Executors框架二 ScheduledThreadPoolExecutor线程池
Posted xieyanke
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Executors框架二 ScheduledThreadPoolExecutor线程池相关的知识,希望对你有一定的参考价值。
用途:
ScheduledThreadPoolExecutor(计划任务线程池)主要用于执行一些需要延时操作或者需要重复操作的任务, Spring框架自带计划任务功能
场景一: 延时操作, 提供给客户统计数据功能, 如果高峰执行肯定影响系统运行效率,那么规定只有下午四点以后才能执行统计, 那么就需要用户提交统计任务, 系统待四点以后排队统计用户提交的任务, 用户可以查询任务列表查看此查询任务是否已经完成
场景二: 重复操作, 一般使用在后台管理系统, 提交重复操作的任务, 比如操作人提交一个定时向用户发消息的任务, 此后每隔一段时间向用户发送消息
方法解释:
//提交延时计划任务 ScheduledFuture<?> schedule(Runnable command /*任务体 无返回*/, long delay/*延时时间*/, TimeUnit unit/*延时时间单位*/); //提交延时计划任务 ScheduledFuture<V> schedule(Callable<V> callable/*任务体 有返回*/, long delay/*延时时间*/, TimeUnit unit/*延时时间单位*/); //提交一个延时后的周期操作任务, 需要注意的是若操作时间长于周期时间, //则周期操作会等上一次操作结束之后立即执行, 不会出现上一次未执行完,本次操作到了周期时间开始执行的现象 //并且任务一旦提交后将一直重复执行下去, 除非线程池关闭或者任务抛出异常(抛出异常后续重复操作将不会继续) ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay /*首次延时时间*/, long period /*周期频率*/, TimeUnit unit); //提交一个延时后的周期操作任务, 需要注意的是若操作时间长于周期时间, //则周期操作会等上一次操作结束之后延时执行, 不会出现上一次未执行完,本次操作到了周期时间开始执行的现象 //并且任务一旦提交后将一直重复执行下去, 除非线程池关闭或者任务抛出异常(抛出异常后续重复操作将不会继续) ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay /*首次延时时间*/, long delay /*第一次之后延时时间*/, TimeUnit unit);
使用举例:
ScheduledFuture<?> schedule(Runnable command /*任务体 无返回*/, long delay/*延时时间*/, TimeUnit unit)
public static void main(String[] args/*任务*/) throws Exception { long startTime = new Date().getTime(); ScheduledExecutorService scheduledExecutorService = new ScheduledThreadPoolExecutor(10); scheduledExecutorService.schedule(()->{ try { Thread.sleep(2000L); System.out.println("与启动时相差:"+(new Date().getTime()-startTime)/1000+"秒"); } catch (InterruptedException e) { e.printStackTrace(); } }, 3000 /*延时3秒后首次执行*/, TimeUnit.MILLISECONDS); scheduledExecutorService.schedule(()->{ try { Thread.sleep(4000L); System.out.println("与启动时相差:"+(new Date().getTime()-startTime)/1000+"秒"); } catch (InterruptedException e) { e.printStackTrace(); } }, 3000 /*延时3秒后首次执行*/, TimeUnit.MILLISECONDS); } 结果: 与启动时相差:5秒 与启动时相差:7秒
ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay /*首次延时时间*/, long period /*周期频率*/, TimeUnit unit)
public static void main(String[] args/*任务*/) throws Exception { //当前时间毫秒数 final Long millisecondsNow = new Date().getTime(); //执行次数 final AtomicInteger n = new AtomicInteger(0); ScheduledExecutorService scheduledExecutorService = new ScheduledThreadPoolExecutor(10); scheduledExecutorService.scheduleAtFixedRate(()->{ //计数加1 n.incrementAndGet(); //第四次抛出异常 用于测试抛出异常后不再重复操作 if (n.get()==4){ int a=0; System.out.println(1/a); } //测试执行时间 try { System.out.println("第"+n+"次打印 与启动时相差:"+(new Date().getTime()-millisecondsNow)/1000+"秒"); //睡眠相当于业务执行时间3秒 Thread.sleep(3000L); } catch (InterruptedException e) { e.printStackTrace(); } }, 3000 /*延时3秒后首次执行*/, 1000 /*任务间隔1秒*/, TimeUnit.MILLISECONDS); } 结果: 第1次打印 与启动时相差:3秒 第2次打印 与启动时相差:6秒 第3次打印 与启动时相差:9秒
从上面结果可以看出
1 每次执行结果都是相差3秒, 说明任务间隔时间若小于执行时间, 则每次执行完立即执行下一次任务
2 不会出现前后两次并发的情景出现
3 第四次抛出异常后不再继续执行任务
ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay /*首次延时时间*/, long delay /*第一次之后延时时间*/, TimeUnit unit);
public static void main(String[] args/*任务*/) throws Exception { //当前时间毫秒数 final Long millisecondsNow = new Date().getTime(); //执行次数 final AtomicInteger n = new AtomicInteger(0); ScheduledExecutorService scheduledExecutorService = new ScheduledThreadPoolExecutor(10); scheduledExecutorService.scheduleWithFixedDelay(()->{ //计数加1 n.incrementAndGet(); //第四次抛出异常 用于测试抛出异常后不再重复操作 if (n.get()==4){ int a=0; System.out.println(1/a); } //测试执行时间 try { System.out.println("第"+n+"次打印 与启动时相差:"+(new Date().getTime()-millisecondsNow)/1000+"秒"); //睡眠相当于业务执行时间4秒 Thread.sleep(4000L); } catch (InterruptedException e) { e.printStackTrace(); } }, 3000 /*延时3秒后首次执行*/, 1000 /*任务间隔1秒*/, TimeUnit.MILLISECONDS); } 结果: 第1次打印 与启动时相差:3秒 第2次打印 与启动时相差:8秒 第3次打印 与启动时相差:13秒
从上面结果可以看出
1 时间间隔为4秒,时间差等于 任务间隔时间(1秒)+任务处理时间(4秒)
2 不会出现前后两次并发的情景出现
3 第四次抛出异常后不再继续执行任务
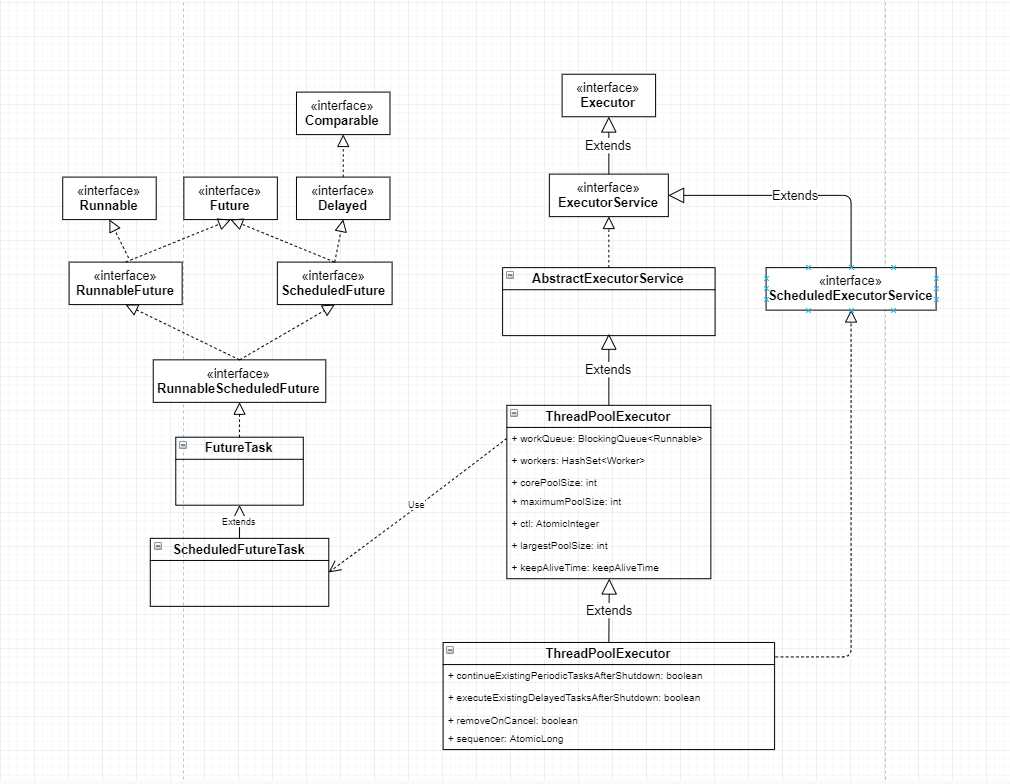
类图:
从类图中可以分析出队列关注的是Runnable接口,也即具体执行任务是什么, ScheduledFutureTask实现了多个接口, 实际关心者是持有者例: RunnableFuture<T> ftask = newTaskFor(task, result)
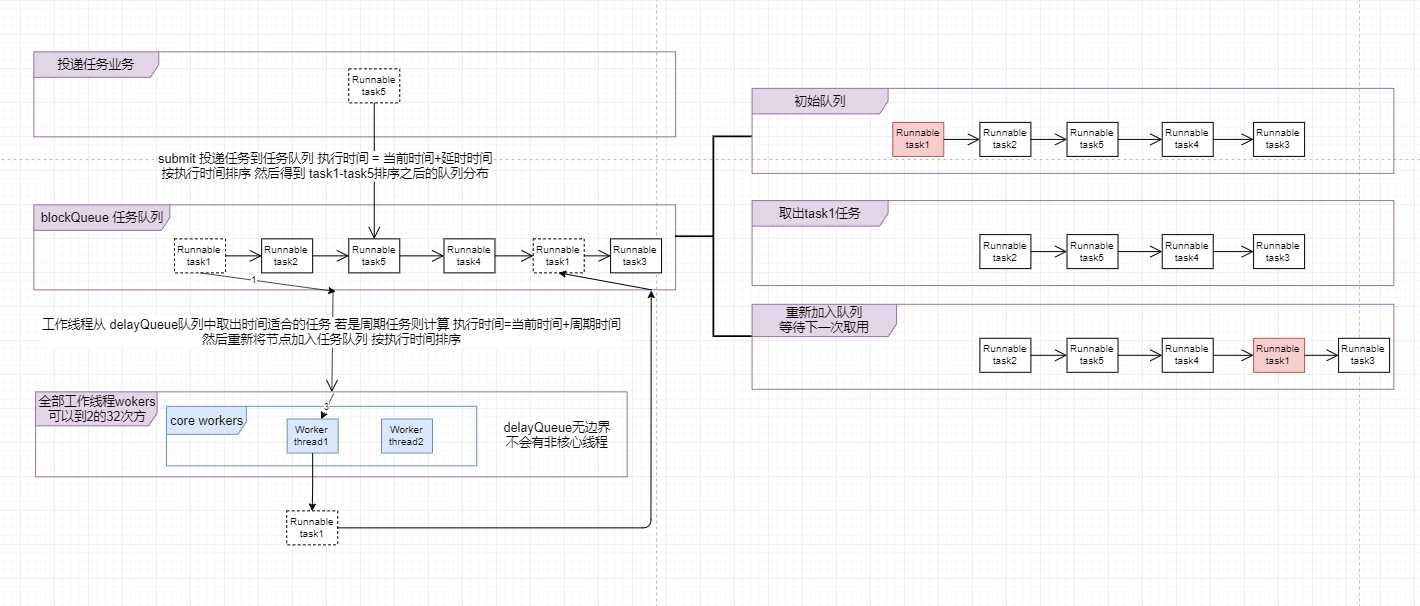
源码工作流程简述:
1 创建一个delayBlockQueue延迟阻塞队列, 队列的功能是take()的时候根据给定条件阻塞是否能取出,offer()的时候根据给定的条件进行排序, 从而得到一个有序队列
2 提交任务时比较核心线程是否全部使用, 若未全部使用则开辟一个新的核心线程, 因为构造函数不能设置delayBlockQueue大小(有的文章说边界), 所以只有核心线程会参与执行任务
3 和ThreadPoolExcutor一样, 核心线程会不断的从队列中取出任务,
判断任务是否为周期任务
1非周期任务则直接执行任务
2若是周期任务则根据周期时间正负决定下一次执行时间 a.若正 执行时间=上一次执行时间+延时 b.若负 执行时间=当前时间+延时
可以看出如果需要每次执行完都有延时 则周期时间为负数, 若需要当执行时间大于延时时间则需要设置周期时间为正数
数据结构图:
关键源码分析:
ScheduledFuture<?> schedule(Runnable command,long delay, TimeUnit unit)
ScheduledThreadPoolExecutor extends ThreadPoolExecutor //构造函数 public ScheduledThreadPoolExecutor(int corePoolSize) { //实际上是使用了ThreadPoolExecutor的构造方法 阻塞队列为DelayedWorkQueue(有序的延迟队列) super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue()); } //-----------------------------提交延时任务---------------------------- public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit) { if (command == null || unit == null) throw new NullPointerException(); //构建任务Task RunnableScheduledFuture<?> t = decorateTask(command, new ScheduledFutureTask<Void>(command, null,triggerTime(delay, unit))); //延时执行任务 delayedExecute(t); return t; } //执行时间 公式很强简单 任务执行时间=当前时间+延时时间 private long triggerTime(long delay, TimeUnit unit) { return triggerTime(unit.toNanos((delay < 0) ? 0 : delay)); } //延时执行任务 private void delayedExecute(RunnableScheduledFuture<?> task) { //判断线程池状态是否为shutDown 若是则拒绝此次任务 if (isShutdown()) //拒绝任务 reject(task); else { //将任务加入队列 注意:DelayedWorkQueue入队列需要根据任务执行时间排序 super.getQueue().add(task); //判断是否需要取消此次任务 if (isShutdown() && !canRunInCurrentRunState(task.isPeriodic()) && remove(task)) task.cancel(false); else //确保任务能运行 ensurePrestart(); } } //判断是否能在此状态下运行 boolean canRunInCurrentRunState(boolean periodic) { // 返回是否可以运行 // 1若是周期执行根据continueExistingPeriodicTasksAfterShutdown判断 // 2若非周期函数根据executeExistingDelayedTasksAfterShutdown判断 return isRunningOrShutdown(periodic ? continueExistingPeriodicTasksAfterShutdown : executeExistingDelayedTasksAfterShutdown); } //从队列中移除此次任务 public boolean remove(Runnable task) { boolean removed = workQueue.remove(task); tryTerminate(); // In case SHUTDOWN and now empty return removed; } //确保任务能运行 void ensurePrestart() { //获取当前worker数量 int wc = workerCountOf(ctl.get()); //如果数量小于核心线程数 则开启新的核心工作线程 if (wc < corePoolSize) addWorker(null, true); //如果根本没有工作中的线程 则开启一个非核心线程 else if (wc == 0) addWorker(null, false); } //-----------------------------执行延时任务---------------------------- //上一节我们知道工作线程向阻塞队列获取任务 然后执行task.run() 来完成任务执行 //下面直接看ScheduledFutureTask的run方法 public void run() { //判断是否为周期任务 boolean periodic = isPeriodic(); //判断当前周期任务是否可以在线程池shutDown之后继续执行 根据continueExistingPeriodicTasksAfterShutdown判断 if (!canRunInCurrentRunState(periodic)) //删除任务 cancel(false); //如果非周期任务 则与普通任务一样直接执行 else if (!periodic) ScheduledFutureTask.super.run(); //如果此任务为周期任务 则需要考虑执行完之后重新放入执行队列 保证下一次执行 else if (ScheduledFutureTask.super.runAndReset()) { //设置下一次执行时间 setNextRunTime(); //重新放入任务队列 等待工作工作线程获取任务 reExecutePeriodic(outerTask); } } //设置下一次远行时间 //上面有讲到过两个周期执行方法的区别: //scheduleAtFixedRate执行时间若大于周期时间 则执行完此次任务 直接执行下一次任务 不需要延时 //scheduleWithFixedDelay 不管执行时间是否大于周期时间 都需要在上一次执行完成之后延迟执行 //其原理就在下面 private void setNextRunTime() { //scheduleAtFixedRate设置period为正数 scheduleWithFixedDelay设置period为负数 long p = period; if (p > 0) time += p; else //当前时间基础上+延迟时间 time = triggerTime(-p); }
思考:
以上源码解析基本解释了计划任务线程池的工作原理, 并且使用了一个阻塞的有序延迟队列来维护任务计划任务的存放, 既然有序肯定需要根据某个值来进行对比,然后排序
已经知道是根据执行时间time(当前时间+延迟时间)来判断排序的, 但是若一样如何解决呢, 线程池另外维护个一个原子参数 AtomicLong sequencer , 线程池内所有新增任务共享,
每次新增任务则sequencer加1, 并把赋值给task的属性long sequenceNumber(任务非共享不需要原子约束),继而每个任务都有一个排序号,当执行时间time值一样时则根据sequenceNumber对比
ScheduledThreadPoolExecutor 与 ThreadPoolExecutor区别
1 ScheduledThreadPoolExecutor 使用的延时阻塞排序队列(类DelayedWorkQueue),根据执行时间排序; 而 ThreadPoolExecutor使用的的是阻塞队列(接口BlockingQueue),定义上BlockingQueue更抽象, 可以支持任何实现BlockingQueue接口的实现类
2 ScheduledThreadPoolExecutor 可以根据任务的属性重新加入队列等待下一次执行; ThreadPoolExecutor是一次性任务
3 ScheduledThreadPoolExecutor 队列不设边界, 也无法设置边界, 任务数非常多可能导致内存不够; ThreadPoolExecutor可以设置任务队列边界, 任务过多时丢弃新的任务
以上是关于Executors框架二 ScheduledThreadPoolExecutor线程池的主要内容,如果未能解决你的问题,请参考以下文章