Cassandra 如何读取数据/写模式如果影响读取
Posted yuxiaohao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Cassandra 如何读取数据/写模式如果影响读取相关的知识,希望对你有一定的参考价值。
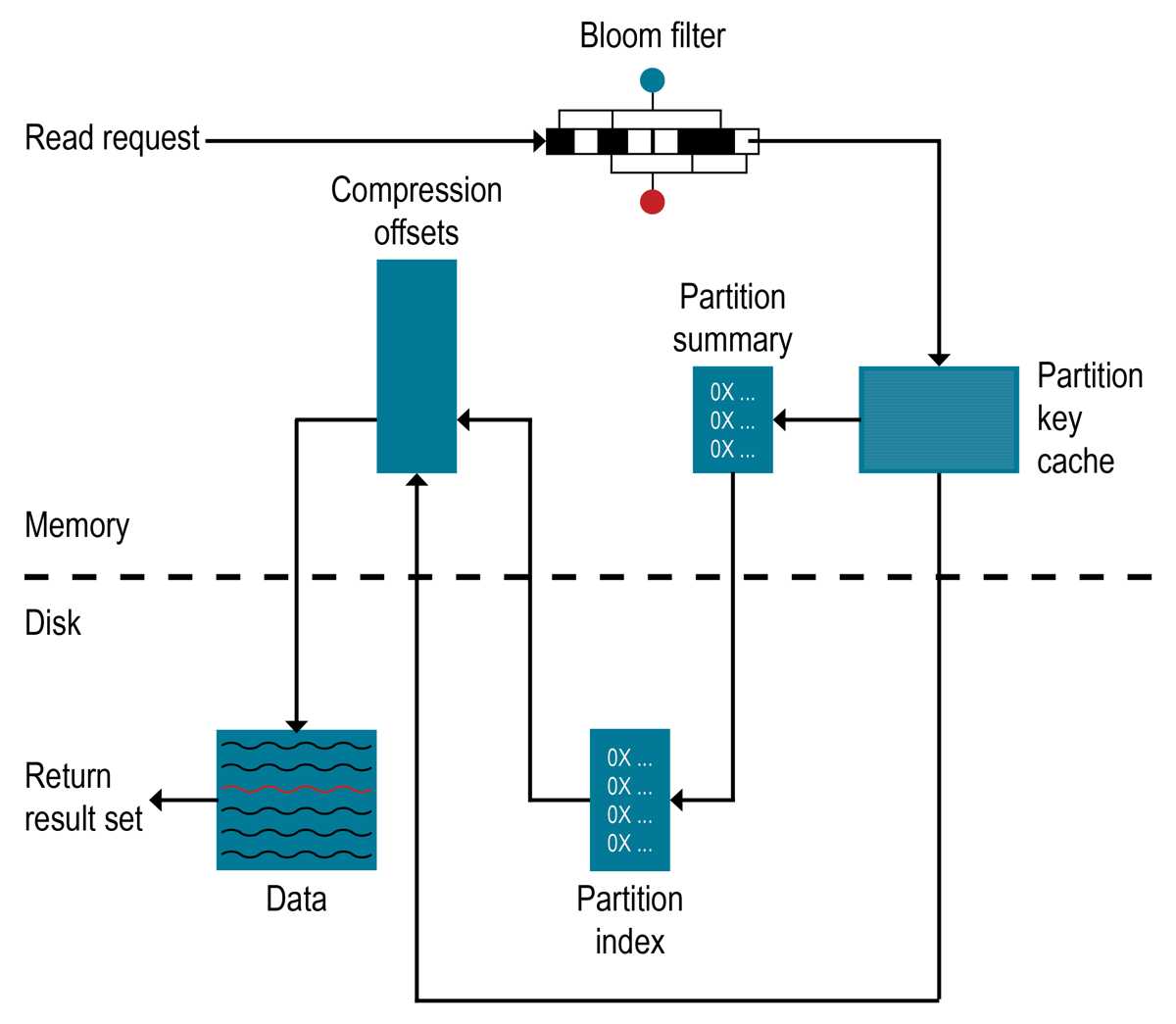
如何读取数据?
为了满足读取要求,Apache Cassandra™(DDAC)数据库的DataStax分布必须组合来自活动内存表和可能多个SSTable的结果。如果内存表具有所需的分区数据,则将读取该数据并将其与SSTables中的数据合并。
- 检查内存表
- 检查行缓存(如果启用)
- 检查布隆过滤器
- 检查分区键缓存(如果启用)
- 如果在分区键缓存中找到了分区键,则直接转到压缩偏移量映射表;如果找不到分区键,则直接检查分区摘要
如果选中分区摘要,则访问分区索引
- 使用压缩偏移量映射找到磁盘上的数据
- 从磁盘上的SSTable提取数据
行缓存和键缓存请求流
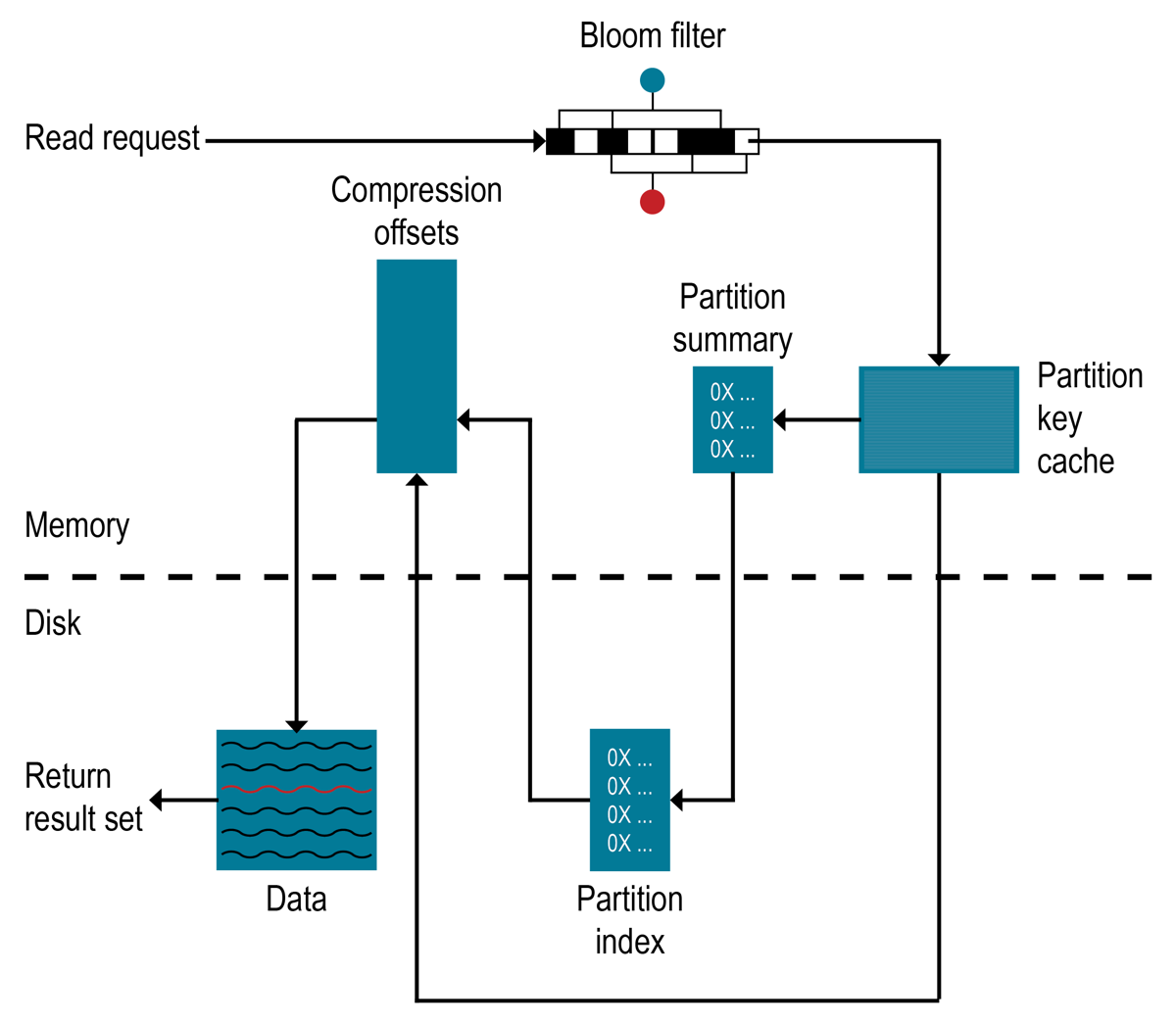
如何读取数据?
为了满足读取要求,Apache Cassandra™(DDAC)数据库的DataStax分布必须组合来自活动内存表和可能多个SSTable的结果。如果内存表具有所需的分区数据,则将读取该数据并将其与SSTables中的数据合并。
- 检查内存表
- 检查行缓存(如果启用)
- 检查布隆过滤器
- 检查分区键缓存(如果启用)
- 如果在分区键缓存中找到了分区键,则直接转到压缩偏移量映射表;如果找不到分区键,则直接检查分区摘要
如果选中分区摘要,则访问分区索引
- 使用压缩偏移量映射找到磁盘上的数据
- 从磁盘上的SSTable提取数据
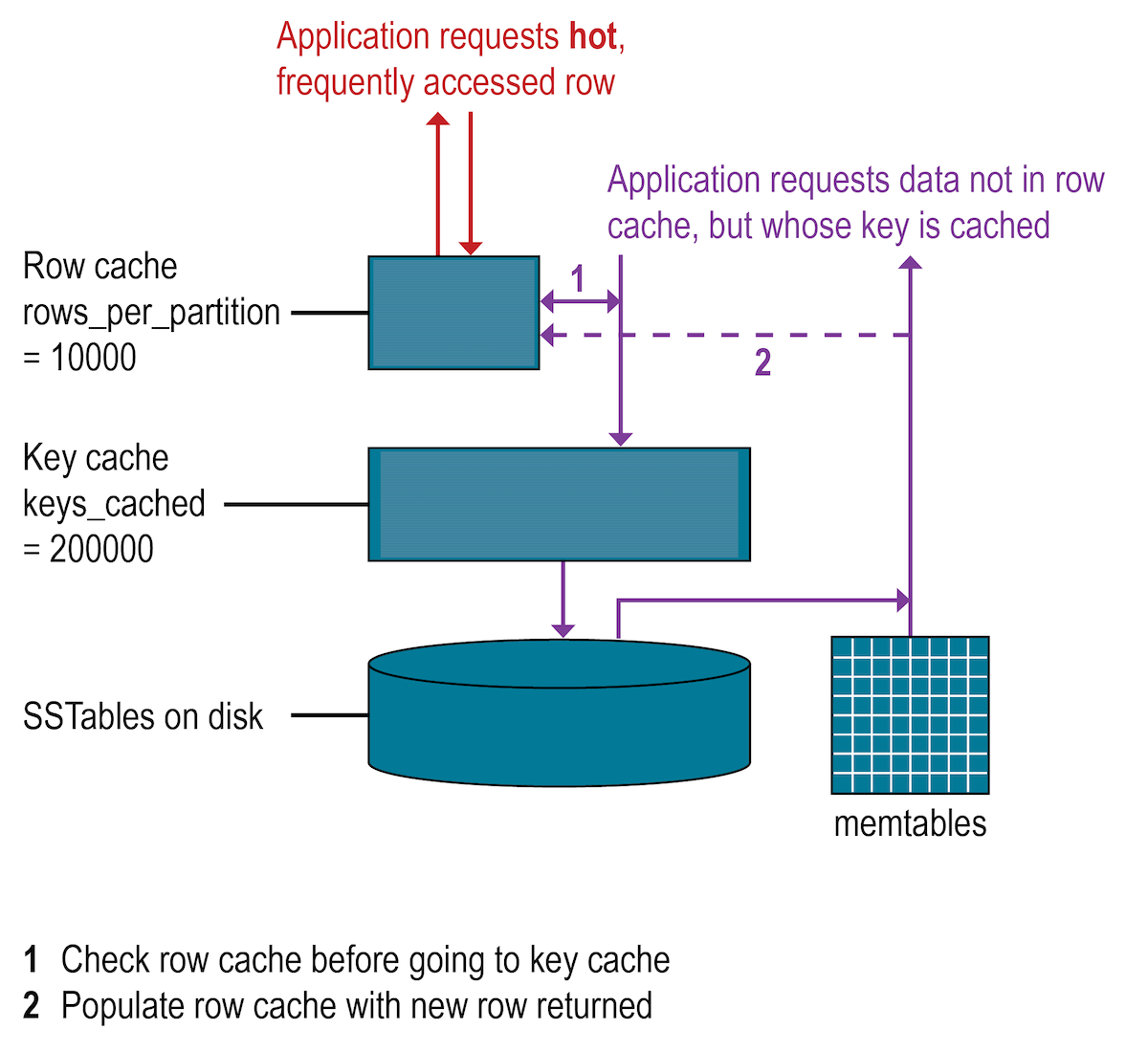
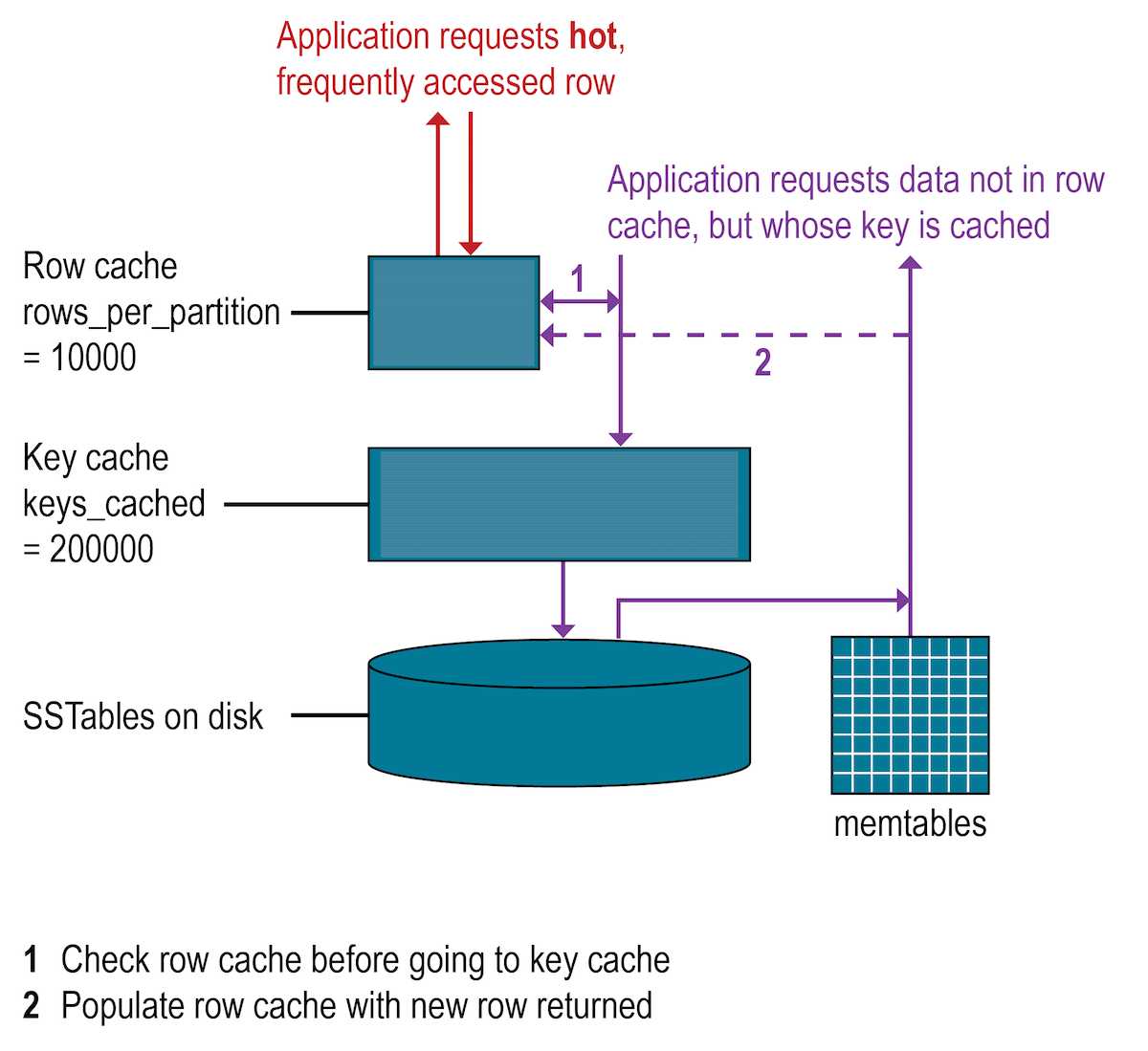
在所有数据库中,典型的是,当最需要的数据放入内存时,读取速度最快。操作系统页面缓存最擅长提高性能,尽管行缓存可以为读取密集型操作(读取操作占负载的95%)提供一些改进。不建议将行高速缓存用于写密集型操作。如果启用了行高速缓存,它将在磁盘的SSTables中的磁盘上存储分区数据的子集。在卡桑德拉,行缓存使用减轻Java虚拟机(JVM)中垃圾回收压力的实现方式存储在完全堆外的内存中。行高速缓存中存储的子集在指定的时间段内使用可配置的内存量。当高速缓存已满时,行高速缓存使用LRU(最近最少使用)收回来回收内存。
行缓存大小以及要存储的行数都是可配置的。配置要存储的行数是一项有用的功能,可以使“最后10个项目”查询的读取速度非常快。如果启用了行缓存,则将从行缓存中读取所需的分区数据,从而有可能在磁盘上保存两次查找。行高速缓存中存储的行是经常访问的行,在访问它们时,这些行将合并并从SSTable保存到行高速缓存中。存储后,数据可用于以后的查询。行缓存不是直写的。如果对该行进行写操作,则该行的缓存无效,直到读取该行后才再次缓存。同样,如果分区已更新,则整个分区将从缓存中删除。检查布隆过滤器。
布隆过滤器(Bloom Filter)
每个SSTable都有一个关联的Bloom过滤器,该过滤器可以确定SSTable不包含某些分区数据。布隆过滤器还可以通过缩小键池来确定分区数据存储在SSTable中的可能性,这增加了分区键查找。
该Cassandra数据库检查布隆过滤器中发现哪些SSTables可能有请求的分区数据。如果Bloom过滤器不排除SSTable,则Cassandra数据库检查分区键缓存。并非由Bloom筛选器标识的所有SSTable都将具有数据。因为Bloom过滤器是一个概率函数,所以有时可能返回假阳性。
Bloom筛选器存储在堆外内存中,并增长到每十亿个分区约1-2 GB。在极端情况下,每一行都可以有一个分区,因此一台机器可以轻松拥有数十亿个这样的条目。要以内存换取性能,请调整Bloom过滤器。
分区键缓存(Partition Key Cache)
如果启用了分区键,则它将分区索引的缓存存储在堆外内存中。密钥高速缓存使用少量可配置的内存,并且每次“命中”都会在读取操作期间节省一次查找。如果在键高速缓存中找到了分区键,则Cassandra数据库可以直接转到压缩偏移量映射以在磁盘上找到包含数据的压缩块。分区键高速缓存一旦预热就可以更好地发挥作用,并且可以大大改善冷启动读取的性能,因为在这种情况下,键高速缓存尚未将键存储在键高速缓存中。如果节点上的内存非常有限,则可以限制保存在键高速缓存中的分区键的数量。如果在密钥缓存中未找到分区密钥,则搜索分区摘要。
分区密钥缓存大小和要存储在缓存中的密钥数是可配置的。
分区摘要
分区摘要是一种堆外内存结构,用于存储分区索引的采样。一分区索引包含所有分区键,而每一个分区汇总样本X键,以及它们的位置在索引文件映射。例如,如果分区摘要设置为每20个密钥采样一次,则它将第一个密钥的位置存储为SSTable文件的开头,第20个密钥及其在文件中的位置,依此类推。尽管不如知道分区键的位置那么精确,但是分区摘要可以缩短扫描以查找分区数据位置。找到可能的分区键值的范围后,将搜索分区索引。
通过配置采样频率,您可以以内存换取性能。分区摘要的粒度越多,它将使用的内存越多。使用表定义中的min_index_interval和max_index_interval属性可以更改采样频率。可以使用index_summary_capacity_in_mb属性配置固定数量的内存,并且默认为堆大小的5%。
分区索引(artition Index)
压缩偏移图
压缩偏移量映射增长到每TB压缩的1-3 GB。压缩的数据越多,所需的压缩块数越多,压缩偏移表也越大。即使经过压缩偏移量映射会消耗CPU资源,默认情况下也会启用压缩。启用压缩可使页面缓存更有效,并且通常会导致及时搜索。
写模式如何影响读取?
重要的是要考虑写操作如何影响群集中的读操作。在 压实过程是可配置的,可以显著影响读取性能。当频繁更新行时,使用SizeTieredCompactionStrategy(STCS)会导致数据碎片。该LeveledCompactionStrategy(LCS)的目的是要防止这种情况下碎裂,并建议用于读取密集型工作负载。
以上是关于Cassandra 如何读取数据/写模式如果影响读取的主要内容,如果未能解决你的问题,请参考以下文章