零拷贝
Posted kailaisii
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了零拷贝相关的知识,希望对你有一定的参考价值。
概念
零拷贝
CPU不执行数据从一个存储区域到另一个存储区域的任务。所以同一个存储区域之间的拷贝也属于零拷贝。
DMA
DMA(Direct Memory Access,直接存储器访问)。将一批数据从源地址搬运到目的地址去而不经过CPU的干预。相关知识可以参考DMA之理解
I/O内存映射(mmap)
关联 进程中的1个虚拟内存区域 & 1个磁盘上的对象,使得二者存在映射关系。这样不再需要来回的进行数据的复制,即数据不需要在内核空间和用户空间进行数据拷贝了。此处留下一个问题,Java中的volatile关键字是和内存应该有关系么?
传统I/O
在Java中,我们可以通过InputStream从数据源将数据读取到缓冲区,然后可以通过OutputStream来将数据保存到数据源。这种方式相对来说效率低下。这是因为什么呢?我们看一下传统IO操作,在系统层面发生了什么。
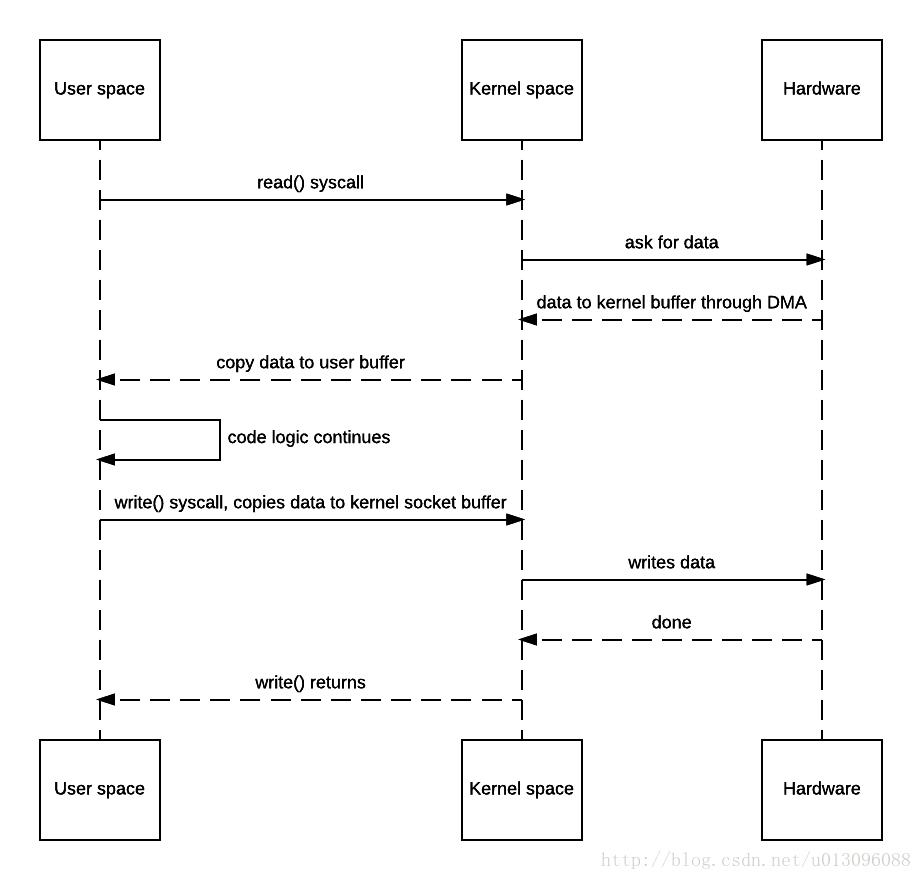
加入我们现在有一个需求:将某个图片文件读取出来,然后发送
我们看一下这里面的操作
- JVM发出Read()系统请求
- OS进行上下文切换,切到内核模式(第一次上下文切换),并将数据从数据源读取到内核缓冲区(第一次数据拷贝:hardware->kernel-buffer)
- OS内核将数据从内核缓冲区复制到用户空间缓冲区(第二次拷贝:kernel buffer->user buffer)。到此read()函数返回。系统调用返回导致从内核空间切到用户空间(第二次上下文切换)
- JVM处理完代码后调用write()系统请求。
- OS进行上下文切换,切到内核模式(第三次上下文切换),并将数据才能给用户空间缓冲区复制到内核缓冲区(第三次拷贝:user buffer->kernel buffer)
- write系统返回,从内核空间切换到用户空间(第四次上下文切换)。然后系统将内核缓冲区的数据写到协议引擎上(这里是网卡设备)(第四次拷贝:kernel buffer->hardware).。
整体来说,进行了4次上下文的切换和4次的数据拷贝。但是其实是有2次拷贝是没有用的,如果我们直接从hardware读取数据到kernel buffer之后,再从kernel buffer直接写到目标地址就可以了,完全没有必要走一遍用户空间。
sendfile 实现零拷贝I/O
sendfile()方法是系统提供给我们的一种能够实现我们刚才的需求的一种方案。我们看一下使用sendfile之后的数据流向和上下文切换。
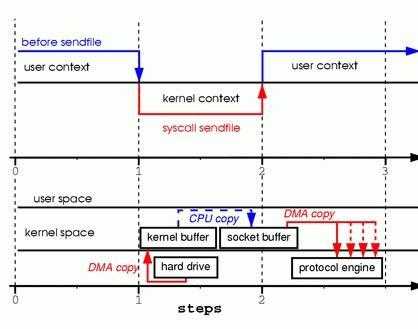
我们总结一下具体的流程:
- JVM发出transferTo()系统请求
- OS进行上下文切换,切到内核模式(第一次上下文切换),通过DMA将数据从数据源读取到内核缓冲区(第一次数据拷贝:hardware->kernel-buffer)
- 内核将数据从内核缓冲区拷贝到与socket相关内核缓冲区(第二次拷贝:user buffer->kernel buffer)
- sendfile系统返回,从内核空间切换到用户空间(第二次上下文切换)。然后系统将内核缓冲区的数据写到协议引擎上(这里是网卡设备)(第三次拷贝:kernel buffer->hardware).。
通过sendfile实现的零拷贝I/O只使用了2次上下文的切换和3次数据的拷贝。
我们所谓的0拷贝,并不是说真的0次数据的拷贝,而是相对于操作系统层面,没有用户空间和内核空间之间的数据拷贝过程。这就有一个经典的面试题了:0拷贝,是真的一次拷贝都不需要么?答案是显而易见的~~~
机智的小伙伴发现了,上述过程中从kernel buffer中将数据copy到socket buffer是没有必要的。都是在内核中操作,我直接从内核缓冲区拷贝到hardware不就可以了吗?嗯,小伙伴还是很有思考头脑的嘛~
其实上述方式是在Linux 2.1内核中使用的方案,在后来可能研发人员也发现了改进方案,所以在Linux 2.4中改进了代码的相关实现。
带有DMA的sendfile实现的零拷贝I/O
带有DMA的sendfile就是机智的小伙伴所要的答案。我们先看看他的时序图
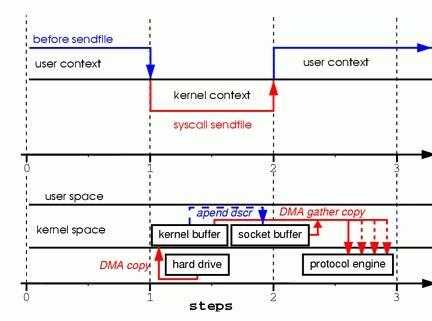
我们总结一下具体的流程:
- JVM发出sendfile系统请求
- OS进行上下文切换,切到内核模式(第一次上下文切换),通过DMA将数据从数据源读取到内核缓冲区(第一次数据拷贝:hardware->kernel-buffer)
- 这里没有将数据拷贝到socket缓冲区,而是将相应的描述符信息拷贝到socket缓冲区中。描述符中记录了kernel buffer的内存地址以及偏移量。
- sendfile系统返回,从内核空间切换到用户空间(第二次上下文切换)。DMA根据socket缓冲区中的描述符信息,直接将内核空间的数据拷贝到协议引擎上。
通过sendfile实现的零拷贝I/O只使用了2次上下文的切换和3次数据的拷贝。
带有DMA功能的sendfile实现IO的过程中,只使用了2次的上下文切换和2次的数据拷贝过程。相对于第二种方案,速度又有了提升。
基于mmap的优化
在相关概念里面,我们知道了,mmap 通过内存映射,将文件映射到内核缓冲区,同时,用户空间可以共享内核空间的数据。这样,我们在进行数据传输时,其实可以通过mmap技术,减少内核空间到用户空间之间的数据拷贝。
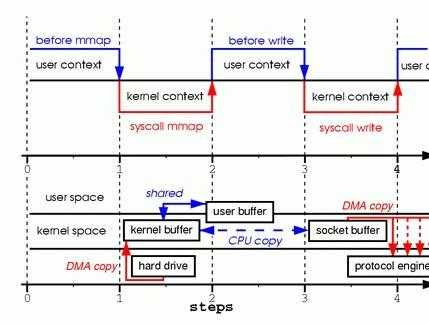
我们看一下这里面的操作
- JVM发出mmap系统请求
- OS进行上下文切换,切到内核模式(第一次上下文切换),并将数据从数据源读取到内核缓冲区(第一次数据拷贝:hardware->kernel-buffer)
- mmap系统调用返回,导致从内核空间切到用户空间(第二次上下文切换)。接着将内核缓冲区映射到用户空间缓冲区(这里并没有进行数据的拷贝)。用户空间和内核空间共享这个缓冲区,而不需要将数据从内核空间拷贝到用户空间。因为用户空间和内核空间共享了这个缓冲区数据,所以用户空间就可以像在操作自己缓冲区中数据一般操作这个由内核空间共享的缓冲区数据。
- JVM处理完代码后调用write()系统请求。
- OS进行上下文切换,切到内核模式(第三次上下文切换),并将数据从内核缓冲区复制到socket的内核缓冲区(第二次拷贝:kernel buffer->socket buffer)
- write系统返回,从内核空间切换到用户空间(第四次上下文切换)。然后系统将内核缓冲区的数据写到协议引擎上(这里是网卡设备)(第三次拷贝:kernel buffer->hardware)。
可以看到,相比较于传统的IO,通过mmap优化,将拷贝次数从四次变为了3次。其中3次数据拷贝中包括了2次DMA拷贝和1次CPU拷贝,能够提升一部分IO效率。
mmap VS sendFile
mmap和sendfile都属于零拷贝的实现方式。在具体的选择上,要根据实际的情况来进行考虑。
- mmp适合小数据量读写,sendFile适合大文件传输。
- mmp需要4次上下文切换,3次数据拷贝;sendFile需要3次上下文切换,3次(或者2次)数据拷贝。
- sendFile可以利用DMA方式减少CPU拷贝;mmap只能减少用户层和内核层之间的拷贝,不能减少CPU拷贝。
在进行数据传输时,不同的开源应用采用了不同的实现方式:
sendFile使用者:Tomcat内部文件拷贝,Tomcat的心跳保活,kafka,pulsar 下载文件
mmap使用者:rocketMQ消费消息
剩下的使用案例,欢迎大家补充
本文由 开了肯 发布!
以上是关于零拷贝的主要内容,如果未能解决你的问题,请参考以下文章