语义分割PointRend
Posted trevo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了语义分割PointRend相关的知识,希望对你有一定的参考价值。
方法
输入是CxWxH的特征图,特征图是原图的1/4或1/16;输出是比输入分辨率更大的ont-hot编码形式的特征图,KxW‘xH‘。
模块具体有如下的三步:
1)选择少数的一些点进行预测,避免在高分辨率的输出中过量的计算所有的像素
2)每个被选中的点,点的特征被提取,真值点的特征被计算通过双线性插值,然后沿着通道维度编码子像素信息预测分割
3)head:接一个小的网络,进行预测
训练和测试中如何选点
测试:选点工作主要是受图形学中adaptive subdivision的启发,adaptive subdivision的主要思想是通过只计算那些最可能与周围像素不同的点去高效的渲染图像,所有其他的位置,都通过插值的方法计算输出的值。每一步,我们迭代的渲染输出的mask,也就是需要经过一个coarse-to-fine的过程。coarse的预测是由分割的head得到的。在每次的迭代中,PointPend使用双线性插值上采样前一步分割预测结果,然后在这个更密集的特征图中选择N个最不确定的点,比方说概率接近0.5的点。然后计算这N个点的特征表示并且预测它们的lables。这个过程一直被重复,直到上采样到需要的大小。其中的一次迭代如下图所示:
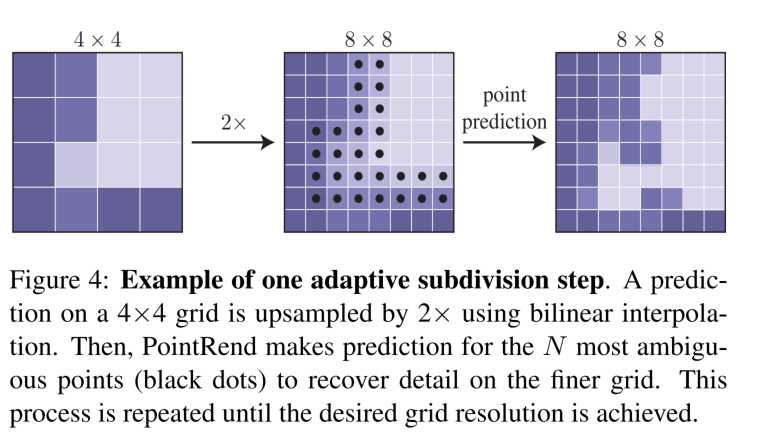
对于M0xM0的输入,想要得到MxM的输出。PointRend要求不超过Nlog2(M/M0)个点的预测,这个值比MxM小的多,这样可以减少计算量。例如:M0=7,M=224,执行5部subdivision。选择N=28*28,PointRend仅仅会预测28*28*4.25个点,比224*224的1/15还小。
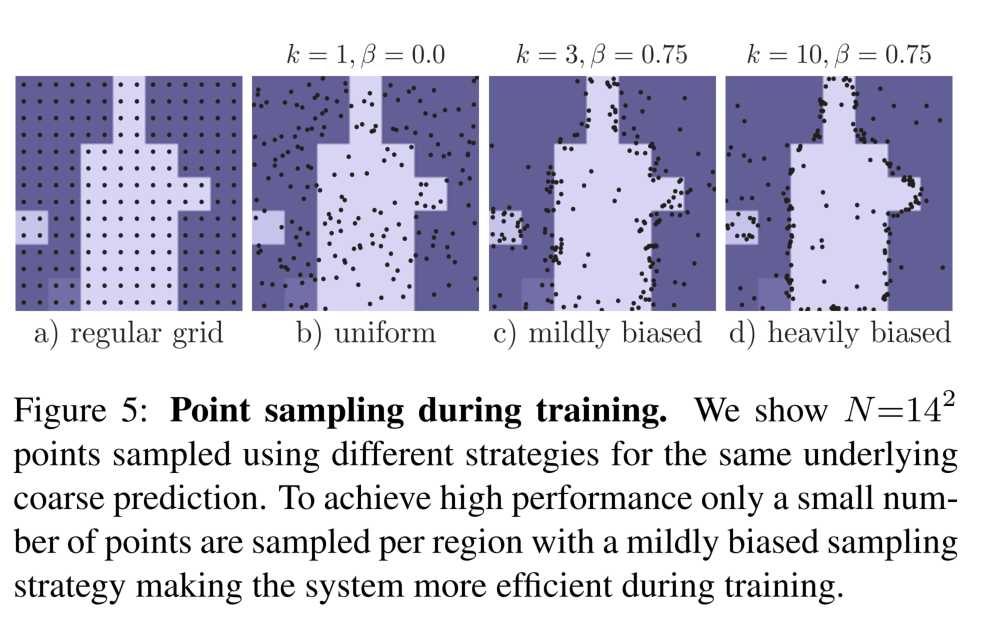
训练:训练过程中PointRend选择一些点然后重构他们的特征。原则上,选择策略与推理时应该一样,但是由于subdivision的操作是不可微的,没办法直接嵌入到具有BP的网络中训练,因此,训练过程中,使用基于随机采样的非迭代策略。在特征图上选择N个点(这里的N与推理时的N不同),它用来选择不确定的区域,同时保持一定程度的统一覆盖,使用如下三个原则:
1)Over generation: 在均匀分布中随机采样over-generation kN个点候选点(k>1)
2)Importance sampling: 重点关注着插值后kN个候选点中不确定的点并且对不确定性进行估计。在kN中选择βN个最不确定的点,β∈[0, 1]
3)Coverage:剩下的(1-β)N个点从均匀分布采样
训练的时候,预测值和损失函数仅仅在N个采样点上计算,更加高效比BP通过subdivide步骤。这个设计类似于Faster R-CNN中的 RPN+Fast R-CNN。
特征重建的Point-wise特征表示和进行预测的Point Head
PointRend重建特征通过结合细粒度的特征和粗糙的预测概率。
细粒度的特征:为了使得PointRend渲染好的分割细节,从特征图的每个采样点提取特征向量。因为一个点有一个2D的坐标系,在特征图上使用双线性插值计算特征向量。可以使用单尺度的特征图,仅仅只用resnet第2个残差块得到的特征图,也可以使用多尺度的特征图,同时使用resnet第2到第5个残差块的特征图。
粗糙预测图:细粒度的特征可以加强细节信息,但是在两方面是不足的。第一,他们不能得到包含明确区域的信息, 因此两个示例的边界框重叠的点有相同的细粒度特征。这个点也可以仅仅是一个实例的前景,因此,对于实例分割任务,对于相同的点,不同的区域可能预测得到不同的label,因此需要其他须臾的特定信息。第二,由于细粒度的特征图可能仅仅包含一些low-level的信息。在这种情况下,具有更多上下文和语义信息的特征图是由帮助的。这个问题对实例分割和语义分割都有影响。基于上面这些考虑,第二个特征类型是一个粗糙的分割预测图,每个点有一个K为的向量表示K类的预测。粗糙预测图用来提供全局信息,然而通道传递语义类别。这些粗糙特征图与显存的结构相似,训练过程中被监督。对于实例分割任务而言,可以是Mask R-CNN mask head 7*7的输出,对于语义分割,可以是步长16的特征图。
Point Head:给定每个选定点的point-wise特征表示,Head使用简单的多层感知机进行预测。在所有的点上MLP共享权重。类似于图卷积或者PointNet。
实验
实例分割(COCO和cityscapes上进行)
网络结构:MaskR-CNN ResNet50 + FPN,默认的mask head是 region-wise FCN
以上是关于语义分割PointRend的主要内容,如果未能解决你的问题,请参考以下文章