(数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
Posted feffery
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(数据科学学习手札72)用pdpipe搭建pandas数据分析流水线相关的知识,希望对你有一定的参考价值。
本文对应脚本及数据已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改正。pdpipe作为专门针对pandas进行流水线化改造的模块,为熟悉pandas的数据分析人员书写优雅易读的代码提供一种简洁的思路,本文就将针对pdpipe的用法进行介绍。
2 pdpipe常用功能介绍
pdpipe的出现极大地对数据分析过程进行规范,其主要拥有以下特性:
- 简洁的语法逻辑
- 在流水线工作过程中可输出规整的提示或错误警报信息
- 轻松串联不同数据操作以组成一条完整流水线
- 轻松处理多种类型数据
- 纯
Python编写,便于二次开发
通过pip install pdpipe安装完成,接下来我们将在jupyter lab中以TMDB 5000 Movie Dataset中的tmdb_5000_movies.csv数据集(图1)为例来介绍pdpipe的主要功能,这是Kaggle上的公开数据集,记录了一些电影的相关属性信息,你也可以在数据科学学习手札系列文章的Github仓库对应本篇文章的路径下直接获取该数据集。

2.1 从一个简单的例子开始
首先在jupyter lab中读入tmdb_5000_movies.csv数据集并查看其前3行(图2):
import pandas as pd
import pdpipe
# 读入tmdb_5000_movies.csv数据集并查看前3行
data = pd.read_csv('tmdb_5000_movies.csv');data.head(3)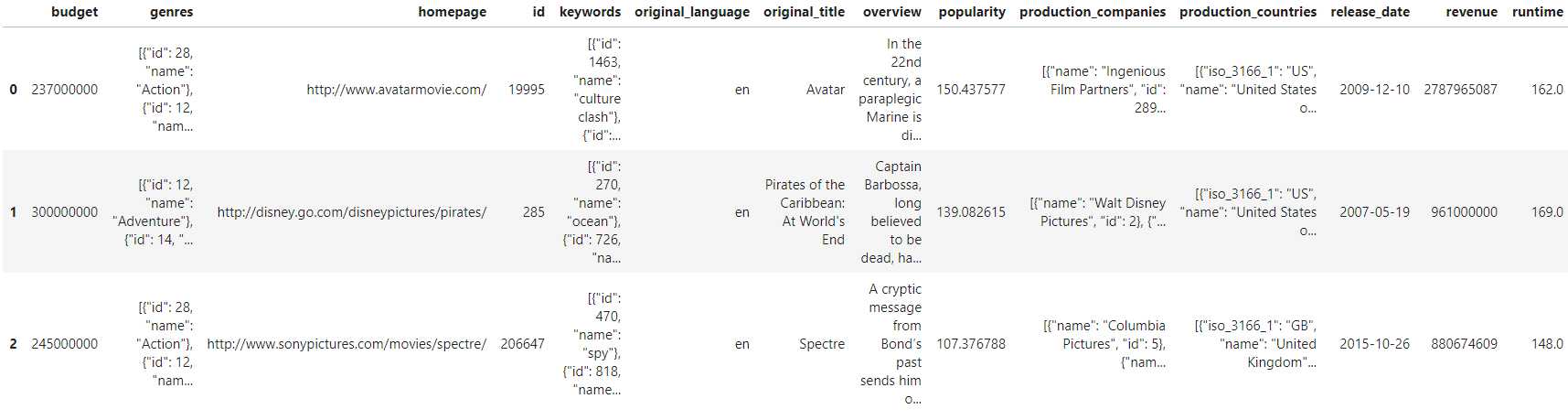
可以看出,数据集包含了数值、日期、文本以及json等多种类型的数据,现在假设我们需要基于此数据完成以下流程:
1、删除original_title列
2、对title列进行小写化处理
3、丢掉vote_average小于等于7,且original_language不为en的行
4、求得genres对应电影类型的数量保存为新列genres_num,并删除原有的genres列
5、丢掉genres_num小于等于5的行
上述操作直接使用pandas并不会花多少时间,但是想要不创造任何中间临时结果一步到位产生所需的数据框子集,并且保持代码的可读性不是一件太容易的事,但是利用pdpipe,我们可以非常优雅地实现上述过程:
# 以pdp.PdPipeline传入流程列表的方式创建pipeline
first_pipeline = pdp.PdPipeline([pdp.ColDrop("original_title"),
pdp.ApplyByCols(columns=['title'], func=lambda x: x.lower()),
pdp.RowDrop({'vote_average': lambda x: x <= 7, 'original_language': lambda x: x != 'en'}),
pdp.ApplyByCols(columns=['genres'], func=lambda x: [item['name'] for item in eval(x)].__len__(), result_columns=['genres_num']),
pdp.RowDrop({'genres_num': lambda x: x <= 5})])
# 将创建的pipeline直接作用于data直接得到所需结果,并打印流程信息
first_pipeline(data, verbose=True).reset_index(drop=True) 得到的结果如图3所示:
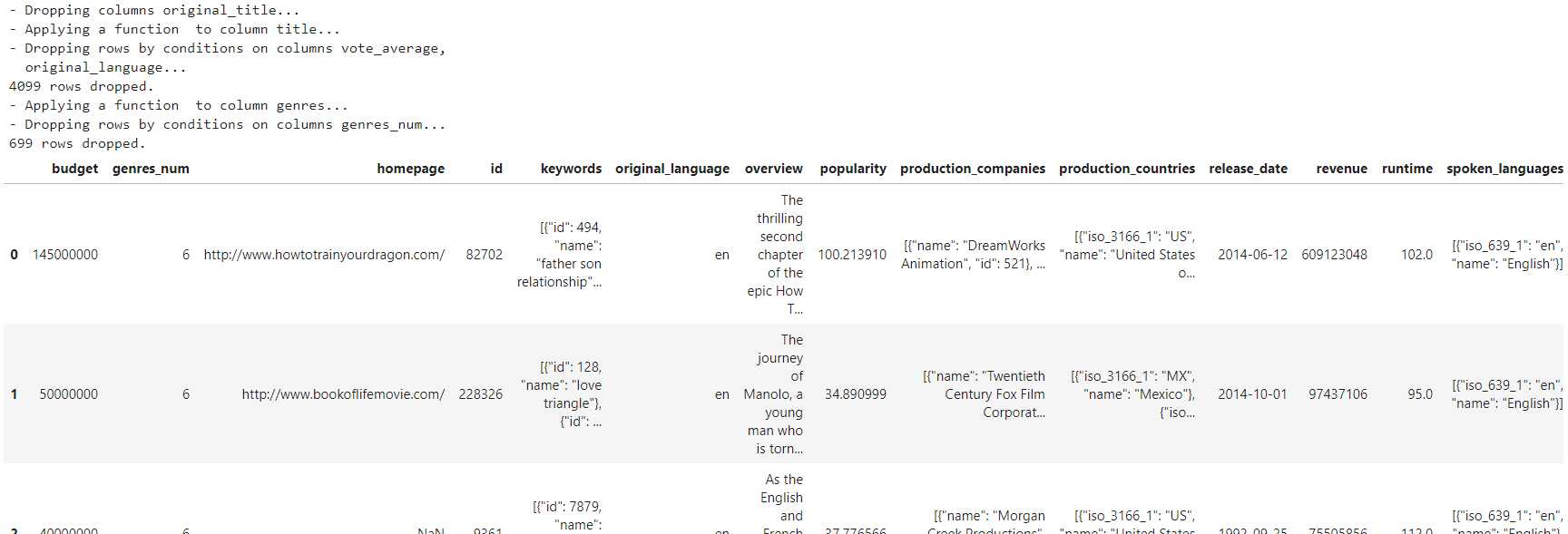
我们不仅保证了代码优雅简洁,可读性强,结果的一步到位,还自动打印出整个流水线运作过程的状态说明!令人兴奋的是
pdpipe充分封装了pandas的核心功能尤其是apply相关操作,使得常规或非常规的数据分析任务都可以利用pdpipe中的API结合自定义函数来优雅地完成,小小领略到pdpipe的妙处之后,下文我们来展开详细介绍。
2.2 pdpipe中的重要子模块
pdpipe中的API按照不同分工被划分到若干子模块,下面将针对常用的几类API展开介绍。
2.2.1 basic_stages
basic_stages中包含了对数据框中的行、列进行丢弃/保留、重命名以及重编码的若干类:
ColDrop:
这个类用于对指定单个或多个列进行丢弃,其主要参数如下:
- columns:字符串或列表,用于指定需要丢弃的列名
- errors:字符串,传入‘ignore‘或‘raise‘,用于指定丢弃指定列时遇到错误采取的应对策略,‘ignore‘表示忽略异常,‘raise‘表示抛出错误打断流水线运作,默认为‘raise‘
下面是举例演示(注意单个流水线部件可以直接传入源数据执行apply方法直接得到结果),我们分别对单列和多列进行删除操作:
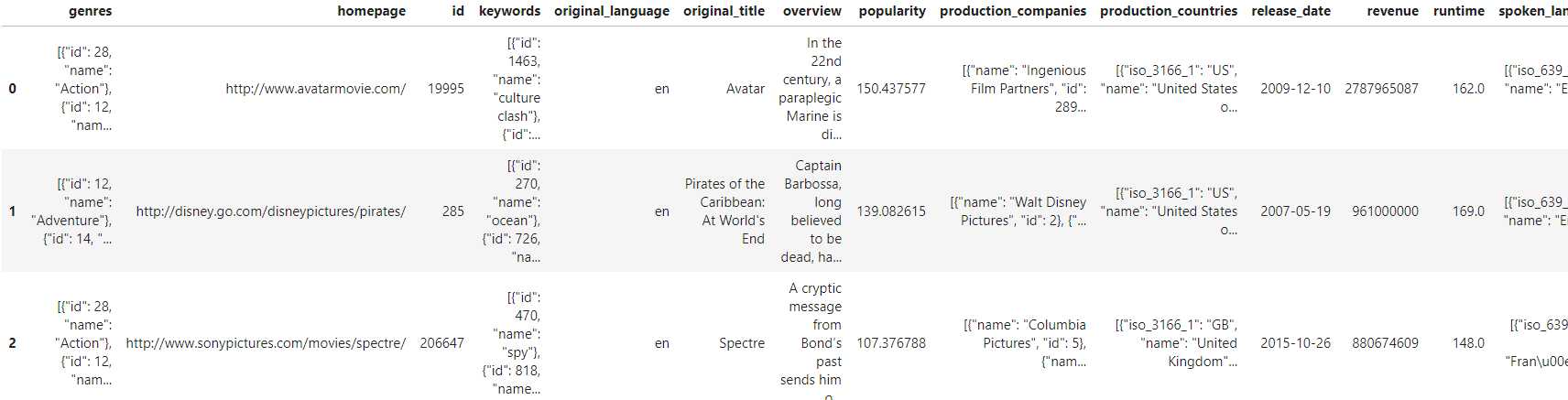
- 单列删除
# 删除budget列
pdp.ColDrop(columns='budget').apply(data).head(3) 删除后得到的结果如图4:
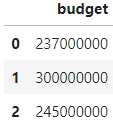
- 多列删除
# 删除budget之外的所有列
del_col = data.columns.tolist()
del_col.remove('budget')
pdp.ColDrop(columns=del_col).apply(data).head(3) 得到的结果中只有budget列被保留,如图5:
ColRename:
这个类用于对指定列名进行重命名,其主要参数如下:
- rename_map:字典,传入旧列名->新列名键值对
下面是举例演示:
- 列重命名
# 将budget重命名为Budget
pdp.ColRename(rename_map={'budget': 'Budget'}).apply(data).head(3) 结果如图6:
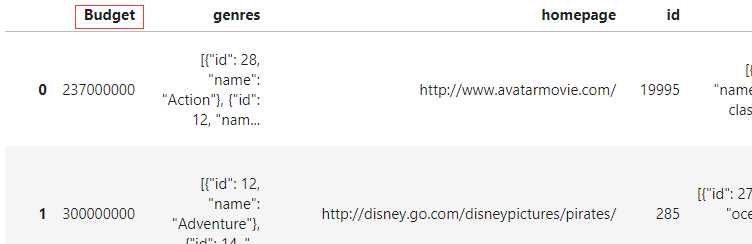
ColReorder:
这个类用于修改列的顺序,其主要参数如下:
- positions:字典,传入列名->新的列下标键值对
下面是举例演示:
- 修改列位置
# 将budget从第0列挪动为第3列
pdp.ColReorder(positions={'budget': 3}).apply(data).head(3) 结果如图7:
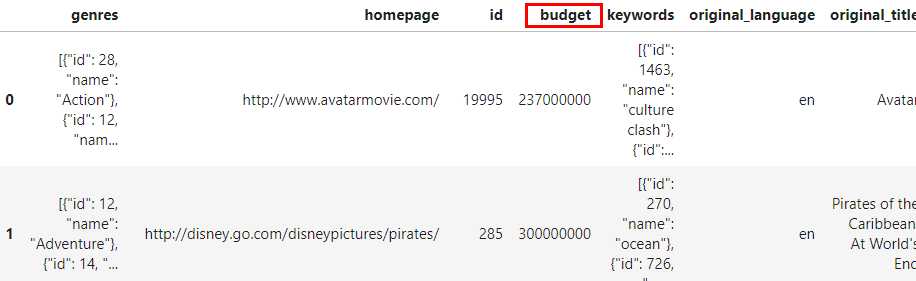
DropNa:
这个类用于丢弃数据中空值元素,其主要参数与pandas中的dropna()保持一致,核心参数如下:
- axis:0或1,0表示删除含有缺失值的行,1表示删除含有缺失值的列
下面是举例演示,首先我们创造一个包含缺失值的数据框:
import numpy as np
# 创造含有缺失值的示例数据
df = pd.DataFrame({'a': [1, 4, 1, 5],
'b': [4, None, np.nan, 7]})
df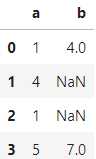
- 删除缺失值所在行
# 删除含有缺失值的行
pdp.DropNa(axis=0).apply(df) 结果如图9:
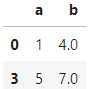
- 删除缺失值所在列
# 删除含有缺失值的列
pdp.DropNa(axis=1).apply(df) 结果如图10:

FreqDrop:
这个类用于删除在指定的一列数据中出现频次小于所给阈值对应的全部行,主要参数如下:
- threshold:int型,传入频次阈值,低于这个阈值的行将会被删除
- column:str型,传入
threshold参数具体作用的列
下面是举例演示,首先我们来查看电影数据集中original_language列对应的频次分布情况:
# 查看original_language频次分布
pd.value_counts(data['original_language'])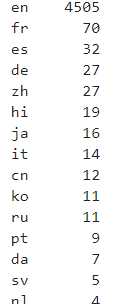
下面我们来过滤删除original_language列出现频次小于10的行:
# 过滤original_language频次低于10的行,再次查看过滤后的数据original_language频次分布
pd.value_counts(pdp.FreqDrop(threshold=10, column='original_language').apply(data)['original_language'])
RowDrop:
这个类用于删除满足指定限制条件的行,主要参数如下:
- conditions:dict型,传入指定列->该列删除条件键值对
- reduce:str型,用于决定多列组合条件下的删除策略,‘any‘相当于条件或,即满足至少一个条件即可删除;‘all‘相当于条件且,即满足全部条件才可删除;‘xor‘相当于条件异或,即当恰恰满足一个条件时才会删除,满足多个或0个都不进行删除。默认为‘any‘
下面是举例演示,我们以budget小于100000000,genres不包含Action,release_date缺失以及vote_count小于1000作为组合删除条件,分别查看在三种不同删除策略下的最终得以保留的数据行数:
- 删除策略:any
pdp.RowDrop(conditions={'budget': lambda x: x <= 100000000,
'genres': lambda x: 'Action' not in x,
'release_date': lambda x: x == np.nan,
'vote_count': lambda x: x <= 1000},
reduce='any').apply(data).shape[0]- 删除策略:all
pdp.RowDrop(conditions={'budget': lambda x: x <= 100000000,
'genres': lambda x: 'Action' not in x,
'release_date': lambda x: x == np.nan,
'vote_count': lambda x: x <= 1000},
reduce='all').apply(data).shape[0]- 删除策略:xor
pdp.RowDrop(conditions={'budget': lambda x: x <= 100000000,
'genres': lambda x: 'Action' not in x,
'release_date': lambda x: x == np.nan,
'vote_count': lambda x: x <= 1000},
reduce='xor').apply(data).shape[0] 对应的结果如下:

2.2.2 col_generation
col_generation中包含了从原数据中产生新列的若干功能:
AggByCols:
这个类用于将指定的函数作用到指定的列上以产生新结果(可以是新的列也可以是一个聚合值),即这时函数真正传入的最小计算对象是列,主要参数如下:
- columns:str或list,用于指定对哪些列进行计算
- func:传入需要计算的函数
- drop:bool型,决定是否在计算完成后把旧列删除,默认为True,即对应列的计算结果直接替换掉对应的旧列
- suffix:str型,控制新列后缀名,当
drop参数设置为False时,结果列的列名变为其对应列+suffix参数指定的后缀名;当drop设置为False时,此参数将不起作用(因为新列直接继承了对应旧列的名称)- result_columns:str或list,与
columns参数一一对应的结果列名称,当你想要自定义结果新列名称时这个参数就变得非常有用,默认为None- func_desc:str型,可选参数,为你的函数添加说明文字,默认为None
下面我们来举例演示帮助理解上述各个参数:
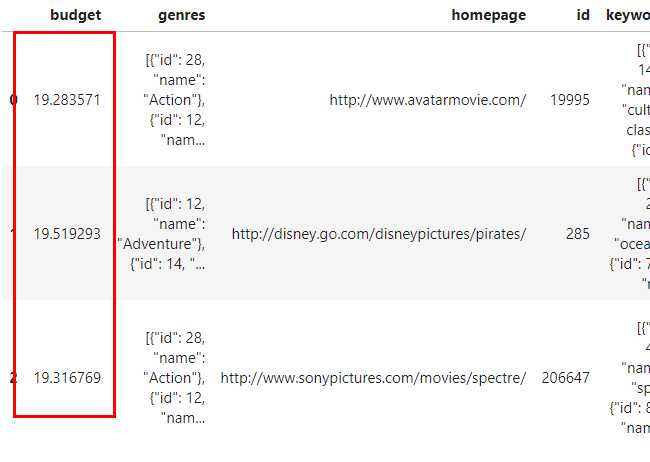
- 针对单个列进行计算
pdp.AggByCols(columns='budget',
func=np.log).apply(data).head(3) 对应的结果如图14,可以看到在只传入columns和func这两个参数,其他参数均为默认值时,对budget列做对数化处理后的新列直接覆盖了原有的budget列:
设置
drop参数为False,并将suffix参数设置为‘_log‘:
# 设置drop参数为False,并将suffix参数设置为'_log'
pdp.AggByCols(columns='budget',
func=np.log,
drop=False,
suffix='_log').apply(data).head(3)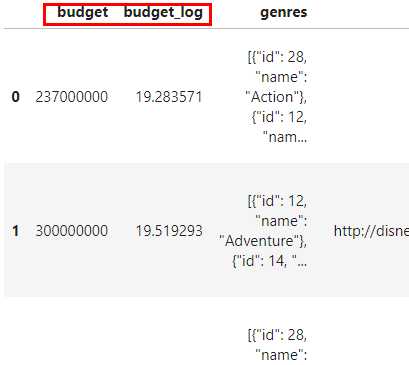
可以看到这时原有列得以保留,新的列以旧列名+后缀名的方式被添加到旧列之后,下面我们修改result_columns参数以自定义结果列名:
# 设置drop参数为False,并将suffix参数设置为'_log'
pdp.AggByCols(columns='budget',
func=np.log,
result_columns='budget(log)').apply(data).head(3)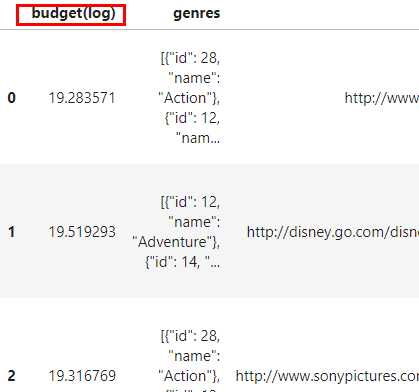
- 针对多个列进行计算
pdp.AggByCols(columns=['budget', 'revenue'],
func=np.log,
drop=False,
suffix='_log').apply(data).head(3)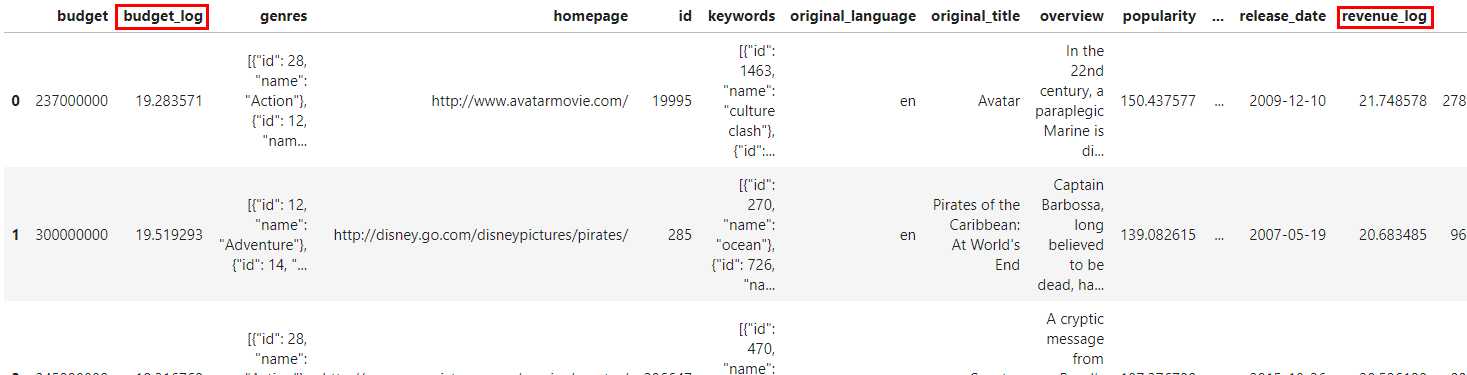
- 计算列的聚合值
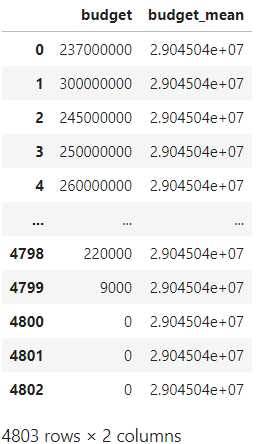
pdp.AggByCols(columns='budget',
func=np.mean, # 这里传入的函数是聚合类型的
drop=False,
suffix='_mean').apply(data).loc[:, ['budget', 'budget_mean']] 这时为了保持整个数据框形状的完整,计算得到的聚合值填充到新列的每一个位置上:
ApplyByCols:
这个类用于实现pandas中对列的apply操作,不同于AggByCols中函数直接处理的是列,ApplyByCols中函数直接处理的是对应列中的每个元素。主要参数如下:
- columns:str或list,用于指定对哪些列进行apply操作
- func:传入需要计算的函数
- drop:bool型,决定是否在计算完成后把旧列删除,默认为True,即对应列的计算结果直接替换掉对应的旧列
- colbl_sfx:str型,控制新列后缀名,当
drop参数设置为False时,结果列的列名变为其对应列+suffix参数指定的后缀名;当drop设置为False时,此参数将不起作用(因为新列直接继承了对应旧列的名称)- result_columns:str或list,与
columns参数一一对应的结果列名称,当你想要自定义结果新列名称时这个参数就变得非常有用,默认为None- func_desc:str型,可选参数,为你的函数添加说明文字,默认为None
下面我们来举例演示帮助理解上述各个参数:
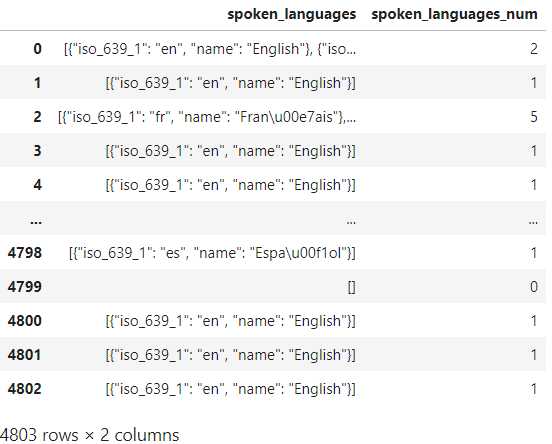
- 求
spoken_languages涉及语言数量
下面的示例对每部电影中涉及的语言语种数量进行计算:
pdp.ApplyByCols(columns='spoken_languages',
func=lambda x: [item['name'] for item in eval(x)].__len__(),
drop=False,
result_columns='spoken_languages_num').apply(data)[['spoken_languages', 'spoken_languages_num']] 对应的结果:
ApplyToRows:
这个类用于实现pandas中对行的apply操作,传入的计算函数直接处理每一行,主要参数如下:
- func:传入需要计算的函数,对每一行进行处理
- colname:str型,用于定义结果列的名称(因为
ApplyToRows作用的对象是一整行,因此只能形成一列返回值),默认为‘new_col‘- follow_column:str型,控制结果列插入到指定列名之后,默认为None,即放到最后一列
- func_desc:str型,可选参数,为你的函数添加说明文字,默认为None
下面我们来举例演示帮助理解上述各个参数:
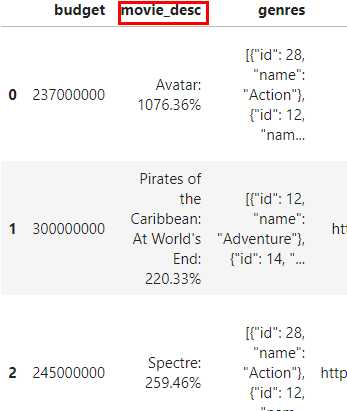
- 得到对应电影的盈利简报
pdp.ApplyToRows(func=lambda row: f"{row['original_title']}: {round(((row['revenue'] / row['budget'] -1)*100), 2)}%" if row['budget'] != 0
else f"{row['original_title']}: 因成本为0故不进行计算",
colname='movie_desc',
follow_column='budget',
func_desc='输出对应电影的盈利百分比').apply(data).head(3) 对应的结果:
Bin:
这个类用于对连续型数据进行分箱,主要参数如下:
- bin_map:字典型,传入列名->分界点列表
- drop:bool型,决定是否在计算完成后把旧列删除,默认为True,即对应列的计算结果直接替换掉对应的旧列
下面我们以计算电影盈利率小于0,大于0小于100%以及大于100%作为三个分箱区间,首先我们用到上文介绍过的RowDrop丢掉那些成本或利润为0的行,再用ApplyToRows来计算盈利率,最终使用Bin进行分箱:
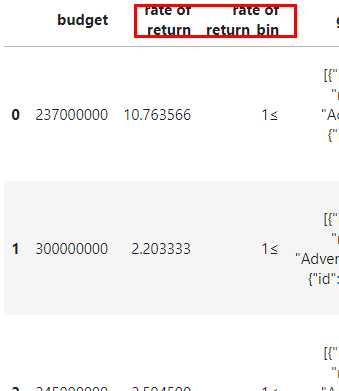
- 为电影盈利率进行数据分箱
pipeline = pdp.PdPipeline([pdp.RowDrop(conditions={'budget': lambda x: x == 0,
'revenue': lambda x: x == 0},
reduce='any'),
pdp.ApplyToRows(func=lambda row: row['revenue'] / row['budget'] - 1,
colname='rate of return',
follow_column='budget'),
pdp.Bin(bin_map={'rate of return': [0, 1]}, drop=False)])
pipeline(data).head(3) 对应的结果:
OneHotEncode:
这个类用于为类别型变量创建哑变量(即独热处理),效果等价于pandas中的get_dummies,主要参数如下:
- columns:str或list,用于指定需要进行哑变量处理的列名,默认为None,即对全部类别型变量进行哑变量处理
- dummy_na:bool型,决定是否将缺失值也作为哑变量的一个类别进行输出,默认为False即忽略缺失值
- exclude_columns:list,当
columns参数设置为None时,这个参数传入的列名列表中指定的列将不进行哑变量处理,默认为None,即不对任何列进行排除- drop_first:bool型或str型,默认为True,这个参数是针对哑变量中类似这样的情况:譬如有类别型变量性别{男性,女性},那么实际上只需要产生一列0-1型哑变量即可表示原始变量的信息,即性别{男性,女性}->男性{0,1},0代表不为男性即女性,1相反,而
drop_dirst设置为False时,原始变量有几个类别就对应几个哑变量被创造;当设置为指定类别值时(譬如设置drop_first = ‘男性‘),这个值对应的类别将不进行哑变量生成- drop:bool型,控制是否在生成哑变量之后删除原始的类别型变量,默认为True即删除
下面我们伪造包含哑变量的数据框:
# 伪造的数据框
df = pd.DataFrame({
'a': ['x', 'y', 'z'],
'b': ['i', 'j', 'q']
})
df
默认参数下执行OneHotEncode:
pdp.OneHotEncode().apply(df)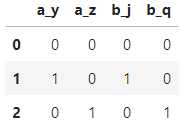
设置drop_first为False:
pdp.OneHotEncode(drop_first=False).apply(df)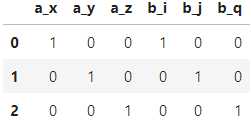
2.2.3 text_stages
text_stages中包含了对数据框中文本型变量进行处理的若干类,下文只介绍其中我认为最有用的:
RegexReplace:
这个类用于对文本型列进行基于正则表达式的内容替换,其主要参数如下:
- columns:str型或list型,传入要进行替换的单个或多个列名
- pattern:str,传入匹配替换内容的正则表达式
- replace:str,传入替换后的新字符串
- result_columns:str或list,与
columns参数一一对应的结果列名称,当你想要自定义结果新列名称时这个参数就变得非常有用,默认为None,即直接替换原始列- drop:bool型,用于决定是否删除替换前的原始列,默认为True,即删除原始列
下面是举例演示:
- 替换original_language中的‘en‘或‘cn‘为‘英文/中文‘
pdp.RegexReplace(columns='original_language',
pattern='en|cn',
replace='英文/中文').apply(data)['original_language'].unique() 结果如图24:

2.3 组装pipeline的几种方式
上文中我们主要演示了单一pipeline部件工作时的细节,接下来我们来了解pdpipe中组装pipeline的几种方式:
2.3.1 PdPipeline
这是我们在2.1中举例说明使用到的创建pipeline的方法,直接传入由按顺序的pipeline组件组成的列表便可生成所需pipeline,而除了直接将其视为函数直接传入原始数据和一些辅助参数(如verbose控制是否打印过程)之外,还可以用类似scikit-learn中的fit_transform方法:
# 调用pipeline的fit_transform方法作用于data直接得到所需结果,并打印流程信息
first_pipeline.fit_transform(data, verbose=1)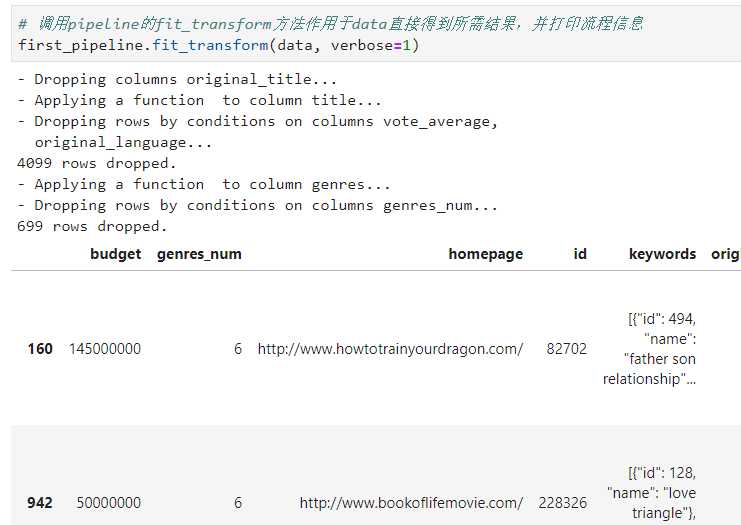
2.3.2 make_pdpipeline
与PdpPipeline相似,make_pdpipeline不可以传入pipeline组件形成的列表,只能把每个pipeline组件当成位置参数按顺序传入:
# 以make_pdpipeline将pipeline组件作为位置参数传入的方式创建pipeline
first_pipeline1 = pdp.make_pdpipeline(pdp.ColDrop("original_title"),
pdp.ApplyByCols(columns=['title'], func=lambda x: x.lower()),
pdp.RowDrop({'vote_average': lambda x: x <= 7, 'original_language': lambda x: x != 'en'}),
pdp.ApplyByCols(columns=['genres'], func=lambda x: [item['name'] for item in eval(x)].__len__(), result_columns=['genres_num']),
pdp.RowDrop({'genres_num': lambda x: x <= 5}))
# 以pdp.PdPipeline传入流程列表的方式创建pipeline
first_pipeline2 = pdp.PdPipeline([pdp.ColDrop("original_title"),
pdp.ApplyByCols(columns=['title'], func=lambda x: x.lower()),
pdp.RowDrop({'vote_average': lambda x: x <= 7, 'original_language': lambda x: x != 'en'}),
pdp.ApplyByCols(columns=['genres'], func=lambda x: [item['name'] for item in eval(x)].__len__(), result_columns=['genres_num']),
pdp.RowDrop({'genres_num': lambda x: x <= 5})])
# 比较两种不同方式创建的pipeline产生结果是否相同
first_pipeline1.fit_transform(data) == first_pipeline2(data) 比较结果如图26,两种方式殊途同归:

以上就是本文全部内容,如有笔误望指出!
参考资料:
https://pdpipe.github.io/pdpipe/doc/pdpipe/
https://tirthajyoti.github.io/Notebooks/Pandas-pipeline-with-pdpipe
以上是关于(数据科学学习手札72)用pdpipe搭建pandas数据分析流水线的主要内容,如果未能解决你的问题,请参考以下文章