神经网络-前向算法
Posted chenjieyouge
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络-前向算法相关的知识,希望对你有一定的参考价值。
神经网络-前向算法
直观来看一波, 神经网络是咋样的.
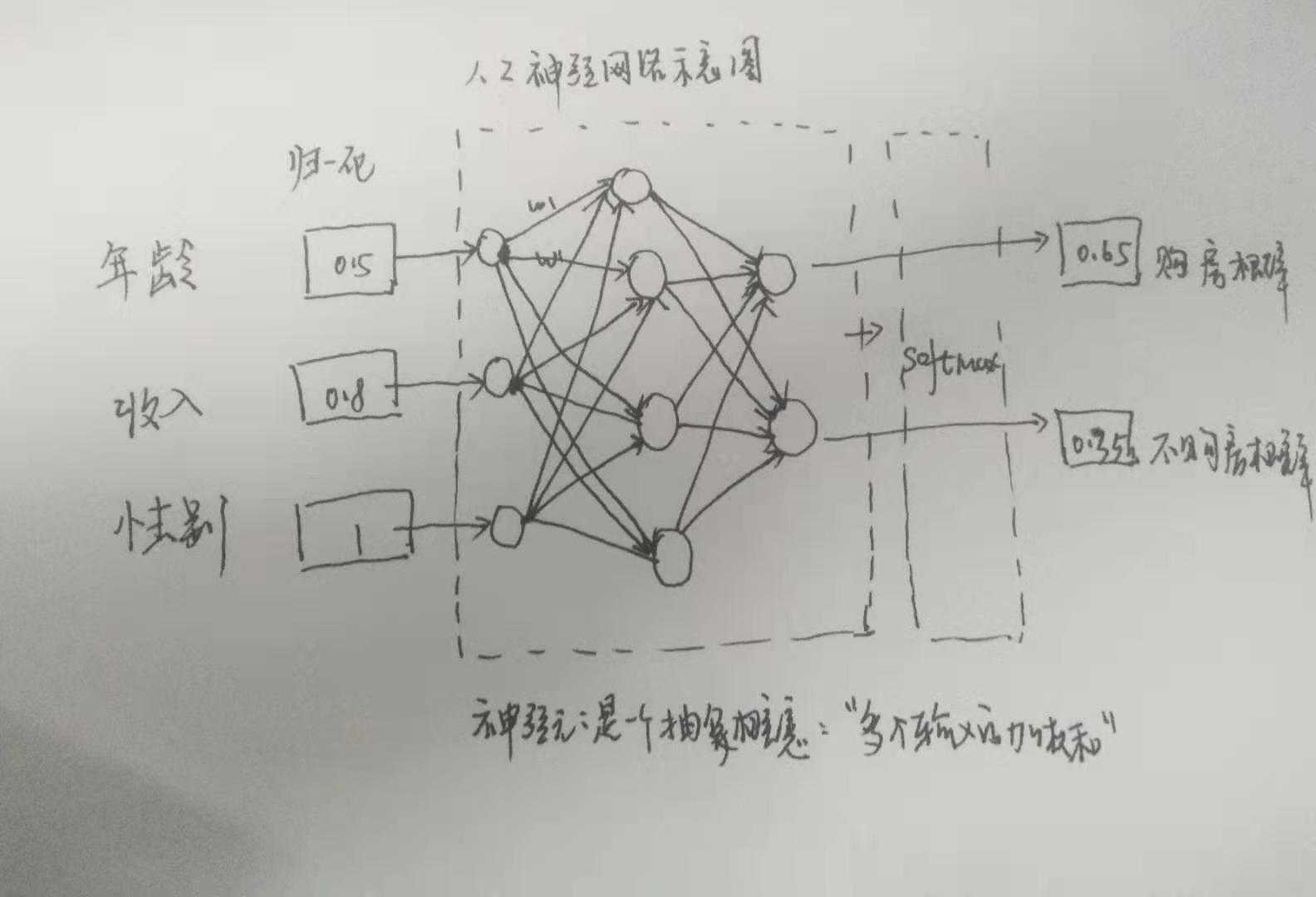
- 多个输入: 首先进行归一化
神经元: 是一个抽象出来的概念, 多个输入的加权和
- 中间是各神经元, 以"层"的方式的 "映射"
输出了一个概率(向量)
前向算法
我们首先好奇的就是, 输入 --> 到输出是如何计算的, 看一波最简单的网络3层结构.
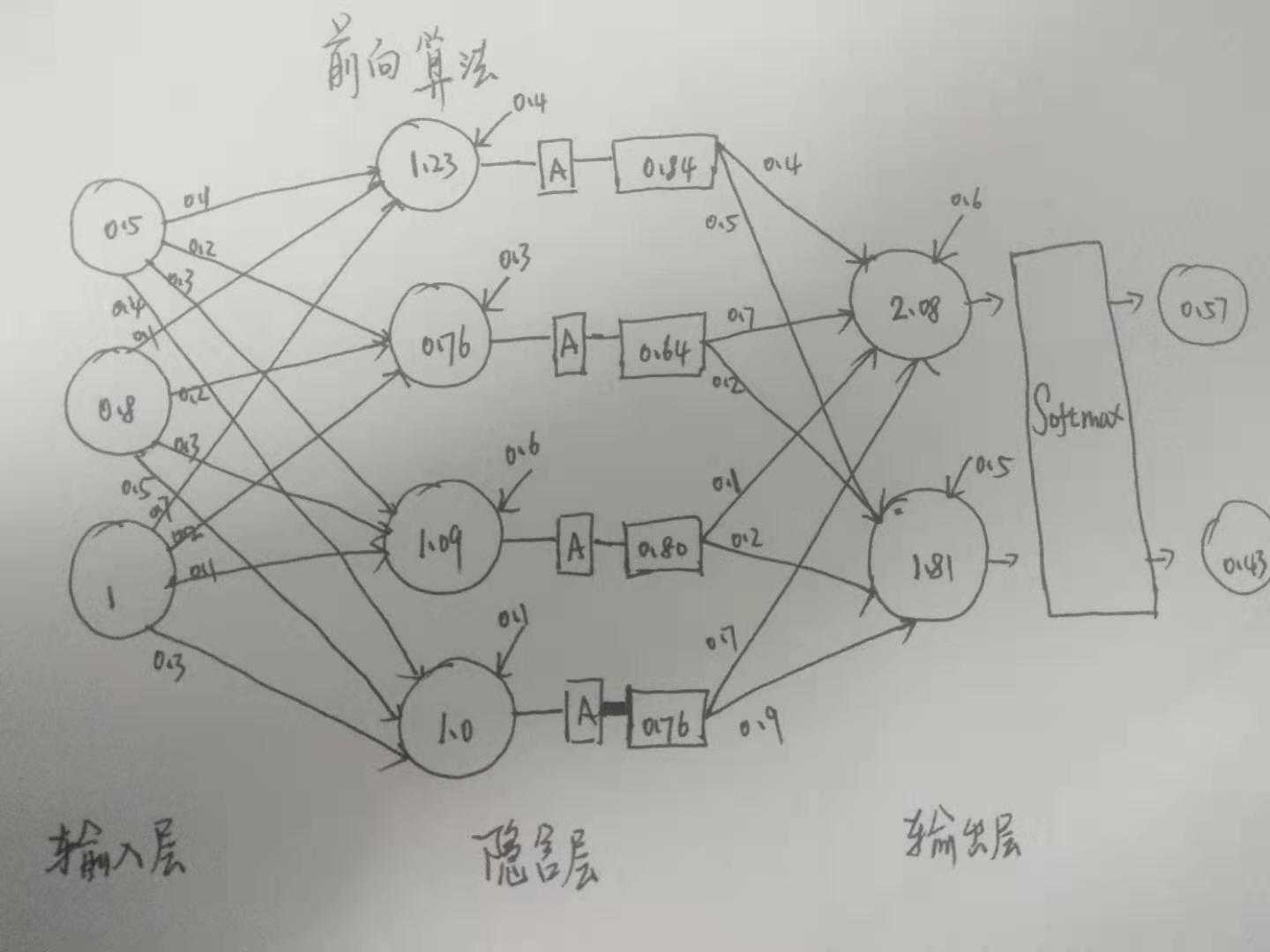
- 输入层: 即看到最左边的3个输入节点
- 线条: 权值, 图中的每根线条代表一个权值
隐含层: 输入节点的加权和(各节点) + 偏置(bias)
A: 激活函数( Activation Function), 常用的有 ‘S‘型函数, 如 logic, tanh 等.
Softmax: 是一类函数统称, 将输出值映射为0-1之间
输出层: 最后输出的一个向量, 每个分量的值之和为1
Tips:
隐含层可以多层; 偏置项 bias 是为了防止节点是 0的情况
激活函数: f(x) -> 0 -1 之间 将一个实值映射到 0-1之间
Softmat: f([x1, x2, x3]) -> [0.5, 0.3, 0.2] 将一个向量, "归一化" 的感觉
如何计算隐含层节点的值? 以1.23为例
((1.23 = 0.5*0.1 + 0.8*0.1 + 1*0.7) + 0.4 = 1.23)
1.23 -> 激活函数(1.23) -> 0.84
....
可以看出, 隐含层的第一个节点的值, 为前一层的所有节点的值的加权和, 再加上偏置
然后再通过激活函数, 然后... 最后再通过一个 Softmax 输出一个概率概率向量.
Activation Function 激活函数
作用: 将一个实数, 映射到 0-1 之间
比如常见的 双曲正切函数 tanh x
(tanh x = frac {sinh x}{cosh x} = frac {e^{x} - e^{-x}} {e^{x} +e^{-x}} = frac {e^{2x-1}} {e^{2x+1}})
>>> import math
>>> import numpy as np
>>> math.tanh(1.145)
0.8160909001379913
>>> np.tanh([1.66, -1.66])
array([ 0.93021718, -0.93021718])
>>> np.tanh([0.88, 1.23, 6.14, 10])
array([0.70641932, 0.84257933, 0.99999071, 1.000...])感觉这玩意, 映射得有点猛, x 在 [-2, 2] 之间有点 "s"的波动, 超过 2就基本接近于 1了, 变化非常平缓. 像上边图中的 1.23的节点, 可以经过激活函数, 即 (tanh (1.23) = 0.84)... 以此类推.
隐含层节点, 通过激活函数的映射, 得到隐含层的输出节点. 这些节点跟 输出层的节点, 也是有 "连接, 线条(权重)"的关系的. 跟前面计算隐含层的节点是一样的计算方式.
图中2.08 是如何计算的
((0.84 * 0.5 + 0.64 * 0.7 + 0.8 * 0.1 + 0.76 * 0.7) + 0.6 = 2.08)
1.81 也是同样的算法
然后, 我们的目标, 是想输出一个概率值, 这里假设, 我们是一个分类问题
即如何将输出层的节点 ([2.08, 1.81]) 变得像一个概率分布呢? 最常用的一种方式就是 Softmax. 这也是目前, 被应用得最多的方式.
Softmax 归一化指数函数
作用: f([1,2,3]) -> [0.2, 0.3, 0. 5], 即将输入向量, 归一化为一个概率分布, 写严格一点就是:
(sigma: R^k ightarrow { z in R^k | z_i > 0, sum limits_{i=1}^k z_i = 1})
其中对于向量的一个分量:
(sigma(x)_i = frac {e^{x_i}} {sum limits_{i=1}^k e^{x_i}})
import numpy as np
def softmax(arr):
"""向量指数归一化输出"""
return np.exp(arr) / np.sum(np.exp(arr))
>>> softmax([1, 3, 5])
array([0.01587624, 0.11731043, 0.86681333])Softmax 的 Overflow (溢出)
>>> softmax([100, 200, 300])
array([1.38389653e-87, 3.72007598e-44, 1.00000000e+00])
>>> softmax([1000, 2000, 3000]
... )
__main__:3: RuntimeWarning: overflow encountered in exp
__main__:3: RuntimeWarning: invalid value encountered in true_divide
array([nan, nan, nan])
>>> softmax([1000, 2000, 3000])
array([nan, nan, nan])就会发现, 数学推导和写代码实现, 根本就是两码事. 推导是非常完美和直观的, 但写成代码一跑, 当值一大的话, 就overflow 了. 为啥呢, 因为, 计算机存储值是有 "精度" 的呀. 因此, 为了避免这种 bug, 从数学上, 将每个值 减去 该向量中的最大值 即可.
(frac {e^{x_i}} {sum limits_{i=1}^k e^{x_i}} = frac {e^{x_i}} {sum limits_{i=1}^k e^{x_i}} frac {e^{-m}}{e^{-m}} = frac {e^{x_i-m}} {sum limits_{i=1}^k e^{x_i-m}})
def softmax(arr):
"""向量指数归一化输出"""
m = np.max(arr)
return np.exp(arr - m) / np.sum(np.exp(arr - m))
# test
>>> softmax([3,4,5])
array([0.09003057, 0.24472847, 0.66524096])
>>> softmax([1000, 2000, 3000])
array([0., 0., 1.]) 把上图的 输出层节点 -> Softmax 得到了一个概率分布.
>>> softmax([2.08, 1.81])
array([0.5670929, 0.4329071])
>>>即对于这样一个分类问题, 这个神经网络完成了:
- 输入特征: [年龄, 收入, 性别] -> [ 0.5, 0.8, 1]
- 输出概率: [ 买房, 不买房] -> [0.57, 0.43]
我的感觉是, 此处, 训练了网络结构的复杂函数, f, 完成了 (R^{3} ightarrow R^{2}) 的一个非线性映射
小结
这个例子, 其实就是一个比较完整的 神经网络前向算法. 当然, 这里有个假设, 每个权值在已知的情况下.
首先, 有一个网络结构, 需要定义, 输入层有几个节点, 输出有几个节点,
然后, 每个隐含层, 有对应的偏置 bias, (为了防止输出为零的情况, 类似之前朴素贝叶斯中的平滑参数是一样的). 还有一个激活函数的选择, Softmax 的选择等.
接着, 要确定, 每个节点间的 "权值线条", 隐含层 到输出层的 "权值线条" 假设这些权值是已经训练好了的话,
最后, 给定一个输入, 则沿着网络结构, 往前走, 最后就输出了呀.
so, 现在的问题是, 如何通过样本来训练这些权值线条, 这就要用到 BP算法, 即咱常说的 误差向后传递. 下篇再整.
以上是关于神经网络-前向算法的主要内容,如果未能解决你的问题,请参考以下文章