hive
Posted foremostxl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive相关的知识,希望对你有一定的参考价值。
hive基础
大数据特性与应用
分布式架构概念
Hadoop2.x系统介绍
掌握hive基础建表,以及表格式
了解hive查询
了解正则表达式
1、hive的简介‘’

hive是基于hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类sql的查询功能
hive的本质:
hive本身并不存储任何数据,用hdfs存储数据,用MapReduce计算数据
披着sql外衣的MapReduce ---- sql ---- mapreduce
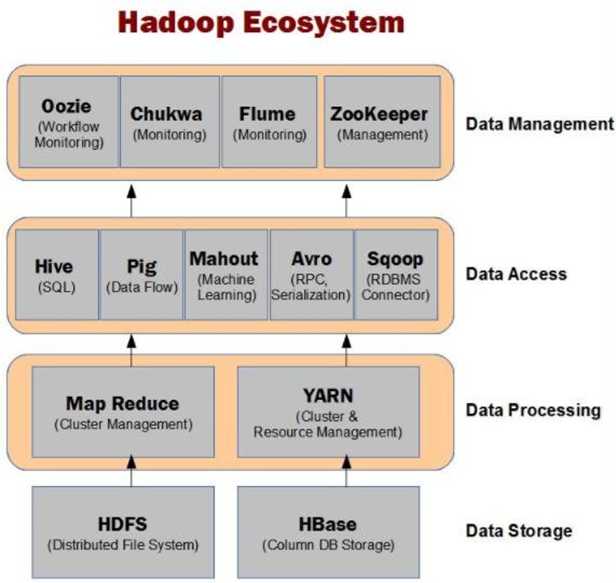
Hive在Hadoop生态体系中
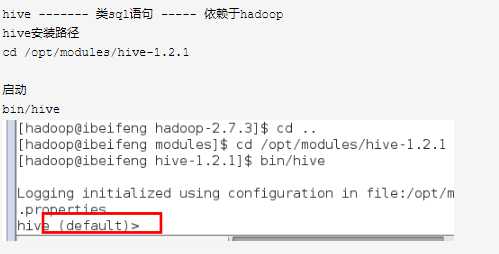
hive ------- 类sql语句 ----- 依赖于hadoop hive安装路径 cd /opt/modules/hive-1.2.1 启动 bin/hive 官网:hive.apache.org
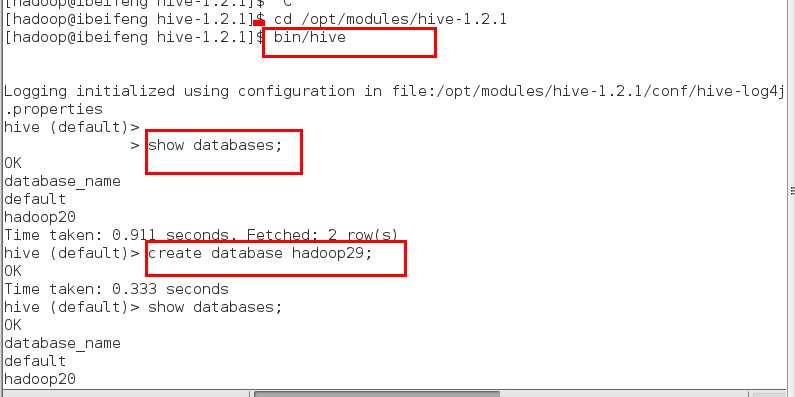
use hadoop29;
desc hadoop29;
先创建数据
vi st.txt,以空格形式展现
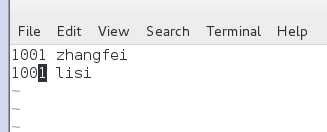
查看表信息
查看表信息:
desc student;
desc formatted student;
加载本地数据:
load data local inpath ‘/home/hadoop/st.txt‘ into table student;
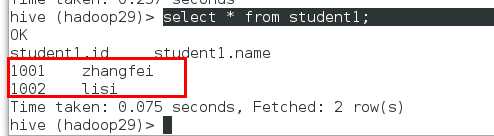
select * from student;
student.id student.name
NULL NULL 解析不到数据
NULL NULL
因为没有按指定的分割符号进行导入数据
重新建立新表格student1
create table student1( id int, name string )row format delimited fields terminated by ‘ ‘;
load data local inpath ‘/home/hadoop/st.txt‘ into table student1; select * from student1;
加载hdfs上数据:
load data inpath ‘hdfs路径‘ into table student;
load data inpath ‘/test29/st.txt‘ into table student1;
bin/hdfs dfs -put /home/hadoop/st.txt /test29
相当于把hdfs上对应数据移动到hdfs对应的表目录中
mysql 写时模式 int --- string
在写入数据时就对数据进行检查
hive 读时模式
在读取数据时才检查数据
drop table student;
exit;
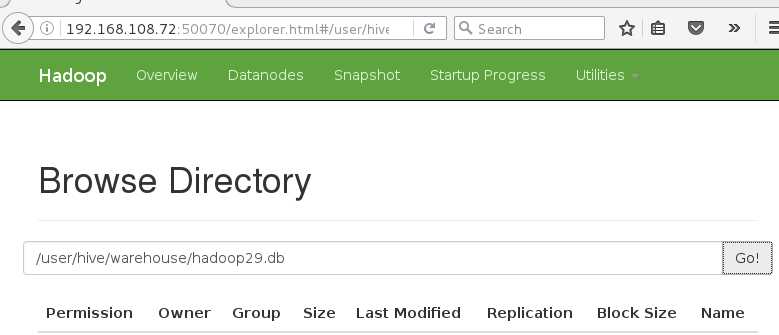
/user/hive/warehouse ----- hive的数据仓库目录
hive作业1
1:hive的本质是什么?
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质是:将HQL转化成MapReduce程序
3:hive查询数据时全部显示为null,是什么原因导致的?
导入数据时的解析不到数据,显示为null 建表 时需要指定列分隔符与导入表格数据之前的分隔符分隔符保持一致 create table student1( id int, name string )row format delimited fields terminated by ‘ ‘;
hive建表方式
common : 基础模块为其他模块提供服务 hdfs: 存储数据管理数据 namenode 主 1 管理元数据信息 datanode 从 多个 存储具体的数据 yarn: 作业调度和资源管理 resourcemanager:管理整个集群的计算资源 主 nodemanager:管理自己所在节点的资源 从 mapreduce : 编程模型 分布式并行计算模型
先启动hadoop再启动hive
启动所有的节点: sbin/start-all.sh 关闭 sbin/stop-all.sh hive 依赖于Hadoop,用hdfs存储数据,用MapReduce计算数据 工具----- 披着sql外衣的MapReduce---- sql----mapreduce计算数据 hive 安装目录:/opt/modules/hive-1.2.1/ 启动: bin/hive
普通创建表方法:
员工编号,员工姓名,职位,上司,入职日期,薪资,奖金,部门编号 create table emp( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int ) row format delimited fields terminated by ‘ ‘;
上传本地文件到linux,使用xhell工具
Windows ------ linux ----- hive(表)----hdfs
load data local inpath ‘/home/hadoop/emp.txt‘ into table emp; 另外一种方法:加载hdfs上的数据: load data inpath ‘hdfs路径‘ into table emp;
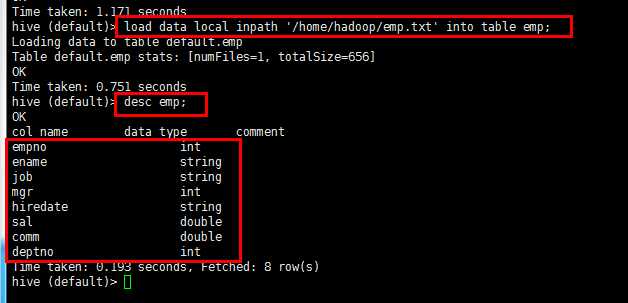
子查询建表方法:
子查询:可以克隆一个表的结构以及表的数据
create table emp_1 as select * from emp;

克隆三列
create table emp_2 as select ename,sal,deptno from emp;
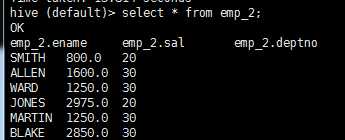
as select 建表方式非常的灵活,做数据清洗的时候,经常会用到
like建表
like: 克隆了表的结构,但是不复制表的数据
create table emp_like like emp;
创建表时 指定位置
create table emp_man( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int ) row format delimited fields terminated by ‘ ‘ location ‘/user/hive/warehouse/hadoop29.db/emp‘;
show tables
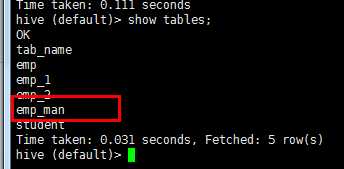
drop table emp_man;
在删除内部表时,会删除表的元数据信息同时删除表所对应的hdfs上的表目录
不利于分享数据
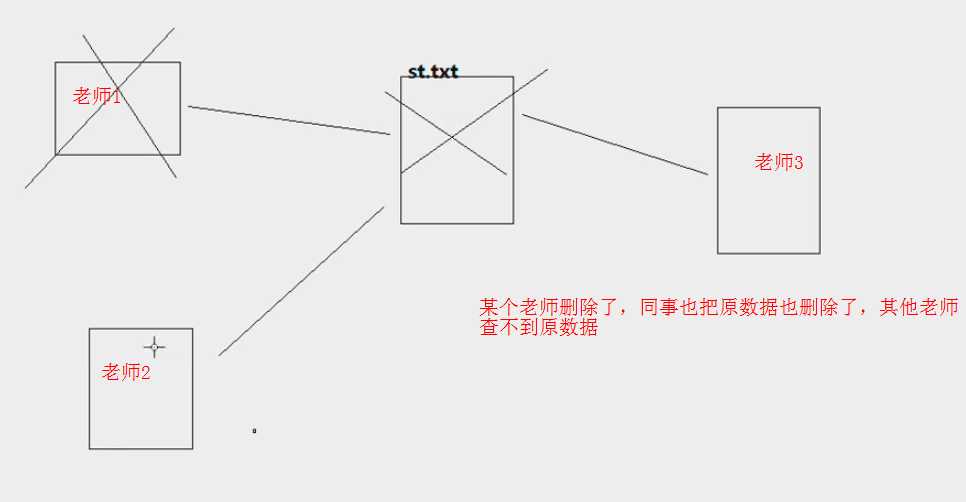
建立外部表
关键字:external
create external table emp_ext(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
row format delimited fields terminated by ‘ ‘
location ‘/user/hive/warehouse/hadoop29.db/emp‘;
desc formatted emp_ext;
Location: hdfs://ibeifeng.com:8020/user/hive/warehouse/hadoop29.db/emp
Table Type: EXTERNAL_TABLE 外部表
drop table emp_ext;
在删除外部表时,只删除表的元数据信息,不会删除hdfs上对应的表目录
利于分享数据,很多情况下都是去关联一个已存在的数据
create external table emp_ext( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int ) row format delimited fields terminated by ‘ ‘; load data local inpath ‘/home/hadoop/emp.txt‘ into table emp_ext; drop table emp_ext;
临时表
临时表:temporary
create temporary table emp_tep( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int ) row format delimited fields terminated by ‘ ‘; load data local inpath ‘/home/hadoop/emp.txt‘ into table emp_tep; desc formatted emp_tep;

Table Type: MANAGED_TABLE 内部表
临时表也是内部表的一种
关闭hive:自动删除临时表的元数据及数据文件
drop table emp_tep; 删除临时表的元数据及数据文件
分区表:关键字partitioned by----也是内部表
hive 表 --- 映射的是hdfs上的一个目录---- 子目录 ---- 子目录
分区表 ----- 分目录

create table emp_part( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int )partitioned by(day string) row format delimited fields terminated by ‘ ‘;
分区:
分区字段:创建表时指定分区字段,不能和普通字段同名,加载数据时指定加载到具体的分区,
分区字段会在hdfs形成目录,在查询时分区字段可以作为普通字段使用
load data local inpath ‘/home/hadoop/emp.txt‘ into table emp_part partition(day=‘20191201‘); load data local inpath ‘/home/hadoop/emp.txt‘ into table emp_part partition(day=‘20191202‘); load data local inpath ‘/home/hadoop/emp.txt‘ into table emp_part partition(day=‘20191203‘);

select * from emp_part; select * from emp_part where day=‘20191201‘;
二级分区:
load data local inpath ‘/home/hadoop/emp.txt‘ into table emp_part22 partition(day=‘20191201‘,hour=‘12‘); load data local inpath ‘/home/hadoop/emp.txt‘ into table emp_part22 partition(day=‘20191201‘,hour=‘13‘); load data local inpath ‘/home/hadoop/emp.txt‘ into table emp_part22 partition(day=‘20191202‘,hour=‘12‘); select * from emp_part22 where day=‘20191201‘ and hour=‘12‘;
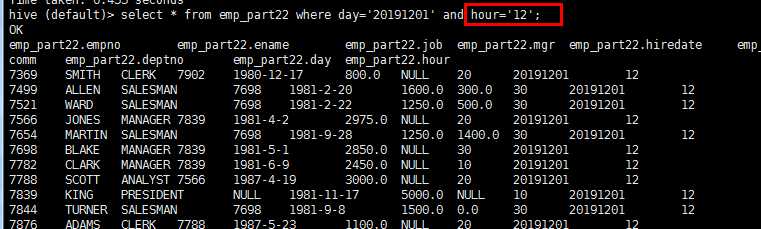
查看分区的信息: show partitions emp_part22; 增加分区: alter table emp_part22 add partition(day=‘20190101‘,hour=‘14‘); load data local inpath ‘/home/hadoop/emp.txt‘ into table emp_part22 partition(day=‘20190101‘,hour=‘14‘); 删除分区: alter table emp_part22 drop partition(day=‘20190101‘,hour=‘14‘);
外部分区表:
create external table emp_part( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int )partitioned by(day string) row format delimited fields terminated by ‘ ‘;
window和linux文件互传
点击xshell,新建文件传输,可以实现

11
以上是关于hive的主要内容,如果未能解决你的问题,请参考以下文章