数据中心绝不能跨越物理位置。
- replication
- 在多个节点上存储数据副本的过程。复制可确保可靠性和容错能力。副本数由复制因子设置。
- commit log
- 首先将所有数据写入提交日志以确保持久性。将所有数据刷新到SSTables之后,可以将其存档,删除或回收。
- sstable
- 排序的字符串表(SSTable)是一个不变的数据文件,数据库会定期向其写入内存表。SSTable仅被追加,并顺序存储在磁盘上,并为每个数据库表维护。
- tombstone
- 行中指示一列的标记将被删除。压缩期间,标记的列将被删除。
- CQL Table
- 表行获取的有序列的集合。一个表由列组成,并具有一个主键。
配置Cassandra的关键组件
- Gossip
- 对等通信协议,用于发现和共享有关Cassandra集群中其他节点的位置和状态信息。每个节点在本地保留八卦信息,以便在节点重新启动时立即使用。
- 闲话是一种点对点通信协议,其中节点定期交换有关自己以及他们所知道的其他节点的状态信息。闲话过程每秒运行一次,并与集群中的其他三个节点交换状态消息。节点交换有关自己以及它们所闲聊的其他节点的信息,因此所有节点都可以快速了解集群中的所有其他节点。八卦消息具有版本,因此在八卦交换期间,较旧的信息将被特定节点的最新状态覆盖。
-
为防止八卦通信出现问题,请确保对群集中的所有节点使用相同的种子节点列表。在节点首次启动时,在所有最关键的节点上将种子设置为相同。默认情况下,一个节点会记住在后续重启之间闲聊的其他节点。指定种子节点没有其他目的,只是为加入群集的新节点引导八卦过程。种子节点不是单点故障,在节点操作之外,它们在群集操作中也没有任何其他特殊目的。
注意: 由于增加了维护并降低了八卦的性能,因此不建议将每个节点都设为种子节点。八卦优化并不严格,但建议使用较小的种子列表(每个数据中心大约三个节点)。故障检测是一种从闲聊状态和历史记录本地确定系统中节点何时关闭或已恢复的方法。该卡珊德拉数据库使用此信息,以避免路由客户端请求不可达的节点只要有可能。(数据库还可以通过动态侦听避免路由到性能不佳的节点。)
闲话过程直接跟踪其他节点的状态(直接向其闲聊的节点)和间接跟踪其他节点的状态(围绕二手,第三手进行通讯的节点等等)。数据库没有使用固定的阈值来标记故障节点,而是使用权责发生制检测机制来计算每个节点的阈值。该阈值考虑了网络性能,工作量和历史条件。在八卦交换期间,每个节点都会维护一个滑动窗口,该窗口在群集中来自其他节点的八卦消息到达时间之间。
要调整故障检测器的灵敏度,请配置phi_convict_threshold属性。较低的值会增加无响应的节点将被标记为关闭的可能性。在大多数情况下,请使用默认值,但对于Amazon EC2,应将其增加到10或12(由于经常遇到网络拥塞)。在不稳定的网络环境中(有时为EC2),将该值提高到10或12有助于防止错误故障。不建议使用高于12且低于5的值。
节点故障可能是由各种原因引起的,例如硬件故障和网络中断。节点中断通常是短暂的,但可能会持续很长时间。由于节点中断很少表示永久离开集群,因此不会自动导致节点从环网中永久删除。其他节点将定期尝试与失败的节点重新建立联系,以查看它们是否已备份。要永久更改集群中节点的成员资格,必须显式在集群中添加或删除节点。
当节点在中断后重新联机时,可能会丢失对其维护的副本数据的写入。存在修复机制来恢复丢失的数据,例如提示的切换和使用nodetool修复的手动修复。中断的时间长短决定了使用哪种修复机制来使数据一致。
- 分区器
- 分区程序将数据均匀分布在群集中的各个节点上,以实现负载平衡。
- 复制因子
- 复制是在多个节点上存储数据副本的过程。复制可确保可靠性和容错能力。副本数由复制因子设置。
- 复制品放置策略
- 复制策略确定要在其上放置副本的节点。数据的第一个副本就是第一个副本。它在任何意义上都不是唯一的。强烈建议将NetworkTopologyStrategy用于大多数部署,因为将来扩展需要时,可以轻松扩展到多个数据中心。
- snitch
- snitch从节点的IP地址映射到物理和虚拟位置,例如机架和数据中心。Snitches通知数据库有关网络拓扑的信息,以便有效地路由请求,并允许数据库通过将机器分组到数据中心和机架中来分发副本。
- cassandra.yaml配置文件
- 用于配置集群的初始化属性,表的缓存参数,调整和资源利用的属性,超时设置,客户端连接,备份和安全性的主要配置文件。默认情况下,将节点配置为将其管理的数据存储在cassandra.yaml文件中设置的目录中 。
- 系统键空间表属性
- 您可以以编程方式或使用客户端应用程序(例如CQL Shell(cqlsh))在每个键空间或每个表的基础上设置存储配置属性。
- 加载和卸载数据
- 使用DataStax批量加载程序工具可以有效地加载和卸载Cassandra数据。该工具将数据从另一个Cassandra或Apache Cassandra™集群迁移到Cassandra中。
- 从任何Cassandra 2.1或更高版本的数据源中卸载数据
- 将数据加载到Cassandra中
- 支持CSV和JSON格式
数据建模的基本概念
- 设计数据模型
- 数据模型的设计基于您要执行的查询,而不是像对关系数据库那样对实体和关系建模。
- 键空间
- 最外部的数据分组,类似于关系数据库中的架构。所有表都属于一个键空间。键空间是复制的定义容器。
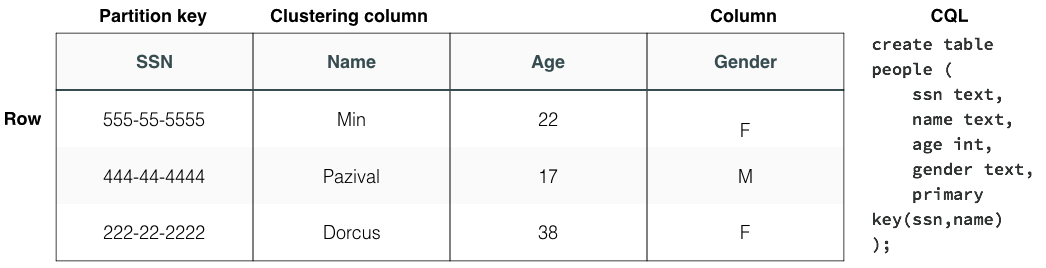
- 表
- 一个表基于主键存储数据,该主键由分区键和可选的群集列组成。还可为高基数数据添加实例化视图。
- 分区键定义了存储数据的节点,并将数据分为逻辑组。定义分区键,以均匀分布数据并满足特定查询。如果可能,应避免跨多个分区的查询和写入请求。
- 群集列定义分区中行的排序顺序。定义聚类列时,请考虑数据的用途。例如,以降序检索按日期排序的最新事务。
- 物化视图是从具有新主键和新属性的另一个表的数据构建的表。通过主键定义优化查询。物化视图中的数据通过更改源表自动更新。
注意:在Apache Cassandra™的早期版本中,列族在很多方面是表的同义词。 - 表
以上是关于Cassandra 组件的主要内容,如果未能解决你的问题,请参考以下文章