使用Merkle树检测数据不一致(翻译)
Posted victor2302
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Merkle树检测数据不一致(翻译)相关的知识,希望对你有一定的参考价值。
背景
Cassandra的逆熵功能使用Merkle树来检测副本之间的数据不一致。
定义
Merkle树是一种哈希树,其中的叶子包含各个数据块的哈希值,父节点包含其各自的子节点的哈希值。它提供了一种有效的方法来查找副本上存储的数据块中的差异,并减少了传输以比较数据块的数据量。
Cassandra的Merkle树(org.apache.cassandra.utils.MerkleTree)的实现使用完美的二叉树,其中每个叶子都包含行值的哈希,每个父节点都包含其左右子节点的哈希。在一棵完美的二叉树中,所有叶子都处于同一水平或相同深度。深度为h的完美二叉树包含2 ^ h树叶。换句话说,如果范围包含n个标记,则表示该范围的Merkle树包含log(n)级别。
执行nodetool repair命令时,在命令中用-h选项指定的目标节点会协调每个键空间中每个列系列的修复。修复协调器节点从每个副本请求Merkle树以获取特定的令牌范围,以对其进行比较。每个副本通过扫描在请求的令牌范围内本地存储的数据来构建Merkle树。修复协调器节点比较Merkle树,找到所有副本之间不同的子令牌范围,并修复这些范围内的数据。
复制节点为每个列族构建一个Merkle树,以表示给定令牌范围内的行的哈希。使用RandomPartitioner时,令牌范围最多可以包含2 ^ 127个令牌。需要深度为127的Merkle树,其中包含2 ^ 127个叶子。Cassandra构建了深度为15的Merkle树的紧凑版本,以减少用于存储树的内存使用量,并最小化将Merkle树传输到另一个节点所需的数据量。它将扩展树,直到将给定的令牌范围划分为32768个子范围。在树的紧凑版本中,每个叶子表示其各自子范围中所有行的哈希。无论其大小和拆分程度如何,如果两棵Merkle树具有相同的哈希深度,就可以对其进行比较。
例如,令牌范围(0,256]包含256个子范围(0,1],(1,2] ...(255,256],每个包含单个令牌。深度为8的完美二叉树需要在叶子上存储所有256个子范围散列。深度为3的同一版本的树的紧凑版本仅包含8个代表子范围(0,32],(32,64] ...(224,256]子集散列的叶子包含32个令牌。在此紧凑型树中,每个叶哈希是深度为8的理想二叉树中其下所有节点的计算哈希。
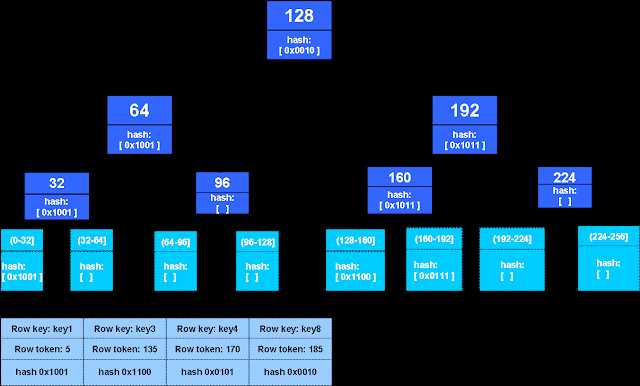
构建Merkle树(递归)
RandomPartitioner均匀地分配key,因此通过将给定标记范围分成两个相等的子范围,直到达到最大子范围数,从而递归构造Merkle树。将根节点添加给定的令牌范围(左,右),并在令牌的范围内将其分为两半,令牌位于范围的中点。左侧的子节点添加范围(左,中点)和在右边的子节点上添加范围覆盖(中点,右边),重复此过程,直到将所需数量的叶子(子范围)添加到树上为止。
将下一行哈希按排序顺序添加到Merkle树中。通过计算行值的MD5摘要来计算每行的哈希值,该值包括行的列数,列名和列值,但不包括行键和行大小。删除的行(逻辑删除)哈希也会添加到树中,其中包括删除时间戳。行哈希基于其令牌添加到Merkle树叶。如果叶子的子范围包含多行,则使用XOR操作通过组合其范围所覆盖的所有行的哈希来计算其哈希。非叶节点哈希值是通过对各自子节点的哈希值执行XOR计算得出的。
比较默Merkle树(递归)
如果两棵Merkle树都覆盖相同的令牌范围,则无论它们的大小如何,都将对其进行比较。从根哈希开始递归比较树。如果两个树中的根哈希都匹配,则树的令牌范围中的所有数据块在副本之间都是一致的。如果根哈希不一致,则比较左子哈希,然后再比较右子哈希。进行比较,直到计算出两棵树之间的所有令牌范围都不同为止。
Q&A
Q:如何保证节点保存的token范围都是一致的??
A:因为Cassandra的复制节点是顺时针进行制定的,复制的数量由复制因子决定,而比较就发生这些节点之间
小结
Merkle树不仅可以快速比较 多个文件是否完全相同,而且如果不同可以快速定位到不相同的文件
参考
http://distributeddatastore.blogspot.com/2013/07/cassandra-using-merkle-trees-to-detect.html
以上是关于使用Merkle树检测数据不一致(翻译)的主要内容,如果未能解决你的问题,请参考以下文章