说话人分类(Speaker Diarisation)
Posted ytxwzqin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了说话人分类(Speaker Diarisation)相关的知识,希望对你有一定的参考价值。
简称SD,顾名思义,在采集的语音信号流中,分辨出不同说话人的说话时长并标注。参照2010年8月的文献[1]中的一张图:
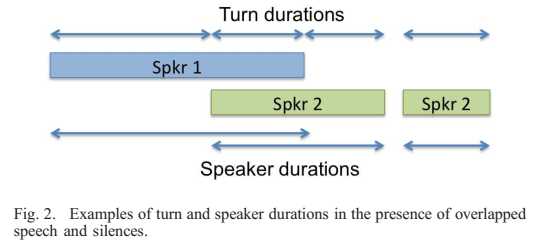
又称说话人分割,在语音信号处理的多种场景下均有应用需求,近年来也被多来越多的研究者所关注。SD的方法分为以下两种:1)无监督方法,比如谱聚类以及k均值等;2)监督方法,深度神经网络,比如RNN等方法。
基于聚类的无监督方法
基于RNN的监督方法
UIS-RNN[2]
这是谷歌2019年发表的一篇文章,研究了实时处理的说话人分类,不限制说话人数目,为每一个说话人建立了一个RNN模型,并且持续更新。文中表示实时说话人分割的准确率可以达到92%,并且DER降低至7.6%,超过了其先前基于聚类方法(8.8%)和深度网络嵌入方法(9.9%)。
文章主要提出了无界间隔状态(.Unbounded interleaved-state )RNN,一个可以通过监督学习训练的对于时变数据分割和聚类的算法。
首先看一张图,这是文中的SD results show:
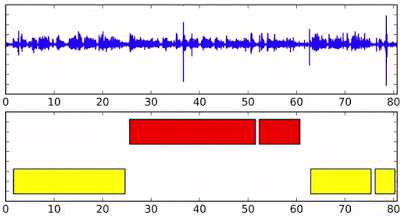
不同颜色表示不同的说话人,横轴为时间索引。
这一方法与通常聚类方法的主要区别在于研究人员使用了参数共享的循环神经网络为所有的说话人(embeddings)建模,并通过循环神经网络的不同状态来识别说话人,这就能将不同的语音片段与不同的人对应起来。
具体来看,每一个人的语音都可以看做权值共享的RNN的一个实例,由于生成的实例不受限所以可以适应多个说话人的场景。将RNN在不同输入下的状态对应到不同的说话人即可实现通过监督学习来实现语音片段的归并。通过完整的监督模型,可以得到语音中说话人的数量,并可以通过RNN携带时变的信息,这将会对在线系统的性能带来质的提升。
系统的baseline结构为:
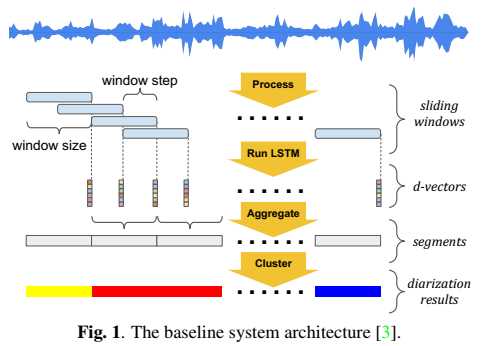
UIS-RNN是一个整句(X,Y)的在线生成处理过程,提出的算法结构为:
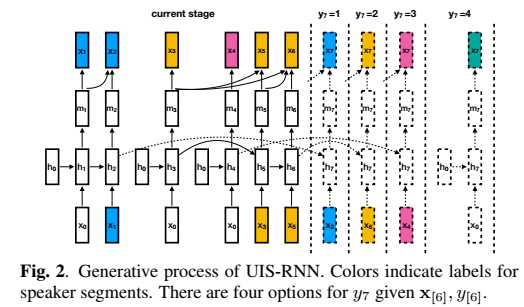
解码过程中采用最大后验概率准则解码,采用beam search方法处理。
在未来研究人员将会改进这一模型用于离线解码上下文信息的整合;同时还希望直接利用声学特征代替d-vectors作为音频特征,这样就能实现完整的端到端模型了。
参考
[1] Speaker Diarization: A Review of Recent Research
[2] Fully Supervised Speaker Diarization, 2019 ICASSP accepted.
以上是关于说话人分类(Speaker Diarisation)的主要内容,如果未能解决你的问题,请参考以下文章
Microsoft Speaker Recognition API
Unsupervised Domain Adaptation Via Domain Adversarial Training For Speaker Recognition
论文翻译:Generalized end-to-end loss for speaker verification
Utterance-Wise Recurrent Dropout And Iterative Speaker Adaptation For Robust Monaural Speech Recogni