join算法原理和优化
Posted zx125
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了join算法原理和优化相关的知识,希望对你有一定的参考价值。
数据准备
t1 100行
id 主键
a
t2 1000行
id 主键
a 索引
bIndex Nested-Loop Join
sql
select * from t1 straight_join t2 on (t1.a=t2.a);
t1为驱动表,t2为被驱动表执行流程
1.从表 t1 中读入一行数据 R;
2.从数据行 R 中,取出 a 字段到表 t2 里去查找;
3.取出表 t2 中满足条件的行,跟 R 组成一行,作为结果集的一部分;
4.重复执行步骤 1 到 3,直到表 t1 的末尾循环结束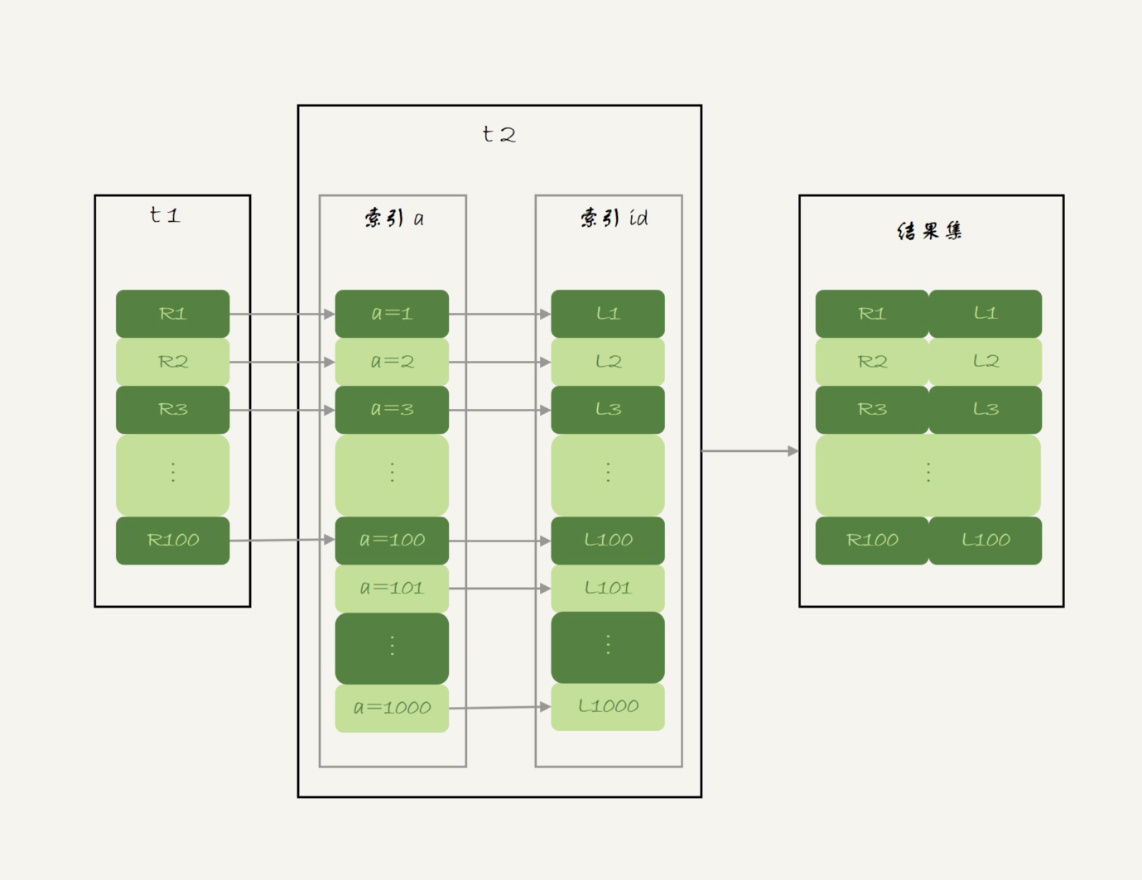
执行效率
由于t2的a有索引,所以大约扫描了200行Block Nested-Loop Join
sql
select * from t1 straight_join t2 on (t1.a=t2.b);
t1为驱动表,t2为被驱动表执行流程
1.把表 t1 的数据读入线程内存 join_buffer 中,由于我们这个语句中写的是 select *,因此是把整个表 t1 放入了内存;
2.扫描表 t2,把表 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回。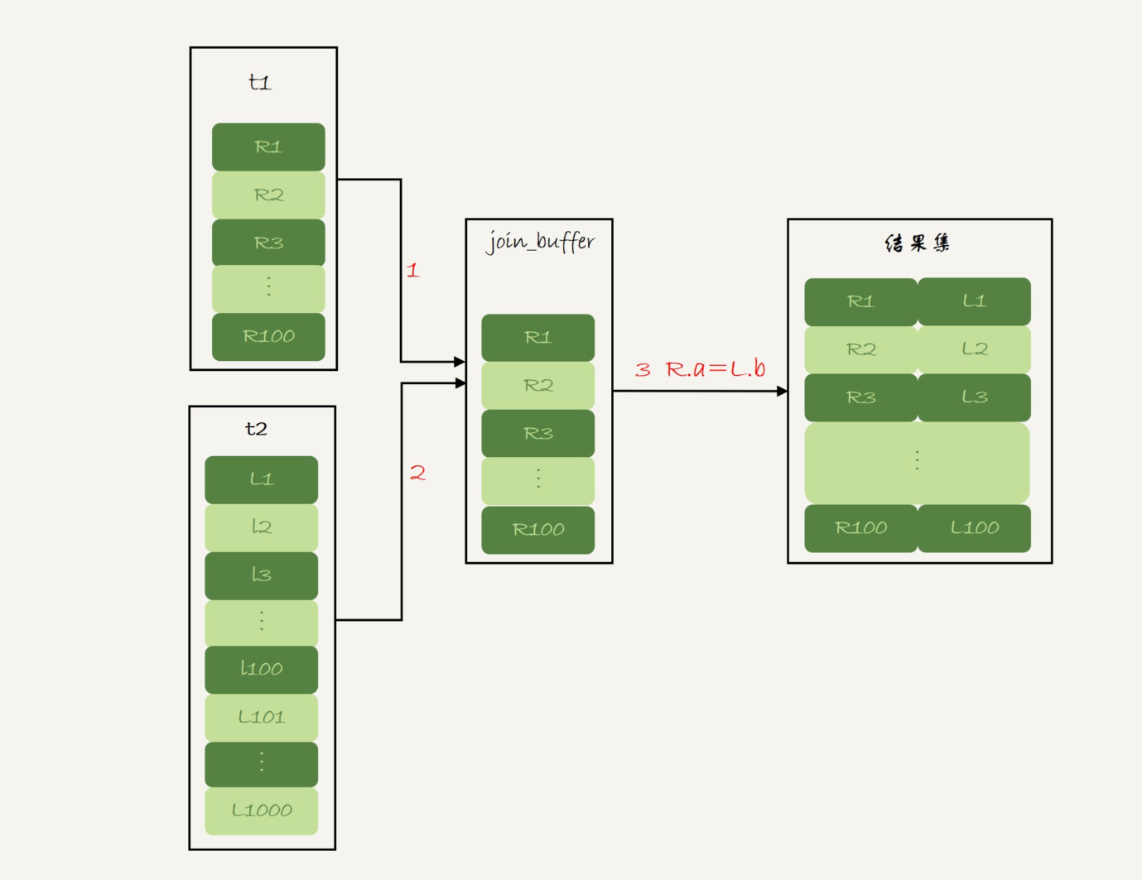
执行效率
由于t2的b没有有索引,没查t1一条数据,t2差不多都是一次全表查询,扫描最多为100X1000=100000如果表t1过大
因为join_buffer大小有限,所以出现了下面的执行流程执行流程2
1.扫描表 t1,顺序读取数据行放入 join_buffer 中,放完第 88 行 join_buffer 满了,继续第 2 步;
2.扫描表 t2,把 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回;
3.清空 join_buffer;
4.继续扫描表 t1,顺序读取最后的 12 行数据放入 join_buffer 中,继续执行第 2 步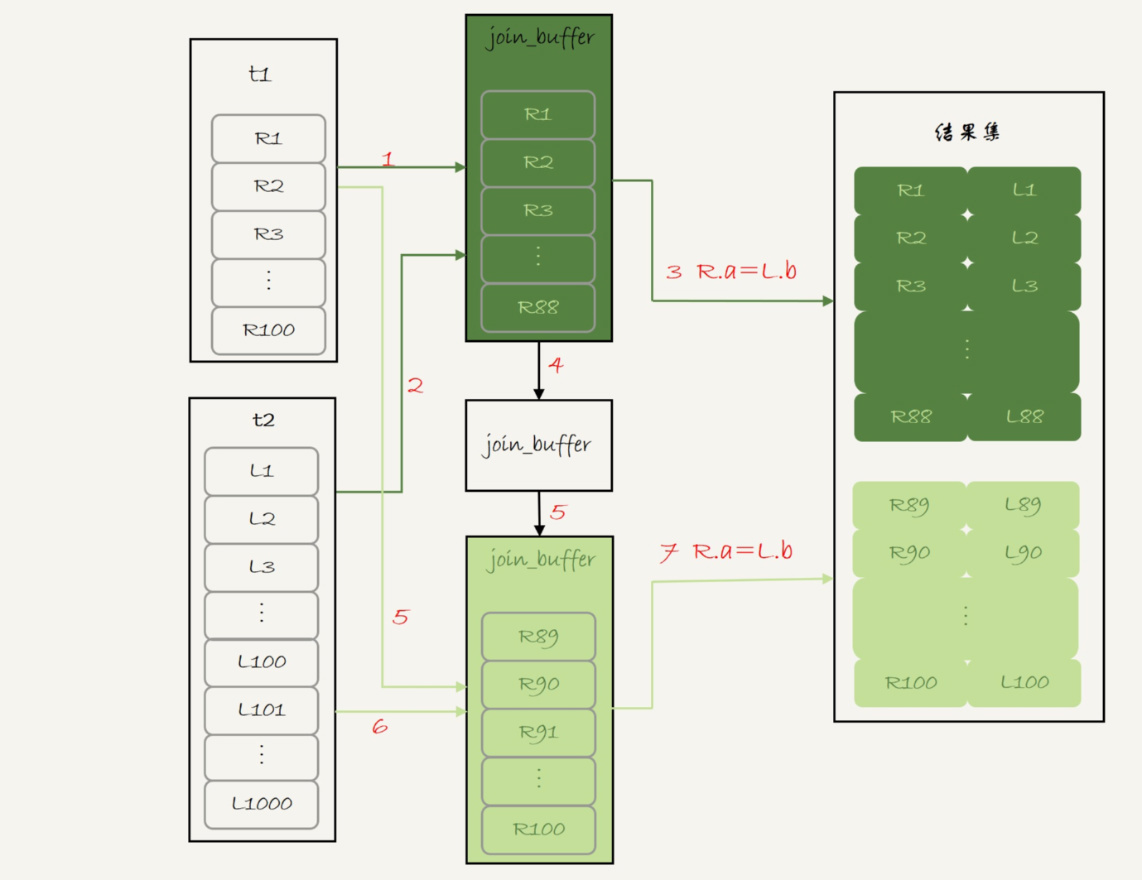
执行效率
由于涉及join_buffer,清空和加数据,他的效率更低优化
小表
综合字段数,记录数小的表作为驱动表join_buffer设置更大空间
可以减少join_buffer的清空次数重要:加索引
200和10w,你自己选,如果是10w和10w呢,无法想象以上是关于join算法原理和优化的主要内容,如果未能解决你的问题,请参考以下文章