knn识别简单验证码
Posted kanadeblisst
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了knn识别简单验证码相关的知识,希望对你有一定的参考价值。
参考
https://www.biaodianfu.com/knn-captcha-recognition.html
内容大致一样,只是根据自己的想法加入了一些改动
KNN(k近邻算法)
算法原理请看:https://www.biaodianfu.com/knn.html
我来说一下sklearn中knn的属性和方法
sklearn.neighbors.KNeighborsClassifier(n_neighbors = 5,weights =‘uniform‘,algorithm =‘auto‘,leaf_size = 30,
p = 2,metric =‘minkowski‘,metric_params = None,n_jobs = None)
- n_neighbors: 即knn中的K值
- weights: 样本的权重数组
- algorithm: 使用的算法,有{‘auto‘,‘ball_tree‘,‘kd_tree‘,‘brute‘}
- leaf_size:当使用‘ball_tree‘和‘kd_tree‘时的属性(不懂,先不管他)
- p:距离选择,p=2时为欧式距离,默认为2
- metric:距离度量方式,和参数p有什么关系和区别暂时没懂
- metric_params :距离额外参数,如{‘w‘:weights, ‘p‘:2}
- n_jobs:使用的CPU数,默认-1即全部使用
在这些参数中,识别数字验证码只需要关注n_neighbors这个就行了,其他都保持默认就行。
方法
- fit(x, y): 使用样本x和标签y作训练,其实knn的训练只是保存了数据
- get_params(deep=True): 获取模型的所有参数,deep不知道有什么用
- kneighbors(test_x=None, n_neighbors=None, return_distance=True): 返回训练样本离样本test_x最近的n_neighbors个样本的值和距离, return_distance为是否返回距离
- kneighbors_graph(x=None, n_neighbors=None, mode=‘connectivity‘ ): 返回x中k个临近点对应的权重或者距离,根据mode选择‘connectivity‘或者‘distance‘
- predict(test_x): 根据样本test_x,返回预测y
- predict_proba(test_x): 返回样本test_x属于每个类别的概率,也就是说返回的是维度为(样本数, k)的二维数组,每行一维数组的所有元素和为1,数组长度为k。
- score(test_x, y, sample_weight =None): 根据样本test_x预测test_y, 然后对比实际的y返回的正确分数,sample_weight为权重
- set_params(**args): 重新设置模型参数
当然knn分类器还有RadiusNeighborsClassifier,区别在于,KNeighborsClassifier找距离最近的K个样本,然后投票来决定x的类别,而RadiusNeighborsClassifier则是根据x半径为r的范围内的所有样本投票来决定x的类别。
数据预处理
如果对图片中的数组表示不清楚的可以看另一篇博客
下载验证码
https://download.csdn.net/index.php/rest/tools/validcode/source_ip_validate/10.5711163911089325
这个有个地方需要注意,你直接请求这个接口的话得到的只是个html的源码,但是你在浏览器上看的时候又是验证码,F12看的时候也是返回的验证码。但是我用抓包工具抓包发现它实际上发送了两次请求,第一次请求更新cookie,第二次才是真正的返回验证码,链接一样只是cookie不一样。我们只需要保存第二个请求的cookie用requests请求即可。
已经下载的:https://www.lanzous.com/i8enhah
基本操作
im = Image.open(img)
im_gray = im.convert('L') # 灰度图
pix = np.array(im_gray)
# 二值化
threshold = 180 #阈值
pix = (pix < threshold) * 255
# 去边框
new_pix = pix[1:-1,1:-1]最开始的图片:
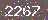
处理后的图片
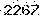
去噪点
做完基本操作之后你会发现,图片会有一些多余的点,这些点可能会影响分类所以需要去除。我使用最简单的方法,只去除孤立点。判断一个黑点九宫格内的黑点的个数,如果少于某个值则将这个黑点置为白点(实际测试这个值只能为2,大于2会删除正常的点)。代码如下:
for i in range(18):
for j in range(46):
k = 0
if new_pix[i, j] == 0:
k = np.sum(new_pix[i-1:i+2, j-1:j+2] == 0)
if k < 2:
new_pix[i, j] = 255去完噪点的图片:
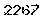
切割字符
开始我想以投影法切割,然后发现其实这个的思想就是将图片进行横向压缩,如果哪一列都是白点,则认为这一列就是分割边界。代码如下:
L = []
# 查找分割边界
for i in range(46):
k = np.sum(new_pix[:,i]==0)
if k == 0:
L.append(i)
# 分割图片
for i in range(1, len(L)):
k = L[i] - L[i-1]
if k > 2:
print(k)
split_pix = new_pix[:,L[i-1]:L[i]+1]
print(split_pix.shape)
# 7是根据实际的值判断的,大部分为9,所以需要统一大小
if k == 7:
tmp = np.zeros((18, 10))
tmp += 255
tmp[:,1:-1] = split_pix
out = Image.fromarray(tmp).convert('L')
out.save(f'1/{uuid.uuid4()}.jpg')
if split_pix.shape != (18,10):
continue
out = Image.fromarray(split_pix).convert('L')
out.save(f'1/{uuid.uuid4()}.jpg')但是当我将这个方法应用于所有图片时,会出现少部分连在一起的字符。最后我直接选择了指定区间来切割字符,数值为实际测试得到,代码如下:
img1 = new_pix[:, 3:13]
out = Image.fromarray(img1).convert('L')
out.save('1.jpg')
img2 = new_pix[:, 12:22]
out = Image.fromarray(img2).convert('L')
out.save('2.jpg')
img3 = new_pix[:, 21:31]
out = Image.fromarray(img3).convert('L')
out.save('3.jpg')
img4 = new_pix[:, 30:40]
out = Image.fromarray(img4).convert('L')
out.save('4.jpg')人工标注
这是最烦的一部分了,很浪费时间。我每个字符标注了120张图片,花了一个小时。所以这种快乐我怎么能一个人独享呢。
生成模型
from sklearn import neighbors
import os
from PIL import Image
import numpy as np
import shutil
x = []
y = []
for label in os.listdir('train'):
for file in os.listdir(f'train/{label}'):
im = Image.open(f'train/{label}/{file}')
pix = np.array(im)
pix = (pix > 180) * 1
pix = pix.ravel()
x.append(list(pix))
y.append(int(label))
train_x = np.array(x)
train_y = np.array(y)
model = neighbors.KNeighborsClassifier(n_neighbors=10)
model.fit(train_x, train_y)
x = []
y = []
for label in os.listdir('test'):
for file in os.listdir(f'test/{label}'):
im = Image.open(f'test/{label}/{file}')
pix = np.array(im)
pix = (pix > 180) * 1
pix = pix.ravel()
x.append(list(pix))
y.append(int(label))
predict_y = model.predict(np.array(x))
print(predict_y == np.array(y))这里我使用了所有的像素值作为图片的特征,总共18x10=180个特征值。根据开头的那个博客所说的,我们可以取每行上黑色像素的个数,可以得到10个特征,每列上黑色像素的个数,可以得到6个特征。这样就只有16个特征。在计算时间上会得到一定的改善。不过因为图片较小,数量也不多,实际测试所花的时间差也就几秒差异。而180个特征训练出来的基本100%正确率,16个特征则会出现个别判断出错的情况不过正确率也有98%以上了。当然在实际应用中肯定选择16个特征,这点错误率是可以接受的。以下是16个特征的代码:
from sklearn import neighbors
import os
from PIL import Image
import numpy as np
x = []
y = []
for label in os.listdir('train'):
for file in os.listdir(f'train/{label}'):
x_ = []
im = Image.open(f'train/{label}/{file}')
pix = np.array(im)
pix = (pix > 180) * 1
for i in range(18):
x_.append(np.sum(pix[i] == 0))
for j in range(10):
x_.append(np.sum(pix[:,j] == 0))
x.append(x_)
y.append(int(label))
train_x = np.array(x)
train_y = np.array(y)
model = neighbors.KNeighborsClassifier(n_neighbors=10)
model.fit(train_x, train_y)
test_x = []
test_y = []
for label in os.listdir('test'):
for file in os.listdir(f'test/{label}'):
x_ = []
im = Image.open(f'test/{label}/{file}')
pix = np.array(im)
pix = (pix > 180) * 1
for i in range(18):
x_.append(np.sum(pix[i] == 0))
for j in range(10):
x_.append(np.sum(pix[:,j] == 0))
test_x.append(x_)
test_y.append(int(label))
predict_y = model.predict(x)
print(predict_y == test_y)思考
我一开始每个字符标注了120个样本,那么如果减少样本数,会不会影响正确率,减少到多少才不会影响?
我们看一下随着样本数的增大,score的变化(左边数字表示每个字符的样本数,右边表示正确率):
1 0.07086614173228346
2 0.4015748031496063
3 0.6850393700787402
4 0.8031496062992126
5 0.8582677165354331
6 1.0
7 1.0
8 1.0
9 1.0
什么?也就是说只要每个类别6个样本就可以保证100%的正确率,那我这一个小时不是白花了。。。
我们在看一下KNN的k对正确率的影响:
1 1.0
2 1.0
3 1.0
4 1.0
5 1.0
6 1.0
7 1.0
8 1.0
9 1.0
额,好像k选什么一点都不重要。这是因为样本类别太少,特征很明显导致的。当然这种验证码的识别只是练习,而KNN也仅仅能用于简单的验证码,真正复杂的验证码还是需要CNN来识别。
这是已标注的数据:https://www.lanzous.com/i8epywd
最后,我正在学习一些机器学习的算法,对于一些我需要记录的内容我都会分享到博客和微信公众号(python成长路),欢迎关注。平时的话一般分享一些爬虫或者Python的内容。

以上是关于knn识别简单验证码的主要内容,如果未能解决你的问题,请参考以下文章