联邦学习隐私保护相关知识总结
Posted learning-striving
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了联邦学习隐私保护相关知识总结相关的知识,希望对你有一定的参考价值。
数据孤岛问题
数据孤岛问题:大数据、人工智能和云产业的发展为传统行业的升级变革带来了新机遇,同时也给数据和网络安全带来了新挑战,由于行业间的竞争和垄断,以及同一企业下不同系统和业务的闭塞性与阻隔性,行业与企业间很难实现数据信息的交流与整合。当不同企业甚至同一企业的不同部门之间需要合作进行联合建模时,将面临跨越重重数据壁垒的考验
早期的分布式计算及联邦学习的产生
早期的分布式计算:试图通过整合不同来源的数据进行分布式的建模,从而解决数据孤岛问题
- 优点:将具有庞大计算量的任务部署到多台机器上,提升了计算效率,减少了任务耗能
- 缺点:随着数据量及复杂度的增加,分布式系统架构通常会产生巨大的沟通成本,影响数据的传输和处理效率,同时大规模的数据传输不可避免地会涉及隐私泄露问题
解决方案:联邦学习(FL),该技术在数据不共享的情况下完成联合建模构建共享模型
具体来讲,各个数据持有方(个人/企业/机构)的自有数据不出本地,通过联邦系统中加密机制下的模型参数交换方式(即在不违反数据隐私法规的情况下),联合建立一个全局的共享模型,建好的模型为所有参与方共享使用
联邦学习与分布式学习的差异体现:对隐私保护的要求
分布式计算为人工智能和大数据的结合提供了算力基础,保证了大规模的数据能够被有效地使用和学习;联邦学习保证各参与方在不共享数据的前提下,进行隐私保护下的联邦建模
联邦学习分类(应用场景角度)
- 面向企业(to business,ToB):参与方之间通过新增一个信任第三方作为中心服务器,协作各参与方完成联邦学习的过程,同时可以保证中间传输内容的可审计性
- 建模对象:机构、公司和政府等
- 中心服务器的作用:控制参数交换、中间计算以及训练流程
- 面向客户(to customer,ToC):适用于参与方数量较多、算力较低的场景
- 建模对象:主要以边缘端计算设备为主
联邦学习架构
客户端-服务器架构
客户端-服务器架构:参与训练的参与方数据具有类似的数据结构(特征空间),但是每个参与方拥有的用户是不相同的
每个参与方看作一个客户端,然后引入一个大家信任的服务器来帮助完成联邦学习的联合建模需求,联合训练的过程中,被训练的数据将会被保存在每一个客户端本地,同时,所有的客户端可以一起参与训练一个共享的全局模型,最终所有的客户端可以一起享用联合训练完成的全局模型。
云服务器作为中心的服务器进行联合训练模型参数的聚合,每一个参与方作为客户端通过与服务器之间进行参数传递来参与联合训练
训练过程:
步骤1:中心服务器初始化联合训练模型,并且将初始参数传递给每一个客户端。
步骤2:客户端用本地数据和收到的初始化模型参数进行模型训练。具体步骤包括:计算训练梯度,使用加密、差异隐私等加密技术掩饰所选梯度,并将加密后的结果发送到服务器。
步骤3:服务器执行安全聚合。服务器只收到加密的模型参数,不会了解任何客户端的数据信息,实现隐私保护。服务器将安全聚合后的结果发送给客户端。
步骤4:参与方用解密的梯度信息更新各自的本地模型,具体方法重复步骤2
端对端架构(对等网络架构)
端对端架构(对等网络架构):参与训练的参与方有很多重叠的用户,但是关于用户的数据结构是不相同的
参与方可以通过广播将自己的训练参数传递给其他所有的参与方,或者通过循环传递链往下一个参与方传递参数
训练过程:
步骤1:参与方使用本地数据和初始化模型参数进行模型训练。
步骤2:参与方加密传递参数。具体步骤包括:计算训练梯度,使用加密、多方安全计算等方法将加密后的参数结果广播给其他所有的参与方。如果是链式传递模型,就只将模型参数传递给链式下端的参与方。
步骤3:参与方收到其他所有的加密模型参数之后进行安全聚合。
步骤4:解密并继续进行模型训练,更新本地模型。如果是链式传递模型,则接收到链式上端的参与方模型参数数据后进行安全聚合,解密后继续进行模型训练。重复步骤2
FL安全性风险
联邦学习没有对参与方进行检测和校验,例如,没有审核参与方提供的参数模型是否真实。因此,恶意的参与方有可能通过提供虚假的模型参数来攻击和破坏联邦学习训练过程。这些虚假参数未经过校验就与正常的参数进行聚合,将会影响整体模型的最终质量,甚至会导致整个联邦学习过程无法收敛成一个可用的模型,进而导致训练失败
联邦学习需要考虑是否对训练过程中的参数传递和存储进行隐私保护,研究表明,恶意的参与方可以依据联邦学习梯度参数在每一轮中的差异,反向推测出用户的敏感数据。因此,不通过加密保护的参数被泄露,在一定的程度上是可以成为攻击目标,从而间接泄露用户隐私数据的
隐私保护技术
降噪隐私保护主要是通过差分隐私等方法实现的
原理:给数据添加噪声,或使用归纳方法隐藏参与方的某些敏感属性,直到第三方无法通过差分攻击来区分个人为止,使数据无法还原,从而达到保护用户隐私的目的
缺点:会带来模型准确性上的损失,因此通常需要在参与方隐私与模型准确性之间进行权衡
加密隐私保护主要是通过安全多方计算、同态加密等方法来实现的,通常需要设计复杂的加密计算协议来隐藏真实的输入和输出
安全多方计算:成本较高,为降低数据传输成本,参与方可能需要降低对数据安全的要求来提高训练的效率
同态加密:能够对所有数据进行加密处理,参与方接收到的是密文,攻击者无法推理出原始数据信息,从而保障数据层面的安全
优点:参与方和服务器之间传递的都是加密以后的参数信息,从而保证了这些加密过的参数信息即使被攻击,也不会泄露模型和用户隐私
缺点:在计算量和模型效率上有更高的要求,因此这种加密类型的隐私保护通常需要在参与方计算效率和模型安全性之间进行权衡
联邦学习攻击类型
FL隐私保护问题
在联邦学习训练的参数通信更新的过程中,有可能会泄露一些敏感的信息。这些模型迭代过程中深层次的信息泄露可能由第三方攻击者造成,也可能通过中央服务器泄露
FL攻击问题
| 角度 | 分类 |
| 参与方类型 | 半诚实但好奇的攻击方 |
| 恶意攻击方 | |
| 攻击方向 | 内部发起 |
| 外部发起 | |
| 攻击者的角色 | 参与方发起的攻击 |
| 中心服务器发起的攻击 | |
| 第三方发起的攻击 | |
| 发动攻击的方式 | 中毒攻击 |
| 拜占庭攻击 | |
| 攻击发起的阶段 | 模型训练过程的攻击 |
| 模型推断过程的攻击 |
FL威胁模型类型
半诚实但好奇的攻击方假设(被动攻击方假设):被动攻击方会在遵守联邦学习的密码安全协议的基础上,试图从协议执行过程中产生的中间结果推断或者提取出其他参与方的隐私数据
恶意攻击方(主动攻击方):不会遵守任何协议,为了达到获取隐私数据的目的,可以采取任何攻击手段,例如破坏协议的公平性、阻止协议的正常执行、拒绝参与协议、不按照协议恶意替换自己的输入、提前终止协议等方式,这些都会严重影响整个联邦学习协议的设计以及训练的完成情况
恶意参与方
- 恶意客户端:可以获取联邦建模过程中所有参与方通信传输的模型参数,进行任意修改攻击
- 恶意服务器:可以检测每次从客户端发送过来的更新模型参数,不按照协议,随意修改训练过程,从而发动攻击
- 恶意分析师或恶意模型工程师:可以访问联邦学习系统的输入和输出,并且进行各种恶意攻击
FL攻击类型分类
- 内部攻击:服务器或参与方发起
- 外部攻击:通过参与方与服务器之间的通信通道发起
内部攻击
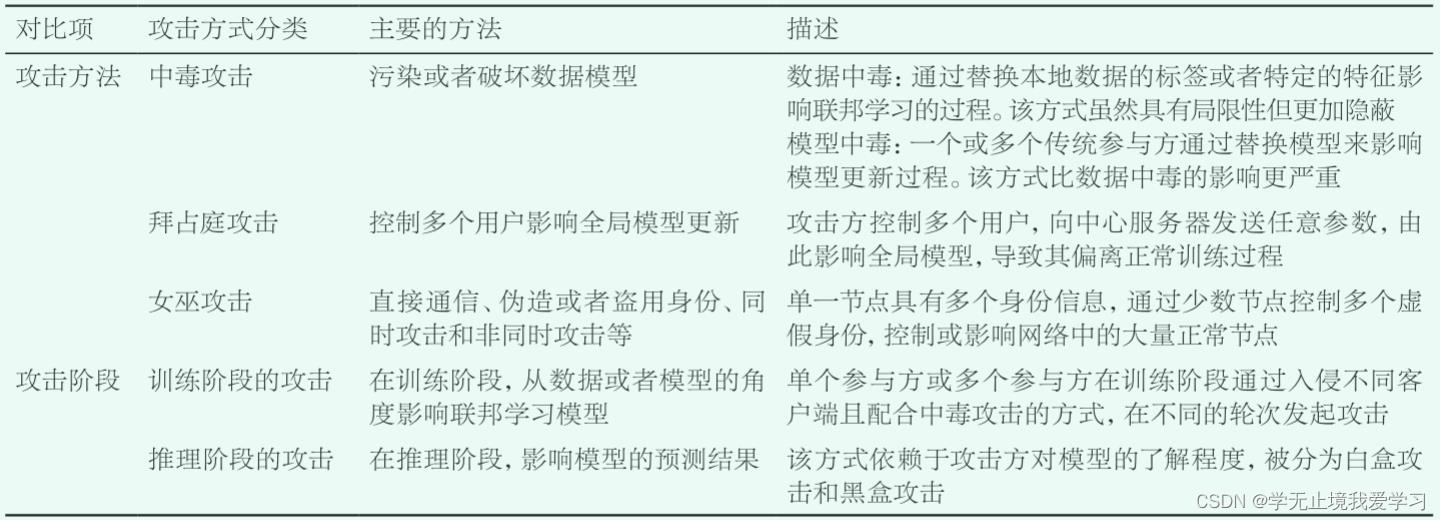
1.中毒攻击:可以细分为模型中毒攻击和数据中毒攻击,以中毒的方式污染或者破坏模型的数据或者模型,从而达到攻击目的
数据中毒:攻击方不能直接攻击发送给服务器的信息,而是通过替换本地数据的标签或特定的特征来操作客户端数据,从而发起攻击
模型中毒:通过加入后门的方式进行模型中毒攻击来攻击联邦学习系统。联邦学习的任何参与方都可以在联邦全局模型中引入隐藏的后门功能
2.拜占庭攻击:拜占庭恶意参与方会随机或者故意改变自己的输出,致使模型无法正常收敛,同时每次迭代可以输出类似的梯度更新结果,并且使得自己更难被发现
拜占庭用户:拜占庭攻击主要考虑的是多用户的情况,拜占庭用户指攻击方控制的多个用户,拜占庭用户可以给中心服务器发送任意参数,而不是发送本地更新后的模型参数
后果:导致全局模型在局部最优处收敛,甚至导致模型发散
3.女巫攻击:指网络中的单一节点可能具有多个身份标识,并且通过其控制系统的大部分节点来削弱网络冗余备份的作用,攻击方伪装为参与方攻击联邦学习模型,导致模型效果显著降低
攻击方式
- 直接通信
- 伪造或者盗用身份
- 同时攻击
- 非同时攻击
FL攻击的阶段分类
训练阶段的攻击:攻击方可以通过数据中毒攻击的方式改变训练数据集合收集的完整性,或者通过模型中毒攻击改变学习过程的完整性。攻击方可以攻击一个或所有参与方的参数更新过程
推理阶段的攻击:推理攻击也被称作探索攻击(入侵攻击)。通常情况下,推理攻击不会破坏目标
模型,而是影响模型,从而使其输出错误的结果(或者攻击方希望的结果)
成功率或有效性:很大的程度上依赖于攻击方对整个模型的了解程度
- 白盒攻击:攻击者知道目标模型使用的算法与参数,借助优化问题计算所需干扰,攻击者在对抗数据生成的时候能够与目标模型交互,可以完全使用联邦学习模型
- 黑盒攻击:只能查询联邦学习模型,攻击者不知道目标模型所使用的算法与参数,只能通过为模型提供输入跟模型互动的时候,观察判断其输出,细微的数据修改也能为攻击者提供一种攻击手段
联邦学习的加密通信
加密隐私保护机制
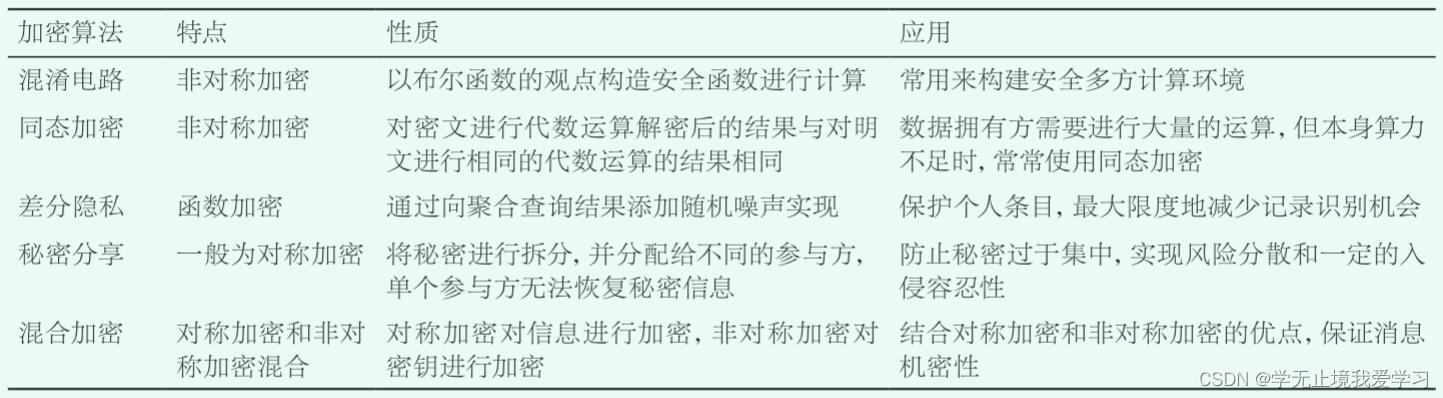
- 混淆电路:用来解决百万富翁问题,即两个富翁如何在不暴露自己具体金额的情况下比较谁更富有
- 同态加密:是一类基于同态原理的特殊的加密函数,其关注的是数据处理安全,其允许直接对已加密的数据进行处理,而不需要知道任何关于解密函数的信息,可以直接对密文进行运算的加密方式,运算的结果与直接在明文上做运算的结果相同
- 差分隐私:允许某个参与方共享数据集,并确保共享的形式只会暴露想要共享的那部分信息,保护的是数据源中一点微小的改动,解决例如插入或者删除一条记录导致的计算结果差异进而产生的隐私泄露问题.采用特定的随机算法对数据添加适量噪声,将数据模糊化,降低敏感数据信息泄露的风险,不会被数据量约束,这样即使攻击者得到交互的数据也不能对原始数据进行有效推理
- 秘密分享:指将原本要传递的数据划分为多个部分,然后将它们依次发送到每个参与方。而仅通过一个或少部分参与方无法还原出原始数据,只有较大部分或者所有参与方将各自的数据凑在一起时,才能还原出原始数据
- 混合加密:将以上技术进行结合,即使用混合技术进行加密
加密计算环境
- 安全多方计算:针对一组互不信任的参与方之间的协同计算问题提出隐私保护方案,主要针对的是在无可信第三方的情况下,如何安全地计算一个约定函数的问题,同时要求每个参与主体除了计算结果,不能得到其他实体的任何输入信息,在整个计算协议执行过程中用户对个人数据始终拥有控制权,只有计算逻辑是公开的
- 可信计算环境:可信计算(TC)是可信计算组织(TCG)推出的一项研究,希望通过专用的安全芯片(TPM/TCM)增强各种计算平台的安全性,相较于可信计算,TEE有利于便携设备的使用,该环境中的安全性可以被验证,可以将联邦学习过程中的一部分放到可信计算环境中,可信计算环境对联邦学习系统起到了很好的数据保护作用,为隐私等敏感数据提供了远程安全计算的保障
参考文献:[1]王健宗,孔令炜,黄章成,陈霖捷,刘懿,卢春曦,肖京.联邦学习隐私保护研究进展[J].大数据,2021,7(03):130-149.
推荐工具:http://xqnav.top/
以上是关于联邦学习隐私保护相关知识总结的主要内容,如果未能解决你的问题,请参考以下文章