selenium3使用谷歌无头浏览器截图
Posted beimingyouyuqingcangchuli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了selenium3使用谷歌无头浏览器截图相关的知识,希望对你有一定的参考价值。
无头浏览器即为Headless Browser,是没有图形用户界面的web浏览器,通常是通过编程或命令行界面来控制。
在正常使用selenium的时候,你必须担心CPU和/或内存的使用。这两种方式都与必须从被请求的URL中显示显示的图形的浏览器相关联。
当使用一个无头的浏览器时,我们不用担心这个。因此,我们可以预期我们编写的脚本的内存消耗会降低,执行速度也会更快。当有的人说,那我没法看到浏览器响应的过程,我不能在这边盯着浏览器自己执行我的用例。。。喔犒!写自动化本来就是为了效率的,做截图就可以了嘛,盯着?你还不如下手点呢。。。咳咳,书接上文
下载安装selenium,谷歌浏览器 自行下载
谷歌浏览器与 驱动的对应关系如下图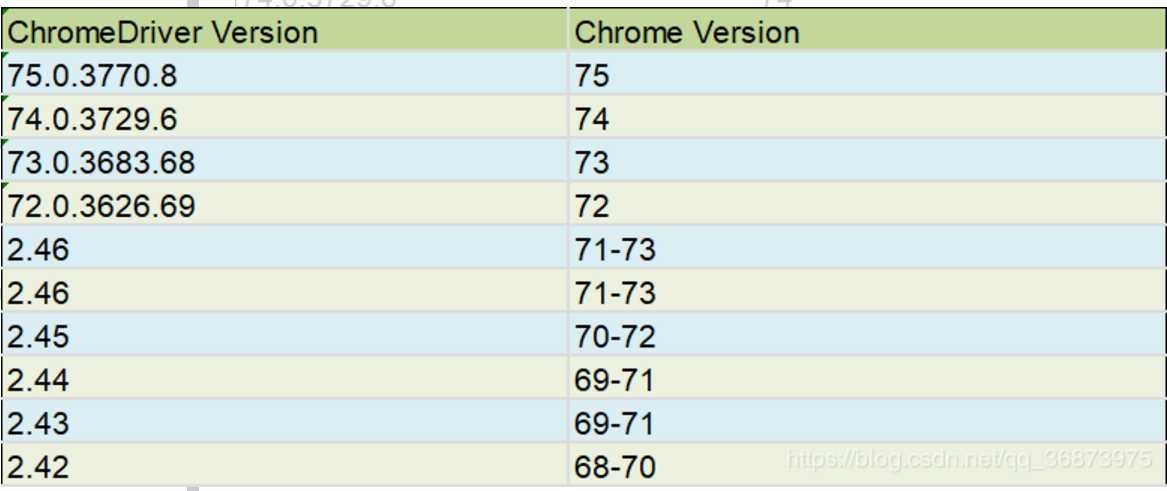
ChromeDriver仓库地址:
http://chromedriver.storage.googleapis.com/index.html
谷歌浏览器查看版本方式:
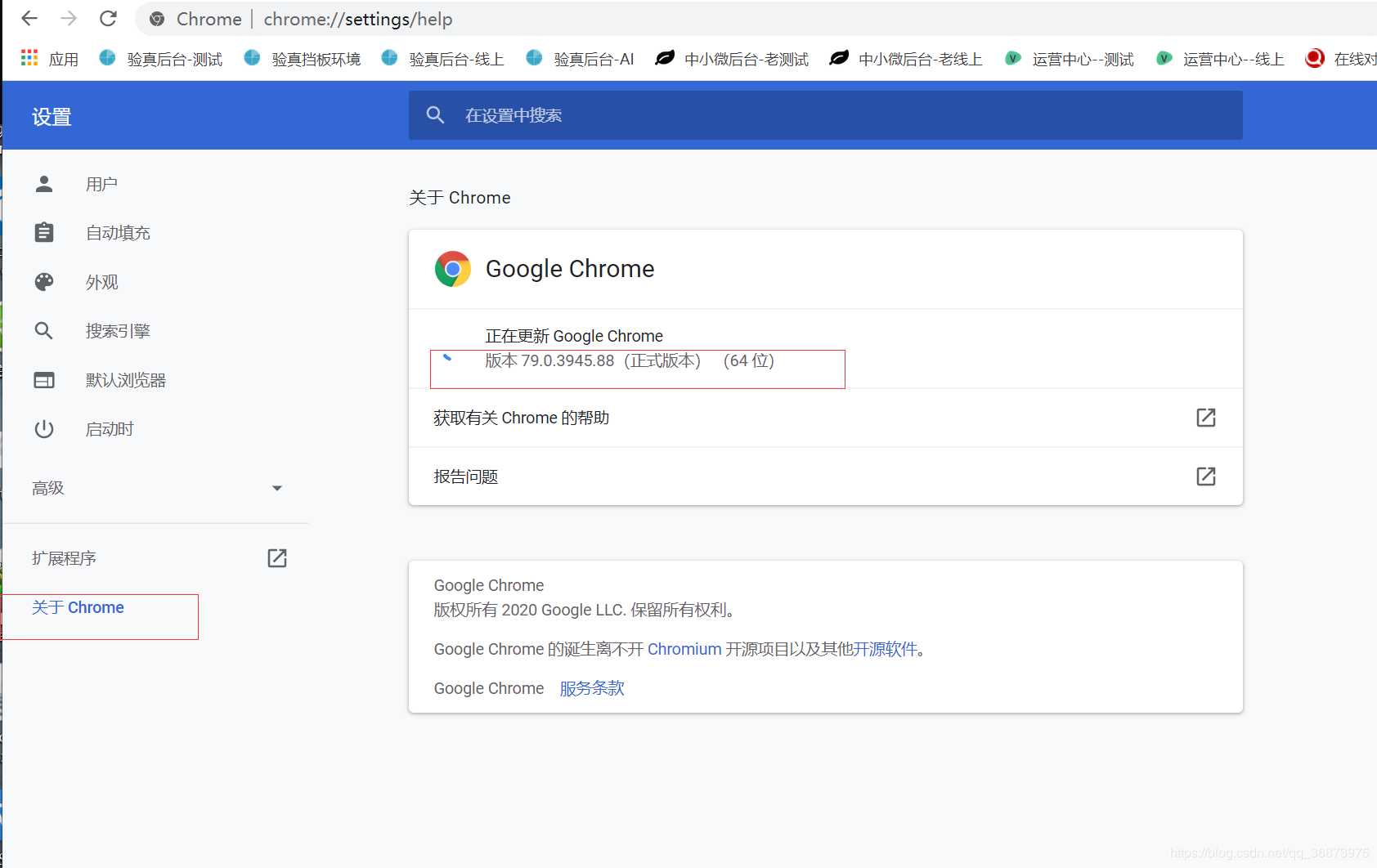
下载好驱动后放置在指定文件夹内备用。
编写脚本
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
#创建参数对象
chrome_options = Options()
#固定写法
chrome_options.add_argument(‘--headless‘)
chrome_options.add_argument(‘--disable-gpu‘)
#驱动路径
path = r‘C:Chromedriverchromedriver.exe‘
#创建浏览器对象
browser = webdriver.Chrome(executable_path=path,chrome_options=chrome_options)
#请求地址
url =‘http://www.baidu.com/‘
#发出请求
browser.get(url)
#休眠三秒
time.sleep(3)
#截图并保存在本地C盘TEST文件夹内
browser.save_screenshot("C:TESTaid2.png")
#截图保存在项目下
browser.save_screenshot(‘phaid.png‘)
#其他截图方法
#browser.get_screenshot_as_base64()
#browser.get_screenshot_as_file()
#browser.get_screenshot_as_png()
#退出
browser.quit()
执行后生成图片。
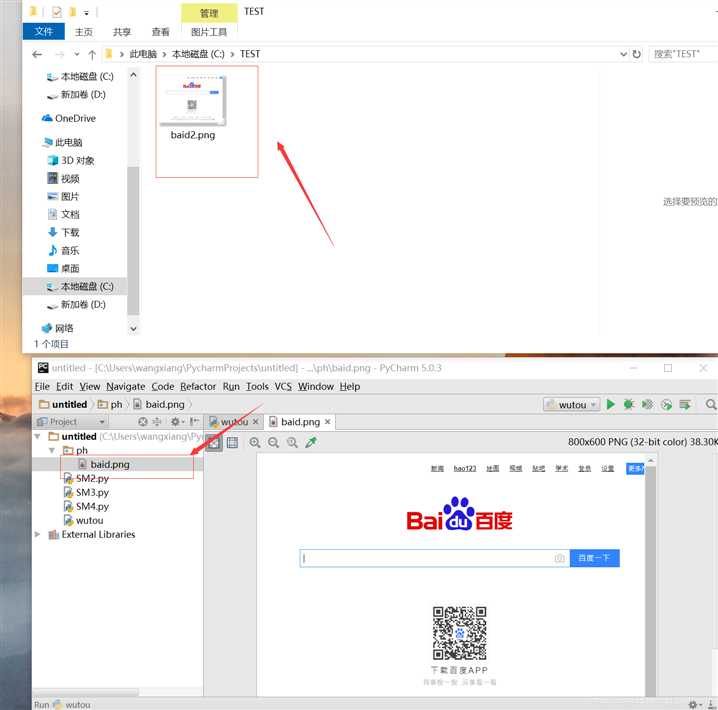
selenium4圣诞节已经发布,然后新功能API支持的更广泛,selenium的文档,官方自selenium2发布以来就从来没有更新过,哪怕是selenium3发布之后,selenium的官方也是不带动的,这次selenium的官方终于把selenium4的官方文档更新了。。。。。额,真香。
以上是关于selenium3使用谷歌无头浏览器截图的主要内容,如果未能解决你的问题,请参考以下文章