Flink异步之矛盾-锋利的Async I/O
Posted importbigdata
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink异步之矛盾-锋利的Async I/O相关的知识,希望对你有一定的参考价值。
维表JOIN-绕不过去的业务场景
在Flink 流处理过程中,经常需要和外部系统进行交互,用维度表补全事实表中的字段。
例如:在电商场景中,需要一个商品的skuid去关联商品的一些属性,例如商品所属行业、商品的生产厂家、生产厂家的一些情况;
在物流场景中,知道包裹id,需要去关联包裹的行业属性、发货信息、收货信息等等。
默认情况下,在Flink的MapFunction中,单个并行只能用同步方式去交互: 将请求发送到外部存储,IO阻塞,等待请求返回,然后继续发送下一个请求。这种同步交互的方式往往在网络等待上就耗费了大量时间。为了提高处理效率,可以增加MapFunction的并行度,但增加并行度就意味着更多的资源,并不是一种非常好的解决方式。
Async I/O异步非阻塞请求
Flink 在1.2中引入了Async I/O,在异步模式下,将IO操作异步化,单个并行可以连续发送多个请求,哪个请求先返回就先处理,从而在连续的请求间不需要阻塞式等待,大大提高了流处理效率。
Async I/O 是阿里巴巴贡献给社区的一个呼声非常高的特性,解决与外部系统交互时网络延迟成为了系统瓶颈的问题。
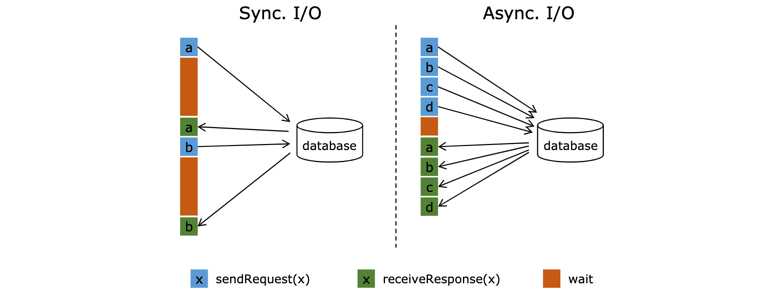
图中棕色的长条表示等待时间,可以发现网络等待时间极大地阻碍了吞吐和延迟。为了解决同步访问的问题,异步模式可以并发地处理多个请求和回复。也就是说,你可以连续地向数据库发送用户a、b、c等的请求,与此同时,哪个请求的回复先返回了就处理哪个回复,从而连续的请求之间不需要阻塞等待,如上图右边所示。这也正是 Async I/O 的实现原理。
详细的原理可以参考文末给出的第一个链接,来自阿里巴巴云邪的分享。
一个简单的例子如下:
public class AsyncIOFunctionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.setParallelism(1);
Properties p = new Properties();
p.setProperty("bootstrap.servers", "localhost:9092");
DataStreamSource<String> ds = env.addSource(new FlinkKafkaConsumer010<String>("order", new SimpleStringSchema(), p));
ds.print();
SingleOutputStreamOperator<Order> order = ds
.map(new MapFunction<String, Order>() {
@Override
public Order map(String value) throws Exception {
return new Gson().fromJson(value, Order.class);
}
})
.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Order>() {
@Override
public long extractAscendingTimestamp(Order element) {
try {
return element.getOrderTime();
} catch (Exception e) {
e.printStackTrace();
}
return 0;
}
})
.keyBy(new KeySelector<Order, String>() {
@Override
public String getKey(Order value) throws Exception {
return value.getUserId();
}
})
.window(TumblingEventTimeWindows.of(Time.minutes(10)))
.maxBy("orderTime");
SingleOutputStreamOperator<Tuple7<String, String, Integer, String, String, String, Long>> operator = AsyncDataStream
.unorderedWait(order, new RichAsyncFunction<Order, Tuple7<String, String, Integer, String, String, String, Long>>() {
private Connection connection;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
Class.forName("com.mysql.jdbc.Driver");
connection = DriverManager.getConnection("url", "user", "pwd");
connection.setAutoCommit(false);
}
@Override
public void asyncInvoke(Order input, ResultFuture<Tuple7<String, String, Integer, String, String, String, Long>> resultFuture) throws Exception {
List<Tuple7<String, String, Integer, String, String, String, Long>> list = new ArrayList<>();
// 在 asyncInvoke 方法中异步查询数据库
String userId = input.getUserId();
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("select name,age,sex from user where userid=" + userId);
if (resultSet != null && resultSet.next()) {
String name = resultSet.getString("name");
int age = resultSet.getInt("age");
String sex = resultSet.getString("sex");
Tuple7<String, String, Integer, String, String, String, Long> res = Tuple7.of(userId, name, age, sex, input.getOrderId(), input.getPrice(), input.getOrderTime());
list.add(res);
}
// 将数据搜集
resultFuture.complete(list);
}
@Override
public void close() throws Exception {
super.close();
if (connection != null) {
connection.close();
}
}
}, 5000, TimeUnit.MILLISECONDS,100);
operator.print();
env.execute("AsyncIOFunctionTest");
}
}
上述代码中,原始订单流来自Kafka,去关联维度表将订单的用户信息取出来。从上面示例中可看到,我们在open()中创建连接对象,在close()方法中关闭连接,在RichAsyncFunction的asyncInvoke()方法中,直接查询数据库操作,并将数据返回出去。这样一个简单异步请求就完成了。
Async I/O的原理和基本用法
简单的来说,使用 Async I/O 对应到 Flink 的 API 就是 RichAsyncFunction 这个抽象类,继层这个抽象类实现里面的open(初始化),asyncInvoke(数据异步调用),close(停止的一些操作)方法,最主要的是实现asyncInvoke 里面的方法。
我们先来看一个使用Async I/O的模板方法:
// This example implements the asynchronous request and callback with Futures that have the
// interface of Java 8's futures (which is the same one followed by Flink's Future)
/**
* An implementation of the 'AsyncFunction' that sends requests and sets the callback.
*/
class AsyncDatabaseRequest extends RichAsyncFunction<String, Tuple2<String, String>> {
/** The database specific client that can issue concurrent requests with callbacks */
private transient DatabaseClient client;
@Override
public void open(Configuration parameters) throws Exception {
client = new DatabaseClient(host, post, credentials);
}
@Override
public void close() throws Exception {
client.close();
}
@Override
public void asyncInvoke(String key, final ResultFuture<Tuple2<String, String>> resultFuture) throws Exception {
// issue the asynchronous request, receive a future for result
final Future<String> result = client.query(key);
// set the callback to be executed once the request by the client is complete
// the callback simply forwards the result to the result future
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
try {
return result.get();
} catch (InterruptedException | ExecutionException e) {
// Normally handled explicitly.
return null;
}
}
}).thenAccept( (String dbResult) -> {
resultFuture.complete(Collections.singleton(new Tuple2<>(key, dbResult)));
});
}
}
// create the original stream
DataStream<String> stream = ...;
// apply the async I/O transformation
DataStream<Tuple2<String, String>> resultStream =
AsyncDataStream.unorderedWait(stream, new AsyncDatabaseRequest(), 1000, TimeUnit.MILLISECONDS, 100);
假设我们一个场景是需要进行异步请求其他数据库,那么要实现一个通过异步I/O来操作数据库还需要三个步骤:
1、实现用来分发请求的AsyncFunction
2、获取操作结果的callback,并将它提交到AsyncCollector中
3、将异步I/O操作转换成DataStream
其中的两个重要的参数:Timeouttimeout 定义了异步操作过了多长时间后会被丢弃,这个参数是防止了死的或者失败的请求
Capacity 这个参数定义了可以同时处理多少个异步请求。虽然异步I/O方法会带来更好的吞吐量,但是算子仍然会成为流应用的瓶颈。超过限制的并发请求数量会产生背压。
几个需要注意的点:
使用Async I/O,需要外部存储有支持异步请求的客户端。
使用Async I/O,继承RichAsyncFunction(接口AsyncFunction<IN, OUT>的抽象类),重写或实现open(建立连接)、close(关闭连接)、asyncInvoke(异步调用)3个方法即可。
使用Async I/O, 最好结合缓存一起使用,可减少请求外部存储的次数,提高效率。
Async I/O 提供了Timeout参数来控制请求最长等待时间。默认,异步I/O请求超时时,会引发异常并重启或停止作业。 如果要处理超时,可以重写AsyncFunction#timeout方法。
Async I/O 提供了Capacity参数控制请求并发数,一旦Capacity被耗尽,会触发反压机制来抑制上游数据的摄入。
Async I/O 输出提供乱序和顺序两种模式。
乱序, 用AsyncDataStream.unorderedWait(...) API,每个并行的输出顺序和输入顺序可能不一致。 顺序, 用AsyncDataStream.orderedWait(...) API,每个并行的输出顺序和输入顺序一致。为保证顺序,需要在输出的Buffer中排序,该方式效率会低一些。
Flink 1.9 的优化
由于新合入的 Blink 相关功能,使得 Flink 1.9 实现维表功能很简单。
如果你要使用该功能,那就需要自己引入 Blink 的 Planner。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
然后我们只要自定义实现 LookupableTableSource 接口,同时实现里面的方法就可以进行,下面来分析一下 LookupableTableSource的代码:
public interface LookupableTableSource<T> extends TableSource<T> {
? ? ?TableFunction<T> getLookupFunction(String[] lookupKeys);
? ? ?AsyncTableFunction<T> getAsyncLookupFunction(String[] lookupKeys);
? ? ?boolean isAsyncEnabled();
}
这三个方法分别是:
isAsyncEnabled 方法主要表示该表是否支持异步访问外部数据源获取数据,当返回 true 时,那么在注册到 TableEnvironment 后,使用时会返回异步函数进行调用,当返回 false 时,则使同步访问函数。
getLookupFunction 方法返回一个同步访问外部数据系统的函数,什么意思呢,就是你通过 Key 去查询外部数据库,需要等到返回数据后才继续处理数据,这会对系统处理的吞吐率有影响。
getAsyncLookupFunction 方法则是返回一个异步的函数,异步访问外部数据系统,获取数据,这能极大的提升系统吞吐率。
我们抛开同步访问函数不管,对于getAsyncLookupFunction会返回异步访问外部数据源的函数,如果你想使用异步函数,前提是 LookupableTableSource 的 isAsyncEnabled 方法返回 true 才能使用。使用异步函数访问外部数据系统,一般是外部系统有异步访问客户端,如果没有的话,可以自己使用线程池异步访问外部系统。例如:
public class MyAsyncLookupFunction extends AsyncTableFunction<Row> {
? ? private transient RedisAsyncCommands<String, String> async;
? ? @Override
? ? public void open(FunctionContext context) throws Exception {
? ? ? ? RedisClient redisClient = RedisClient.create("redis://127.0.0.1:6379");
? ? ? ? StatefulRedisConnection<String, String> connection = redisClient.connect();
? ? ? ? async = connection.async();
? ? }
? ? public void eval(CompletableFuture<Collection<Row>> future, Object... params) {
? ? ? ? redisFuture.thenAccept(new Consumer<String>() {
? ? ? ? ? ? @Override
? ? ? ? ? ? public void accept(String value) {
? ? ? ? ? ? ? ? future.complete(Collections.singletonList(Row.of(key, value)));
? ? ? ? ? ? }
? ? ? ? });
? ? }
}
一个完整的例子如下:
Main方法:
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.typeutils.RowTypeInfo;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.junit.Test;
import java.util.Properties;
public class LookUpAsyncTest {
@Test
public void test() throws Exception {
LookUpAsyncTest.main(new String[]{});
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//env.setParallelism(1);
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
final ParameterTool params = ParameterTool.fromArgs(args);
String fileName = params.get("f");
DataStream<String> source = env.readTextFile("hdfs://172.16.44.28:8020" + fileName, "UTF-8");
TypeInformation[] types = new TypeInformation[]{Types.STRING, Types.STRING, Types.LONG};
String[] fields = new String[]{"id", "user_click", "time"};
RowTypeInfo typeInformation = new RowTypeInfo(types, fields);
DataStream<Row> stream = source.map(new MapFunction<String, Row>() {
private static final long serialVersionUID = 2349572543469673349L;
@Override
public Row map(String s) {
String[] split = s.split(",");
Row row = new Row(split.length);
for (int i = 0; i < split.length; i++) {
Object value = split[i];
if (types[i].equals(Types.STRING)) {
value = split[i];
}
if (types[i].equals(Types.LONG)) {
value = Long.valueOf(split[i]);
}
row.setField(i, value);
}
return row;
}
}).returns(typeInformation);
tableEnv.registerDataStream("user_click_name", stream, String.join(",", typeInformation.getFieldNames()) + ",proctime.proctime");
RedisAsyncLookupTableSource tableSource = RedisAsyncLookupTableSource.Builder.newBuilder()
.withFieldNames(new String[]{"id", "name"})
.withFieldTypes(new TypeInformation[]{Types.STRING, Types.STRING})
.build();
tableEnv.registerTableSource("info", tableSource);
String sql = "select t1.id,t1.user_click,t2.name" +
" from user_click_name as t1" +
" join info FOR SYSTEM_TIME AS OF t1.proctime as t2" +
" on t1.id = t2.id";
Table table = tableEnv.sqlQuery(sql);
DataStream<Row> result = tableEnv.toAppendStream(table, Row.class);
DataStream<String> printStream = result.map(new MapFunction<Row, String>() {
@Override
public String map(Row value) throws Exception {
return value.toString();
}
});
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "127.0.0.1:9094");
FlinkKafkaProducer011<String> kafkaProducer = new FlinkKafkaProducer011<>(
"user_click_name",
new SimpleStringSchema(),
properties);
printStream.addSink(kafkaProducer);
tableEnv.execute(Thread.currentThread().getStackTrace()[1].getClassName());
}
}
RedisAsyncLookupTableSource方法:
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.typeutils.RowTypeInfo;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.TableSchema;
import org.apache.flink.table.functions.AsyncTableFunction;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.table.sources.LookupableTableSource;
import org.apache.flink.table.sources.StreamTableSource;
import org.apache.flink.table.types.DataType;
import org.apache.flink.table.types.utils.TypeConversions;
import org.apache.flink.types.Row;
public class RedisAsyncLookupTableSource implements StreamTableSource<Row>, LookupableTableSource<Row> {
private final String[] fieldNames;
private final TypeInformation[] fieldTypes;
public RedisAsyncLookupTableSource(String[] fieldNames, TypeInformation[] fieldTypes) {
this.fieldNames = fieldNames;
this.fieldTypes = fieldTypes;
}
//同步方法
@Override
public TableFunction<Row> getLookupFunction(String[] strings) {
return null;
}
//异步方法
@Override
public AsyncTableFunction<Row> getAsyncLookupFunction(String[] strings) {
return MyAsyncLookupFunction.Builder.getBuilder()
.withFieldNames(fieldNames)
.withFieldTypes(fieldTypes)
.build();
}
//开启异步
@Override
public boolean isAsyncEnabled() {
return true;
}
@Override
public DataType getProducedDataType() {
return TypeConversions.fromLegacyInfoToDataType(new RowTypeInfo(fieldTypes, fieldNames));
}
@Override
public TableSchema getTableSchema() {
return TableSchema.builder()
.fields(fieldNames, TypeConversions.fromLegacyInfoToDataType(fieldTypes))
.build();
}
@Override
public DataStream<Row> getDataStream(StreamExecutionEnvironment environment) {
throw new UnsupportedOperationException("do not support getDataStream");
}
public static final class Builder {
private String[] fieldNames;
private TypeInformation[] fieldTypes;
private Builder() {
}
public static Builder newBuilder() {
return new Builder();
}
public Builder withFieldNames(String[] fieldNames) {
this.fieldNames = fieldNames;
return this;
}
public Builder withFieldTypes(TypeInformation[] fieldTypes) {
this.fieldTypes = fieldTypes;
return this;
}
public RedisAsyncLookupTableSource build() {
return new RedisAsyncLookupTableSource(fieldNames, fieldTypes);
}
}
}
MyAsyncLookupFunction
import io.lettuce.core.RedisClient;
import io.lettuce.core.RedisFuture;
import io.lettuce.core.api.StatefulRedisConnection;
import io.lettuce.core.api.async.RedisAsyncCommands;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.typeutils.RowTypeInfo;
import org.apache.flink.table.functions.AsyncTableFunction;
import org.apache.flink.table.functions.FunctionContext;
import org.apache.flink.types.Row;
import java.util.Collection;
import java.util.Collections;
import java.util.concurrent.CompletableFuture;
import java.util.function.Consumer;
public class MyAsyncLookupFunction extends AsyncTableFunction<Row> {
private final String[] fieldNames;
private final TypeInformation[] fieldTypes;
private transient RedisAsyncCommands<String, String> async;
public MyAsyncLookupFunction(String[] fieldNames, TypeInformation[] fieldTypes) {
this.fieldNames = fieldNames;
this.fieldTypes = fieldTypes;
}
@Override
public void open(FunctionContext context) {
//配置redis异步连接
RedisClient redisClient = RedisClient.create("redis://127.0.0.1:6379");
StatefulRedisConnection<String, String> connection = redisClient.connect();
async = connection.async();
}
//每一条流数据都会调用此方法进行join
public void eval(CompletableFuture<Collection<Row>> future, Object... paramas) {
//表名、主键名、主键值、列名
String[] info = {"userInfo", "userId", paramas[0].toString(), "userName"};
String key = String.join(":", info);
RedisFuture<String> redisFuture = async.get(key);
redisFuture.thenAccept(new Consumer<String>() {
@Override
public void accept(String value) {
future.complete(Collections.singletonList(Row.of(key, value)));
//todo
// BinaryRow row = new BinaryRow(2);
}
});
}
@Override
public TypeInformation<Row> getResultType() {
return new RowTypeInfo(fieldTypes, fieldNames);
}
public static final class Builder {
private String[] fieldNames;
private TypeInformation[] fieldTypes;
private Builder() {
}
public static Builder getBuilder() {
return new Builder();
}
public Builder withFieldNames(String[] fieldNames) {
this.fieldNames = fieldNames;
return this;
}
public Builder withFieldTypes(TypeInformation[] fieldTypes) {
this.fieldTypes = fieldTypes;
return this;
}
public MyAsyncLookupFunction build() {
return new MyAsyncLookupFunction(fieldNames, fieldTypes);
}
}
}
十分需要注意的几个点:
1、 外部数据源必须是异步客户端:如果是线程安全的(多个客户端一起使用),你可以不加 transient 关键字,初始化一次。否则,你需要加上 transient,不对其进行初始化,而在 open 方法中,为每个 Task 实例初始化一个。
2、eval 方法中多了一个 CompletableFuture,当异步访问完成时,需要调用其方法进行处理。比如上面例子中的:
redisFuture.thenAccept(new Consumer<String>() {
@Override
public void accept(String value) {
future.complete(Collections.singletonList(Row.of(key, value)));
}
});
3、社区虽然提供异步关联维度表的功能,但事实上大数据量下关联外部系统维表仍然会成为系统的瓶颈,所以一般我们会在同步函数和异步函数中加入缓存。综合并发、易用、实时更新和多版本等因素考虑,Hbase是最理想的外部维表。
参考文章:
http://wuchong.me/blog/2017/05/17/flink-internals-async-io/#
https://www.jianshu.com/p/d8f99d94b761
https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=65870673
https://www.jianshu.com/p/7ce84f978ae0
声明:本号所有文章除特殊注明,都为原创,公众号读者拥有优先阅读权,未经作者本人允许不得转载,否则追究侵权责任。
关注我的公众号,后台回复【JAVAPDF】获取200页面试题!
5万人关注的大数据成神之路,不来了解一下吗?
5万人关注的大数据成神之路,真的不来了解一下吗?
5万人关注的大数据成神之路,确定真的不来了解一下吗?
欢迎您关注《大数据成神之路》

以上是关于Flink异步之矛盾-锋利的Async I/O的主要内容,如果未能解决你的问题,请参考以下文章
Flink 原理——异步I/O(asynchronous I/O)
半同步半异步I/O的设计模式(half sync/half async)
oracle启用异步IO(db file async I/O submit)