多线程控制讲解与代码实现
Posted 阿尔帕兹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多线程控制讲解与代码实现相关的知识,希望对你有一定的参考价值。
多线程控制
回顾一下线程的概念
线程是CPU调度的基本单位,进程是承担分配系统资源的基本单位。linux在设计上并没有给线程专门设计数据结构,而是直接复用PCB的数据结构。每个新线程(task_struct中有个指针都指向虚拟内存mm_struct结构,实现了共享同一份代码,拥有该进程的一部分资源)
在linux中,把所有执行流都看作是轻量级进程,故有一个用户级的原生线程库为用户提供“线程”接口(对OS是轻量级线程)。
从信号、异常和资源看线程的健壮性问题
一个线程出现异常,会影响其他线程
#include <iostream>
#include <string>
#include <pthread.h>
#include <unistd.h>
using namespace std;
void* start_routime(void* args)
string name = static_cast<const char*>(args);//安全地进行强制类型转换
// 如果是一个执行流,那么不可能同时执行2个死循环
int count = 0;
while(1)
cout << "new thread is created! name: " << name << endl;
sleep(1);
count++;
if(count == 5)
int* p = nullptr;
*p = 10;//故意写一个解引用空指针,我们知道是会报段错误
int main()
pthread_t thread;
pthread_create(&thread, nullptr, start_routime, (void*)"thread new");
while(1)
cout << "new thread is created! name: main" << endl;
sleep(1);
return 0;
命令行报错
[yyq@VM-8-13-centos 2023_03_18_multiThread]$ ./mythread
new thread is created! name: main
new thread is created! name: thread new
new thread is created! name: main
new thread is created! name: thread new
new thread is created! name: main
new thread is created! name: thread new
new thread is created! name: main
new thread is created! name: thread new
new thread is created! name: main
new thread is created! name: thread new
new thread is created! name: main
Segmentation fault
由此可以看出,当一个线程出异常了,会直接影响其他线程的正常运行。因为信号是整体发送给进程的,本质是将信号发给对应进程的pid,而一个进程的所有线程pid值是相同的,就会给每个线程的PCB里写入相同的信号,接收到信号后,所有的进程就退了。
换个角度来说,每个线程所依赖的资源是进程给的,当一个线程出异常,进程会收到退出信号后,OS回收资源是回收整个进程的资源,而其他线程的资源是进程给的,故所有的线程就会全部退出。
以上是从信号+异常+资源的视角来看待线程健壮性的问题。
POSIX线程库的errno
我们学习的是POSIX线程库,有以下特征
1、与线程有关的函数构成了一个完整的系列,绝大多数函数的名字都是pthread_打头的;
2、要使用这些函数库,要通过引入头文<pthread.h>;
3、链接这些线程函数库时要使用编译器命令的-l pthread选项。
用户级线程库的pthread这一类函数出错时不会设置全局变量errno(虽然大部分其他POSIX函数会这样做),而是将错误代码通过返回值返回。因为线程是共享一份资源的,如果多个线程对同一个全局变量进行访问(errno也是全局变量),就会因为缺乏访问控制而带来一些问题,因此对于pthreads函数的错误,建议通过返回值来判定。
简单了解clone
允许用户创建一个进程/轻量级进程,fork()/vfork()就是调用clone来实现的。
#include <sched.h>
功能:创建一个进程/轻量级进程
原型
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg, .../* pid_t *ptid, struct user_desc *tls, pid_t *ctid */ );
参数
child_stack:子栈(用户栈)
flags:
返回值
创建失败,返回-1;创建成功,返回线程ID
/* Prototype for the raw system call */
long clone(unsigned long flags, void *child_stack, void *ptid, void *ctid, struct pt_regs *regs);
创建多线程
#include <iostream>
#include <string>
#include <vector>
#include <pthread.h>
#include <unistd.h>
using namespace std;
void* start_routime(void* args)
string name = static_cast<const char*>(args);//安全地进行强制类型转换
while(1)
cout << "new thread is created! name: " << name << endl;
sleep(1);
int main()
vector<pthread_t> threadIDs (10, pthread_t());
for(size_t i = 0; i < 10; i++)
pthread_t tid;
char nameBuffer[64];
snprintf(nameBuffer, sizeof(nameBuffer), "%s : %d", "thread", i);
pthread_create(&tid, nullptr, start_routime, (void*)nameBuffer);//是缓冲区的起始地址,无法保证创建的新线程允许先后次序
threadIDs[i] = tid;
sleep(1);
for(auto e : threadIDs)
cout << e << endl;
while(1)
cout << "new thread is created! name: main" << endl;
sleep(1);
return 0;
现象:当创建多个线程的循环中没有添加sleep语句时,我们可能看到的输出一直是某个线程。
分析:当我们创建新的线程时,每个线程是独立的执行流。首先,创建多个新线程,谁先运行是不确定的;其次,因为nameBuffer是被所有线程共享的,主线程是把缓冲区的起始地址传给每个线程,在循环里nameBuffer在一直被主进程更新,所以每个进程能拿到的都是被主进程更新后的最新的进程id。
多线程数据私有
所以,如果我们想让各个线程独立执行代码,这样的写法是不对的,那如何给线程传递正确的结构呢?既然nameBuffer是同一个变量一样的地址,那就每次传入不同的地址呀
//当成结构体使用
class ThreadData
public:
pthread_t tid;
char nameBuffer[64];
;
//对应的操作函数如下
void* start_routime(void* args)//args传递的时候,也是拷贝了一份地址,传过去。不管是传值传参还是传引用传参,都会发生拷贝
ThreadData* td = static_cast<ThreadData*>(args);//安全地进行强制类型转换
int cnt = 10;
while(cnt)
cout << "new thread is created! name: " << td->nameBuffer << " 循环次数cnt:" << cnt << endl;
cnt--;
sleep(1);
delete td;
return nullptr;
int main()
vector<ThreadData*> threads;
for(size_t i = 0; i < 10; i++)
// 此处 td是指针,传给每个线程的td指针都是不一样的,实现数据私有
ThreadData* td = new ThreadData();
snprintf(td->nameBuffer, sizeof(td->nameBuffer), "%s : %d", "thread", i + 1);
pthread_create(&td->tid, nullptr, start_routime, (void*)td);
threads.push_back(td);
for(auto& e : threads)
cout << "create thread name: " << e->nameBuffer << " tid:" << e->tid << endl;
int cnt = 7;
while(cnt)
cout << "new thread is created! name: main" << endl;
cnt--;
sleep(1);
return 0;
通过传new出来的结构体指针,实现多线程数据私有!
重入状态
start_routime()函数同时被10个线程访问,在程序运行期间处于重入状态。站在变量的角度,由于函数没有访问全局变量,访问的都是局部变量,故是可重入函数。【严格来说,这不算可重入函数,因为cout是访问文件的,而我们只有一个显示器,在输出到显示器的时候有可能会出错】
对全局变量进行原子操作的是可重入函数。
独立栈空间
每个线程都有自己独立的栈空间
线程ID
线程id是它独立栈空间的起始地址
线程等待pthread_join
**join是阻塞式等待。**线程也是要被等待的,如果不等待,会造成类似僵尸进程的问题–内存泄漏。作用1、获取线程退出信息;2、回收线程资源。但与进程不同的是,线程不用获取退出信号,因为一旦线程出异常,收到信号了,整个进程都会退出。
pthread_join不考虑异常问题,线程出异常了进程直接来处理。
start_routime返回值的类型是void*,pthread_join()中retval参数的类型是void**。两者之间有关联。
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);
参数
thread:线程id
retval输出型参数:用于获取线程函数结束时,返回的退出结果
返回值
成功返回0,失败返回错误码
具体使用:
void* retval = nullptr;//相当于把start_routime返回的指针(这里的指针是指针地址,是个字面值)存到ret(这里的ret是指针变量)里面去
int n = pthread_join(tid, &retval);
assert(n == 0);
线程终止时,可以返回一个指针(比如堆空间的地址、对象的地址等),并可以被主线程取到,由此可以完成信息交互。
例如进程,有阻塞式等待和非阻塞式等待,用信号捕捉函数,设置成signal(SIGCHLD, SIG_IGN);就可;而进程没有非阻塞式等待。
线程分离pthread_detach
默认情况下,我们创建的新线程都是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄漏,如果不关心线程的返回值,join是一种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源。
功能:分离线程,与joinable是互斥的
#include <pthread.h>
原型:
int pthread_detach(pthread_t thread);
返回值:
成功返回0;失败返回错误码,但不设置错误码,不被设置到errno
//使用1:线程自己分离自己
pthread_detach(pthread_self());
//使用2:主线程分离其他线程
当线程自己分离自己后,主线程再调用pthread_join()【需要主动让主进程的join后与detach执行】,此时jion函数会返回22,表示Invalid argument
为什么要先让detach执行,因为新线程和主线程谁先执行是不确定的,当新线程去执行自己的任务时,假设新线程还没来得及执行detach,而主线程就已经join了,那么detach就无效了。
功能:获取调用该函数的线程ID
#include <pthread.h>
pthread_t pthread_self(void);
线程终止
线程退出return/pthread_exit
-
return nullptr;return返回就表示该线程终止。 -
pthread_exit(nullptr);线程退出的专用pthread_exit()函数。#include <pthread.h>
void pthread_exit(void *retval);
exit用于终止进程,不能用于终止线程。任何一个执行流调用exit都会让整个进程退出。
发现了没,return和pthread_exit都有个nullptr参数!这个返回值会放在pthread库里面的。
后续线程等待时,就是到pthread库里取到这个值。
线程取消pthread_cancel
线程被取消的前提是线程已经在运行了,由主线程给对应的线程发送取消命令。收到的退出码retval是-1,-1实际上是宏#define PTHREAD_CANCELED ((void*) -1)。
原生线程库pthread
站在上层的角度(从语言层面)来看原生线程库:
在linux上,任何语言如果要实现多线程,必定要用到pthread库,如何看待C++11中的多线程呢?C++11中的多线程在linux环境下本质是对pthread库的封装。
#include <iostream>
#include <thread>
#include <unistd.h>
using namespace std;
void thread_run()
int cnt = 5;
while(cnt)
cout << "我是新线程" << endl;
sleep(1);
int main()
thread t1(thread_run);
while(true)
cout << "我是主线程" << endl;
t1.join();
return 0;
//这份代码用g++编译,如果不带-lpthread选项,就会报错!说明C++就是封装了原生线程库
用原生线程库写出来的代码,是不可跨平台的,但是效率更高;用C++写出来的多平台通用,但是效率偏低。
原生线程库是共享库,可以同时被多个用户使用。那么如何对用户创建出来的线程做管理呢?
linux给出的解决方案是,让原生线程库采用一定的方法对用户创建的线程做管理,只不过在库里需要添加的线程属性比较少(包括线程id等),会存在一个union pthread_attr_t;结构体里,然后与内核中的轻量级进程一一对应,内核提供线程执行流的调度。linux用户级线程:内核轻量级进程=1:1。
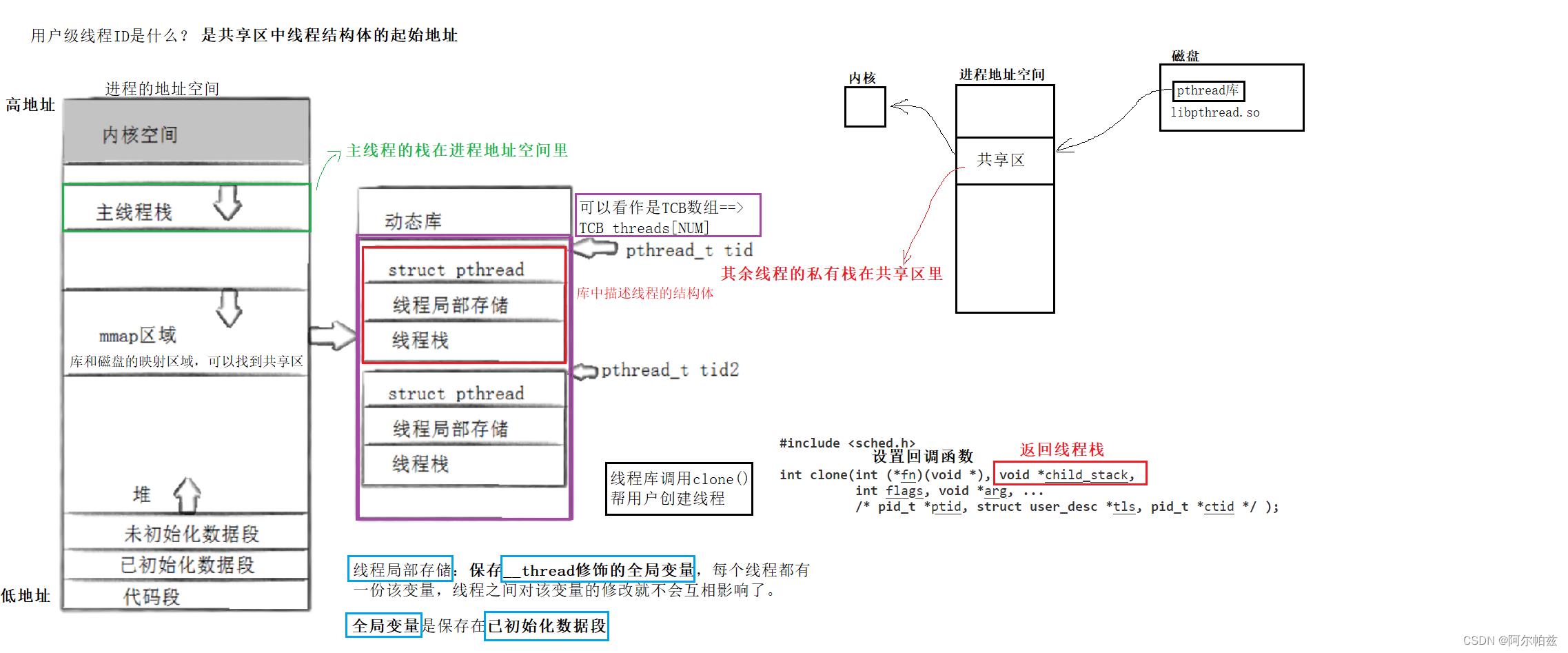
线程局部存储__thread
全局变量保存在进程地址空间的已初始化数据区的,被__thread修饰的全局变量保存在线程局部存储中(共享区的线程结构体里)。这个是线程独有的,介于全局变量和局部变量之间的一种存储方案。
以上是关于多线程控制讲解与代码实现的主要内容,如果未能解决你的问题,请参考以下文章