为什么HTTP请求行中会出现“https”?
Posted liqiuhao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么HTTP请求行中会出现“https”?相关的知识,希望对你有一定的参考价值。
问题

HTTP明明是跑在TLS之上,怎么会意识到https的存在呢?
太长不看
在HTTP/1.1给正向代理的请求行中,方法后面的参数是 absoluteURI,而非 http URL,即可以使用任何代理支持的协议。 也就是说,该参数表达的是任何可以识别特定资源的标志,所以https作为一种协议可能会出现在该位置。
文档规定
在 RFC2616 中,规定请求行的格式为 Method SP **Request-URI** SP HTTP-Version CRLF,而 Request-URI 的格式为 "*" | absoluteURI | abs_path | authority。其中,abs_path 是我们最常看到的,例如 /pub/WWW/TheProject.html,通过联合请求头中的HOST字段,我们就可以访问到资源了。
但有时我们的HTTP请求是给一个正向代理的。HTTP/1.1规定,在这种情况下,Request-URI 必须 absoluteURI 的格式,即 scheme ":" ( hier_part | opaque_part ) 。其中,scheme 定义了该URI的命名空间,告诉了代理该资源标识符的语义和语法。所以,它可以是 https:// … 或者 ftp:// … ,甚至可以不指定协议,例如 file:// … 。
同时,为了避免在代理的过程中产生回环, RFC2616 要求代理的实现必须能够通过 absoluteURI 确定资源所有的服务器/别名,IP地址,主机名等。
设计分析
为什么给正向代理的HTTP请求行中需要URI,而非 abs_path + HOST字段?
因为这里只确定客户端和代理之间是通过HTTP协议通信的,并不知道代理会通过何种方式访问资源。所以我们需要在HTTP请求行中告知代理URI,如果代理支持对应的访问,则在成功获取资源后通过HTTP返回给客户端。
另外,除了直接请求资源服务器,代理也可能把这个请求交给下一个代理,这之间的通信也可能不是基于HTTP的,只有代理在知道完整URI的情况下才能确保接下来的步骤正确运行。
如果使用绝对URI,是否会和HOST字段的信息产生冗余?
在HTTP/1.1中,HOST字段是强制的。其目的是告知服务端请求资源所在的(虚拟)主机和端口号,例如 Host: www.w3.org 。所以代理请求行中的绝对URI是会和HOST产生信息冗余的。事实上,RFC7230 规定这种情况下代理必须忽略HOST字段信息,并通过请求行中的URI重新填充HOST字段。
为什么实现不良的代理可能会产生回环?
在现在的网络环境下,CDN/反向代理的情况非常普遍。CDN的边际网络会根据请求选择直接返回缓存或者继续转发请求,所以一个请求可能会被多次代理。但是,如果代理无法、或错误的判断资源来源时,就可能发生回环。例如,代理 A 判断应该把请求交给代理B,但是 B 在接到请求后认为该请求应该交给代理 A ,这样就形成了回环(也可能有多个节点),最终导致请求被丢弃。
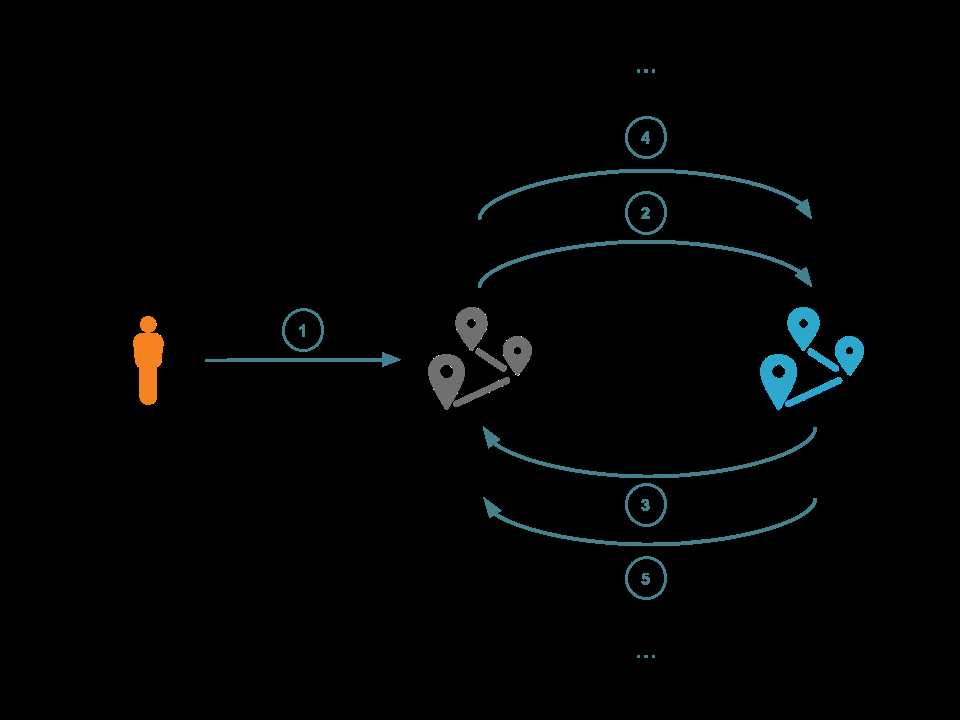
如上图所示,这种回环的发生不仅导致了数据的丢失,也耗费了大量带宽和代理的资源。事实上,这也被作为一种对CDN的“杠杆”拒绝服务攻击。
关于如何通过扩展HTTP头来解决这个问题,可以参考 Preventing Request Loops Using CDN-Loop 。
后记
回到最初的问题,如上所述,代理对于不同 scheme 的支持完全取决于实现,如果代理无法支持以 https:// 开头的代理请求,则会返回4xx状态。例如 CDN 提供商 fastly 在4年前就是这样。
以上是关于为什么HTTP请求行中会出现“https”?的主要内容,如果未能解决你的问题,请参考以下文章