每日一问2:堆(heap)和栈(stack)的区别
Posted honernan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了每日一问2:堆(heap)和栈(stack)的区别相关的知识,希望对你有一定的参考价值。
因为这里没有明确指出堆是指数据结构还是存储方式,所以两个尝试都回答一下。
一.堆和栈作为数据结构
1.堆(heap),也叫做优先队列(priority queue),队列中允许的操作是先进先出(FIFO),在队尾插入元素,在队头取出元素。而堆也是一样,在堆底插入元素,在堆顶取出元素,但是堆中元素的排列不是按照到来的先后顺序,而是按照一定的优先顺序排列的。这个优先顺序可以是元素的大小或者其他规则。
2.栈(stack),是一种运算受限的线性表,栈中允许的操作时先进后出(FILO),在栈顶插入元素,在栈顶取出元素。另,堆栈连在一起就只指栈,也就是说堆栈指的是栈。
二.堆和栈作为存储方式
1.栈区,指由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数等。在一个进程中,位于用户虚拟地址空间顶部的是用户栈,编译器用它来实现函数的调用。和堆一样,用户栈在程序执行期间可以动态地扩展和收缩。
2.堆区,指由 new 分配而不是编译器自动分配的内存块,由应用程序控制,一般一个 new 就要对应一个 delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。堆可以动态地扩展和收缩。
详细区别:
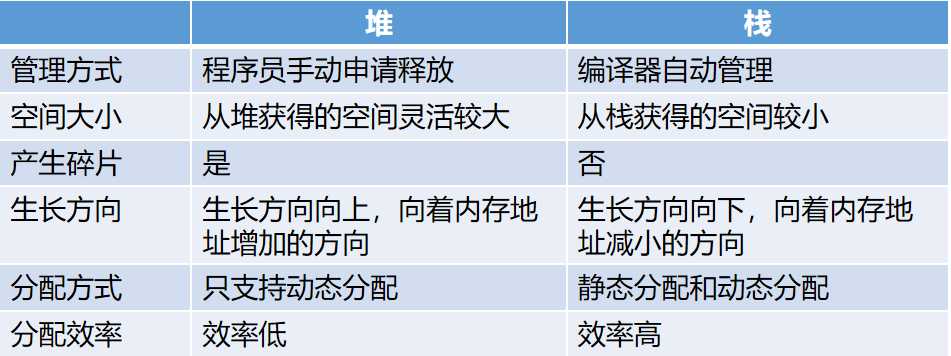
产生这些区别的原因:
生长方向:栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
分配效率:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是 C/C++ 函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。
————————————————
参考博文:https://blog.csdn.net/qq_35637562/article/details/78550953 https://www.cnblogs.com/youxin/p/3313288.html
以上是关于每日一问2:堆(heap)和栈(stack)的区别的主要内容,如果未能解决你的问题,请参考以下文章