Yolo V3整体思路流程详解!
Posted lzq116
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Yolo V3整体思路流程详解!相关的知识,希望对你有一定的参考价值。
结合开源项目tensorflow-yolov3(https://link.zhihu.com/?target=https%3A//github.com/YunYang1994/tensorflow-yolov3),理解YOLO v3实现细节整体套路 简单写写
1.数据预处理
voc_annotation.py生成训练测试txt文件,存储了图片路径,bbox和类别
dataset.py 的功能如下:
(1)通过读取voc_annotation.py生成的train.txt文件,对图片进行增强处理(包括旋转,随机裁剪和翻转等);
(2)同时根据train.txt文件中读取的bbox生成对应的label,label存储大中小3种真实框的中心宽高置信度和类别;
2.网络结构
common.py定义卷积模块,残差模块,合并模块和上采样模块
backbone.py 定义darknet53网络结构
yolov3.py中build_nework()返回3组 大中小特征图(1*13*13*255,1*26*26*255,1*52*52*255) decode()根据生成的网格计算中心坐标宽高置信度和类别
3.损失函数

主要分为三大部分: 边界框坐标损失, 分类损失和置信度损失。
(1)边界框损失
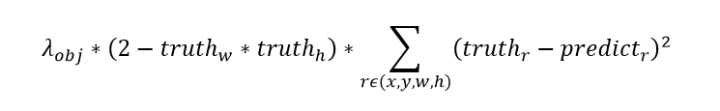
与yolo v1的边界框坐标损失类似,v3中使用误差平方损失函数分别计算(x, y, w, h)的Loss,然后加在一起。v1中作者对宽高(w, h)做了开根号处理,
为了弱化边界框尺寸对损失值的影响。在v3中作者没有采取开根号的处理方式,而是增加1个与物体框大小有关的权重,权重=2 - 相对面积,取值范围(1~2)。
(2)分类损失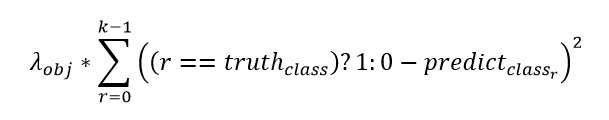
判断网格内有无物体。使用误差平方损失函数计算类别class 的Loss。
(3)置信度损失
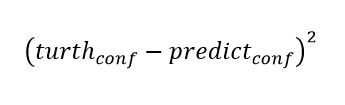
使用误差平方损失函数计算置信度conf 的Loss。
yolo v3三种不同尺度的输出,一共产生了(13*13*3+26*26*3+52*52*3)=10647个预测框。
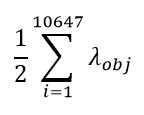
这个10647就是这么来的。
最终Loss采用和的形式而不是平均Loss, 主要原因为预测的特殊机制, 造成正负样本比巨大, 尤其是置信度损失部分, 以一片包含一个目标为例,
置信度部分的正负样本比可以高达1:10646, 如果采用平均损失, 会使损失趋近于0, 网络预测变为全零, 失去预测能力。
大体粗略记录下,下面这位大神讲的很清楚,我就不照搬了
参考文章:https://zhuanlan.zhihu.com/p/80208709
以上是关于Yolo V3整体思路流程详解!的主要内容,如果未能解决你的问题,请参考以下文章