Spark编程模型(核心篇 一)
Posted zhanghy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark编程模型(核心篇 一)相关的知识,希望对你有一定的参考价值。
目录
- RDD概述
- RDD实现
- RDD运行流程
- RDD分区
- RDD操作分类
- RDD编程接口说明
一、RDD概述
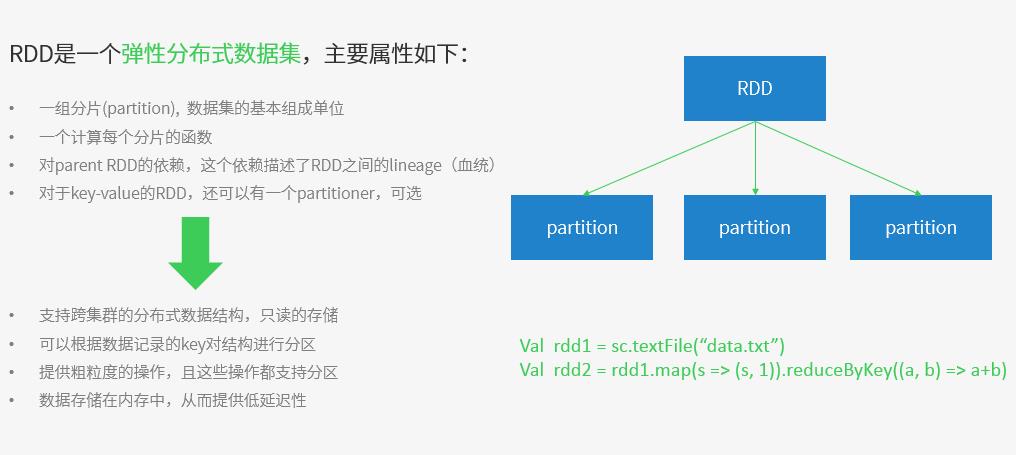
- RDD:是Resilient distributed datasets的简称,中文为弹性分布式数据集;是Spark最核心的模块和类
- DAG:
- Spark将计算转换为一个有向无环图(DAG)的任务集合,通过为RDD提供一种基于粗粒度变换(如map, filter, join等)的接口
- RDD类型:mappedRDD, SchemaRDD
- RDD操作分类:转换操作(又分为创建操作、转换操作)、行为操作(又分控制操作-进行RDD持久化、行为操作)
二、RDD实现
1、作业调度
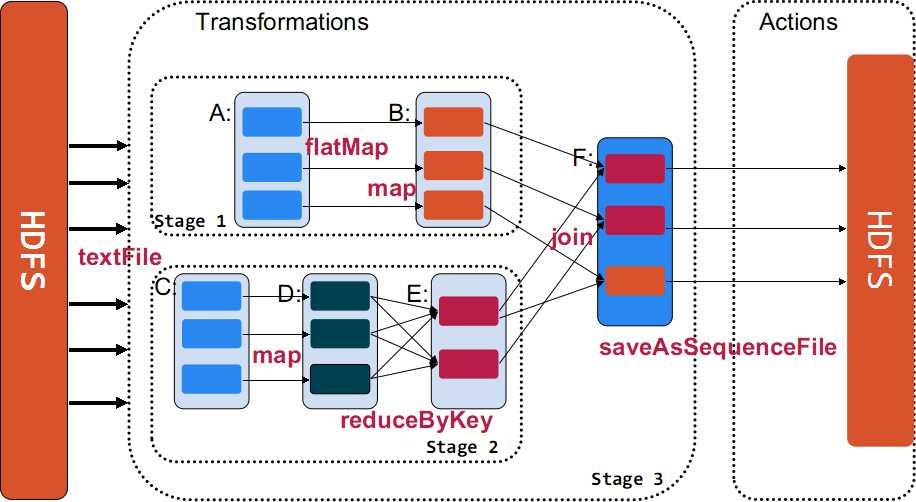
A、当对RDD执行转换操作时,调度器会根据RDD的“血统”来构建由若干高度阶段(Stage)组成的有向无环图(DAG), 每个阶段包含尽可能多的连续“窄依赖”转换
B、另外,调度分配任务采用“延时调度”机制,并根据”数据本地性“来确定
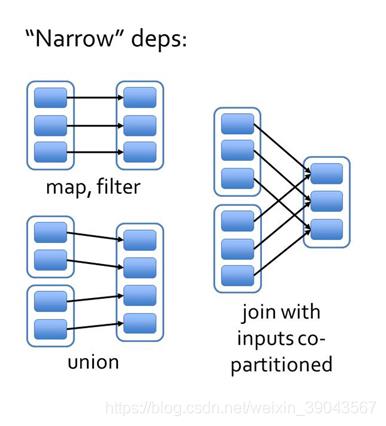
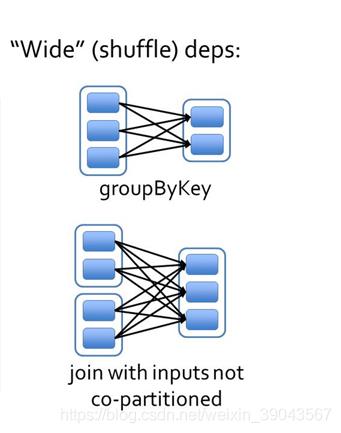
宽依赖与窄依赖:
- 窄依赖是指父RDD的每个分区只被子RDD的一个分区所使用,子RDD一般对应父RDD的一个或者多个分区。(与数据规模无关)不会产生shuffle
- 宽依赖指父RDD的多个分区可能被子RDD的一个分区所使用,子RDD分区通常对应所有的父RDD分区(与数据规模有关),会产生shuffle
- 更细化文档可参见 https://blog.csdn.net/weixin_39043567/article/details/89520896
2、解析器集成:三个步骤 A、用户每一行输入编译成一个类 B、类加载至JVM中 C、调用 类函数
3、内存管理:
- 提供了3种持久化RDD的存储策略: A、未序列化Java对象存在内存中 B、序列化数据存在内存中 C、序列化数据存储在磁盘中
- 对内存使用LRU回收算法进行管理 (以RDD为单位)
4、检查点(Checkpoint)支持
- 为RDD提供设置Checkpoint的API,以将一些Checkpoint保存在外部存储中
5、多用户管理:提供公平调度算法、延迟调度、作业取消机制、细粒度资源共享、数据本地性
三、RDD运行流程
RDD在Spark中运行大概分为以下三步:
- 创建RDD对象
- DAGScheduler模块介入运算,计算RDD之间的依赖关系,RDD之间的依赖关系就形成了DAG
- 每一个Job被分为多个Stage。划分Stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个Stage,避免多个Stage之间的消息传递开销
示例图如下:
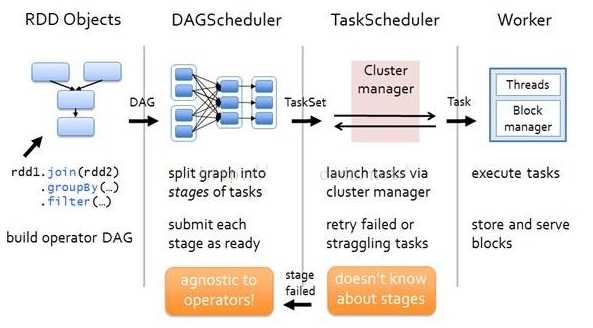
- 以下面一个按 A-Z 首字母分类,查找相同首字母下不同姓名总个数的例子来看一下 RDD 是如何运行起来的
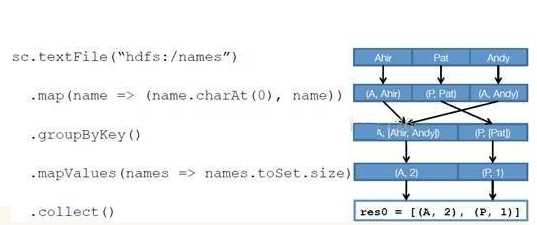
- 创建 RDD 上面的例子除去最后一个 collect 是个动作,不会创建 RDD 之外,前面四个转换都会创建出新的 RDD 。因此第一步就是创建好所有 RDD( 内部的五项信息 )?
- 创建执行计划 Spark 会尽可能地管道化,并基于是否要重新组织数据来划分 阶段 (stage) ,例如本例中的 groupBy() 转换就会将整个执行计划划分成两阶段执行。最终会产生一个 DAG(directed acyclic graph ,有向无环图 ) 作为逻辑执行计划
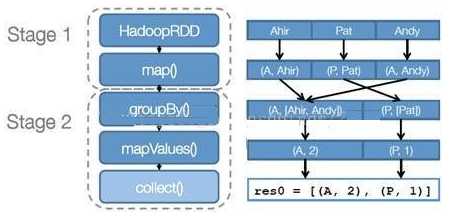
- 调度任务 将各阶段划分成不同的 任务 (task) ,每个任务都是数据和计算的合体。在进行下一阶段前,当前阶段的所有任务都要执行完成。因为下一阶段的第一个转换一定是重新组织数据的,所以必须等当前阶段所有结果数据都计算出来了才能继续
三、RDD分区
1、RDD分区计算
2、RDD分区函数,以及默认提供两种划分器:哈希分区划分器和范围分区划分器
四、RDD操作函数
Spark转换操作函数讲解: https://www.cnblogs.com/jinggangshan/p/8086492.html
https://blog.csdn.net/taokeblog/article/details/103796987
行动操作函数讲解:
五、RDD编程接口说明
Spark提供了通用接口来抽象每个RDD,包括
1、分区信息:数据集的最小分片
2、依赖关系
3、函数
4、划分策略和数据位置的元数据
以上是关于Spark编程模型(核心篇 一)的主要内容,如果未能解决你的问题,请参考以下文章
Dataflow编程模型和spark streaming结合