面向过程 VS 面向对象
编程范式
编程是 程序 员 用特定的语法+数据结构+算法组成的代码来告诉计算机如何执行任务的过程 , 一个程序是程序员为了得到一个任务结果而编写的一组指令的集合,正所谓条条大路通罗马,实现一个任务的方式有很多种不同的方式, 对这些不同的编程方式的特点进行归纳总结得出来的编程方式类别,即为编程范式。 不同的编程范式本质上代表对各种类型的任务采取的不同的解决问题的思路, 大多数语言只支持一种编程范式,当然也有些语言可以同时支持多种编程范式。 两种最重要的编程范式分别是面向过程编程和面向对象编程。
面向过程编程(Procedural Programming)
Procedural programming uses a list of instructions to tell the computer what to do step-by-step.
面向过程编程依赖 - 你猜到了- procedures,一个procedure包含一组要被进行计算的步骤, 面向过程又被称为top-down languages, 就是程序从上到下一步步执行,一步步从上到下,从头到尾的解决问题 。基本设计思路就是程序一开始是要着手解决一个大的问题,然后把一个大问题分解成很多个小问题或子过程,这些子过程再执行的过程再继续分解直到小问题足够简单到可以在一个小步骤范围内解决。
举个典型的面向过程的例子, 数据库备份, 分三步,连接数据库,备份数据库,测试备份文件可用性。
代码如下
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
def db_conn(): print("connecting db...")def db_backup(dbname): print("导出数据库...",dbname) print("将备份文件打包,移至相应目录...")def db_backup_test(): print("将备份文件导入测试库,看导入是否成功")def main(): db_conn() db_backup(‘my_db‘) db_backup_test()if __name__ == ‘__main__‘: main() |
这样做的问题也是显而易见的,就是如果你要对程序进行修改,对你修改的那部分有依赖的各个部分你都也要跟着修改, 举个例子,如果程序开头你设置了一个变量值 为1 , 但如果其它子过程依赖这个值 为1的变量才能正常运行,那如果你改了这个变量,那这个子过程你也要修改,假如又有一个其它子程序依赖这个子过程 , 那就会发生一连串的影响,随着程序越来越大, 这种编程方式的维护难度会越来越高。
所以我们一般认为, 如果你只是写一些简单的脚本,去做一些一次性任务,用面向过程的方式是极好的,但如果你要处理的任务是复杂的,且需要不断迭代和维护 的, 那还是用面向对象最方便了。
面向对象编程
OOP编程是利用“类”和“对象”来创建各种模型来实现对真实世界的描述,使用面向对象编程的原因一方面是因为它可以使程序的维护和扩展变得更简单,并且可以大大提高程序开发效率 ,另外,基于面向对象的程序可以使它人更加容易理解你的代码逻辑,从而使团队开发变得更从容。
面向对象的几个核心特性如下
Class 类
一个类即是对一类拥有相同属性的对象的抽象、蓝图、原型。在类中定义了这些对象的都具备的属性(variables(data))、共同的方法
Object 对象
一个对象即是一个类的实例化后实例,一个类必须经过实例化后方可在程序中调用,一个类可以实例化多个对象,每个对象亦可以有不同的属性,就像人类是指所有人,每个人是指具体的对象,人与人之前有共性,亦有不同
Encapsulation 封装
在类中对数据的赋值、内部调用对外部用户是透明的,这使类变成了一个胶囊或容器,里面包含着类的数据和方法
Inheritance 继承
一个类可以派生出子类,在这个父类里定义的属性、方法自动被子类继承
Polymorphism 多态
多态是面向对象的重要特性,简单点说:“一个接口,多种实现”,指一个基类中派生出了不同的子类,且每个子类在继承了同样的方法名的同时又对父类的方法做了不同的实现,这就是同一种事物表现出的多种形态。
编程其实就是一个将具体世界进行抽象化的过程,多态就是抽象化的一种体现,把一系列具体事物的共同点抽象出来, 再通过这个抽象的事物, 与不同的具体事物进行对话。
对不同类的对象发出相同的消息将会有不同的行为。比如,你的老板让所有员工在九点钟开始工作, 他只要在九点钟的时候说:“开始工作”即可,而不需要对销售人员说:“开始销售工作”,对技术人员说:“开始技术工作”, 因为“员工”是一个抽象的事物, 只要是员工就可以开始工作,他知道这一点就行了。至于每个员工,当然会各司其职,做各自的工作。
多态允许将子类的对象当作父类的对象使用,某父类型的引用指向其子类型的对象,调用的方法是该子类型的方法。这里引用和调用方法的代码编译前就已经决定了,而引用所指向的对象可以在运行期间动态绑定
面向对象编程(Object-Oriented Programming )介绍
- 写重复代码是非常不好的低级行为
- 你写的代码需要经常变更
|
1
2
3
4
5
6
7
8
9
10
11
|
#role 1name = ‘Alex‘role = ‘terrorist‘weapon = ‘AK47‘life_value = 100#rolw 2name2 = ‘Jack‘role2 = ‘police‘weapon2 = ‘B22‘life_value2 = 100 |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#role 1name = ‘Alex‘role = ‘terrorist‘weapon = ‘AK47‘life_value = 100money = 10000#rolw 2name2 = ‘Jack‘role2 = ‘police‘weapon2 = ‘B22‘life_value2 = 100money2 = 10000#role 3name3 = ‘Rain‘role3 = ‘terrorist‘weapon3 = ‘C33‘life_value3 = 100money3 = 10000#rolw 4name4 = ‘Eric‘role4 = ‘police‘weapon4 = ‘B51‘life_value4 = 100money4 = 10000 |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
roles = { 1:{‘name‘:‘Alex‘, ‘role‘:‘terrorist‘, ‘weapon‘:‘AK47‘, ‘life_value‘: 100, ‘money‘: 15000, }, 2:{‘name‘:‘Jack‘, ‘role‘:‘police‘, ‘weapon‘:‘B22‘, ‘life_value‘: 100, ‘money‘: 15000, }, 3:{‘name‘:‘Rain‘, ‘role‘:‘terrorist‘, ‘weapon‘:‘C33‘, ‘life_value‘: 100, ‘money‘: 15000, }, 4:{‘name‘:‘Eirc‘, ‘role‘:‘police‘, ‘weapon‘:‘B51‘, ‘life_value‘: 100, ‘money‘: 15000, },}print(roles[1]) #Alexprint(roles[2]) #Jack |
- 被打中后就会掉血的功能
- 开枪功能
- 换子弹
- 买枪
- 跑、走、跳、下蹲等动作
- 保护人质(仅适用于警察)
- 不能杀同伴
- 。。。
|
1
2
3
4
5
6
7
8
9
10
11
|
def shot(by_who): #开了枪后要减子弹数 passdef got_shot(who): #中枪后要减血 who[‘life_value’] -= 10 passdef buy_gun(who,gun_name): #检查钱够不够,买了枪后要扣钱 pass... |
- 每个角色定义的属性名称是一样的,但这种命名规则是我们自己约定的,从程序上来讲,并没有进行属性合法性检测,也就是说role 1定义的代表武器的属性是weapon, role 2 ,3,4也是一样的,不过如果我在新增一个角色时不小心把weapon 写成了wepon , 这个程序本身是检测 不到的
- terrorist 和police这2个角色有些功能是不同的,比如police是不能杀人质的,但是terrorist可能,随着这个游戏开发的更复杂,我们会发现这2个角色后续有更多的不同之处, 但现在的这种写法,我们是没办法 把这2个角色适用的功能区分开来的,也就是说,每个角色都可以直接调用任意功能,没有任何限制。
- 我们在上面定义了got_shot()后要减血,也就是说减血这个动作是应该通过被击中这个事件来引起的,我们调用get_shot(),got_shot()这个函数再调用每个角色里的life_value变量来减血。 但其实我不通过got_shot(),直接调用角色roles[role_id][‘life_value’] 减血也可以呀,但是如果这样调用的话,那可以就是简单粗暴啦,因为减血之前其它还应该判断此角色是否穿了防弹衣等,如果穿了的话,伤害值肯定要减少,got_shot()函数里就做了这样的检测,你这里直接绕过的话,程序就乱了。 因此这里应该设计 成除了通过got_shot(),其它的方式是没有办法给角色减血的,不过在上面的程序设计里,是没有办法实现的。
- 现在需要给所有角色添加一个可以穿防弹衣的功能,那很显然你得在每个角色里放一个属性来存储此角色是否穿 了防弹衣,那就要更改每个角色的代码,给添加一个新属性,这样太low了,不符合代码可复用的原则
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
class Role(object): def __init__(self,name,role,weapon,life_value=100,money=15000): self.name = name self.role = role self.weapon = weapon self.life_value = life_value self.money = money def shot(self): print("shooting...") def got_shot(self): print("ah...,I got shot...") def buy_gun(self,gun_name): print("just bought %s" %gun_name)r1 = Role(‘Alex‘,‘police‘,‘AK47’) #生成一个角色r2 = Role(‘Jack‘,‘terrorist‘,‘B22’) #生成一个角色 |
- 代码量少了近一半
- 角色和它所具有的功能可以一目了然看出来
|
1
2
3
4
5
6
7
8
9
|
class Dog(object): print("hello,I am a dog!")d = Dog() #实例化这个类,#此时的d就是类Dog的实例化对象#实例化,其实就是以Dog类为模版,在内存里开辟一块空间,存上数据,赋值成一个变量名 |
上面的代码其实有问题,想给狗起名字传不进去。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
class Dog(object): def __init__(self,name,dog_type): self.name = name self.type = dog_type def sayhi(self): print("hello,I am a dog, my name is ",self.name)d = Dog(‘LiChuang‘,"京巴")d.sayhi() |
为什么有__init__? 为什么有self? 此时的你一脸蒙逼,相信不画个图,你的智商是理解不了的!
画图之前, 你先注释掉这两句
|
1
2
3
4
|
# d = Dog(‘LiChuang‘, "京巴")# d.sayhi()print(Dog) |
没实例直接打印Dog输出如下
|
1
|
<class ‘__main__.Dog‘> |
这代表什么?代表 即使不实例化,这个Dog类本身也是已经存在内存里的对不对, yes, cool,那实例化时,会产生什么化学反应呢?
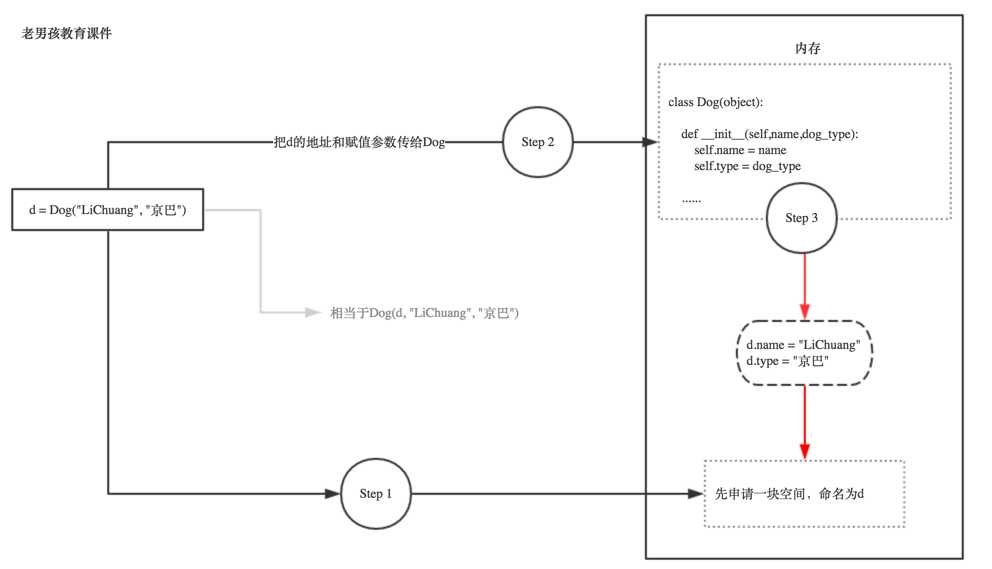
根据上图我们得知,其实self,就是实例本身!你实例化时python会自动把这个实例本身通过self参数传进去。
你说好吧,假装懂了, 但下面这段代码你又不明白了, 为何sayhi(self),要写个self呢?
|
1
2
3
4
5
|
class Dog(object): ... def sayhi(self): print("hello,I am a dog, my name is ",self.name) |
这个原因,我课上在讲。。。
|
1
|
<br><br><br><br> |
|
1
2
3
4
5
6
7
|
class Role(object): #定义一个类, class是定义类的语法,Role是类名,(object)是新式类的写法,必须这样写,以后再讲为什么 def __init__(self,name,role,weapon,life_value=100,money=15000): #初始化函数,在生成一个角色时要初始化的一些属性就填写在这里 self.name = name #__init__中的第一个参数self,和这里的self都 是什么意思? 看下面解释 self.role = role self.weapon = weapon self.life_value = life_value self.money = money |
|
1
2
|
r1 = Role(‘Alex‘,‘police‘,‘AK47’) #生成一个角色 , 会自动把参数传给Role下面的__init__(...)方法r2 = Role(‘Jack‘,‘terrorist‘,‘B22’) #生成一个角色 |
我们看到,上面的创建角色时,我们并没有给__init__传值,程序也没未报错,是因为,类在调用它自己的__init__(…)时自己帮你给self参数赋值了,
|
1
2
|
r1 = Role(‘Alex‘,‘police‘,‘AK47’) #此时self 相当于 r1 , Role(r1,‘Alex‘,‘police‘,‘AK47’)r2 = Role(‘Jack‘,‘terrorist‘,‘B22’)#此时self 相当于 r2, Role(r2,‘Jack‘,‘terrorist‘,‘B22’) |
- 在内存中开辟一块空间指向r1这个变量名
- 调用Role这个类并执行其中的__init__(…)方法,相当于Role.__init__(r1,‘Alex‘,‘police‘,’AK47’),这么做是为什么呢? 是为了把‘Alex‘,‘police‘,’AK47’这3个值跟刚开辟的r1关联起来,是为了把‘Alex‘,‘police‘,’AK47’这3个值跟刚开辟的r1关联起来,是为了把‘Alex‘,‘police‘,’AK47’这3个值跟刚开辟的r1关联起来,重要的事情说3次, 因为关联起来后,你就可以直接r1.name, r1.weapon 这样来调用啦。所以,为实现这种关联,在调用__init__方法时,就必须把r1这个变量也传进去,否则__init__不知道要把那3个参数跟谁关联呀。
- 明白了么哥?所以这个__init__(…)方法里的,self.name = name , self.role = role 等等的意思就是要把这几个值 存到r1的内存空间里。
|
1
2
|
def buy_gun(self,gun_name): print(“%s has just bought %s” %(self.name,gun_name) ) |
|
1
2
|
r1 = Role(‘Alex‘,‘police‘,‘AK47‘)r1.buy_gun("B21”) #python 会自动帮你转成 Role.buy_gun(r1,”B21") |
- 上面的这个r1 = Role(‘Alex‘,‘police‘,‘AK47’)动作,叫做类的“实例化”, 就是把一个虚拟的抽象的类,通过这个动作,变成了一个具体的对象了, 这个对象就叫做实例
- 刚才定义的这个类体现了面向对象的第一个基本特性,封装,其实就是使用构造方法将内容封装到某个具体对象中,然后通过对象直接或者self间接获取被封装的内容
面向对象的特性:
封装
封装最好理解了。封装是面向对象的特征之一,是对象和类概念的主要特性。
封装,也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
继承
面向对象编程 (OOP) 语言的一个主要功能就是“继承”。继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。
通过继承创建的新类称为“子类”或“派生类”。
被继承的类称为“基类”、“父类”或“超类”。
继承的过程,就是从一般到特殊的过程。
要实现继承,可以通过“继承”(Inheritance)和“组合”(Composition)来实现。
在某些 OOP 语言中,一个子类可以继承多个基类。但是一般情况下,一个子类只能有一个基类,要实现多重继承,可以通过多级继承来实现。
继承概念的实现方式主要有2类:实现继承、接口继承。
OO开发范式大致为:划分对象→抽象类→将类组织成为层次化结构(继承和合成) →用类与实例进行设计和实现几个阶段。
多态
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
#_*_coding:utf-8_*_class Animal(object): def __init__(self, name): # Constructor of the class self.name = name def talk(self): # Abstract method, defined by convention only raise NotImplementedError("Subclass must implement abstract method")class Cat(Animal): def talk(self): print(‘%s: 喵喵喵!‘ %self.name)class Dog(Animal): def talk(self): print(‘%s: 汪!汪!汪!‘ %self.name)def func(obj): #一个接口,多种形态 obj.talk()c1 = Cat(‘小晴‘)d1 = Dog(‘李磊‘)func(c1)func(d1) |
领域模型
好了,你现在会了面向对象的各种语法了, 那请看下本章最后的作业需求,我相信你可能是蒙蔽的, 很多同学都是学会了面向对象的语法,却依然写不出面向对象的程序,原因是什么呢?原因就是因为你还没掌握一门面向对象设计利器, 你说我读书少别骗我, 什么利器?
答案就是:领域建模。 从领域模型开始,我们就开始了面向对象的分析和设计过程,可以说,领域模型是完成从需求分析到面向 对象设计的一座桥梁。
领域模型,顾名思义,就是需求所涉及的领域的一个建模,更通俗的讲法是业务模型。 参考百度百科(http://baike.baidu.cn/view/757895.htm ),领域模型定义如下:
从这个定义我们可以看出,领域模型有两个主要的作用:
- 发掘重要的业务领域概念
- 建立业务领域概念之间的关系
领域建模三字经
领域模型如此重要,很多同学可能会认为领域建模很复杂,需要很高的技巧。然而事实上领域建模非常简 单,简单得有点难以让人相信,领域建模的方法概括一下就是“找名词”! 许多同学看到这个方法后估计都会笑出来:太假了吧,这么简单,找个初中生都会啊,那我们公司那些分 析师和设计师还有什么用哦?
分析师和设计师当然有用,后面我们会看到,即使是简单的找名词这样的操作,也涉及到分析和提炼,而 不是简单的摘取出来就可,这种情况下分析师和设计师的经验和技能就能够派上用场了。但领域模型分析 也确实相对简单,即使没有丰富的经验和高超的技巧,至少也能完成一个能用的领域模型。
虽然我们说“找名词”很简单,但一个关键的问题还没有说明:从哪里找? 如果你还记得领域模型是“需求到面向对象的桥梁”,那么你肯定一下子就能想到:从需求模型中找,具 体来说就是从用例中找。
归纳一下域建模的方法就是“从用例中找名词”。 当然,找到名词后,为了能够更加符合面向对象的要求和特点,我们还需要对这些名词进一步完善,这就 是接下来的步骤:加属性,连关系!
最后我们总结出领域建模的三字经方法:找名词、加属性、连关系。
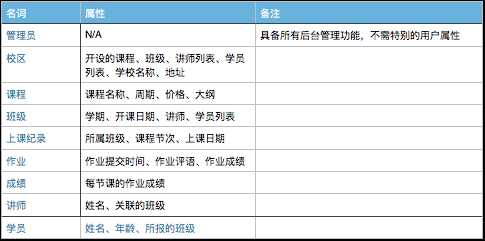
找名词
who : 学员、讲师、管理员
用例:
1. 管理员 创建了 北京 和 上海 两个校区
2. 管理员 创建了 Linux Python Go 3个课程
3. 管理员 创建了 北京校区的Python 16期, Go开发第一期,和上海校区的Linux 36期 班级
4. 管理员 创建了 北京校区的 学员 小晴 ,并将其 分配 在了 班级 python 16期
5. 管理员 创建了 讲师 Alex , 并将其分配 给了 班级 python 16期 和全栈脱产5期
6. 讲师 Alex 创建 了一条 python 16期的 上课纪录 Day6
7. 讲师 Alex 为Day6这节课 所有的学员 批了作业 ,小晴得了A, 李磊得了C-, 严帅得了B
8. 学员小晴 在 python 16 的 day6里 提交了作业
9. 学员李磊 查看了自己所报的所有课程
10 学员 李磊 在 查看了 自己在 py16期 的 成绩列表 ,然后自杀了
11. 学员小晴 跟 讲师 Alex 表白了
名词列表:
管理员、校区、课程、班级、上课纪录、作业、成绩、讲师、学员
加属性
连关系
有了类,也有了属性,接下来自然就是找出它们的关系了。
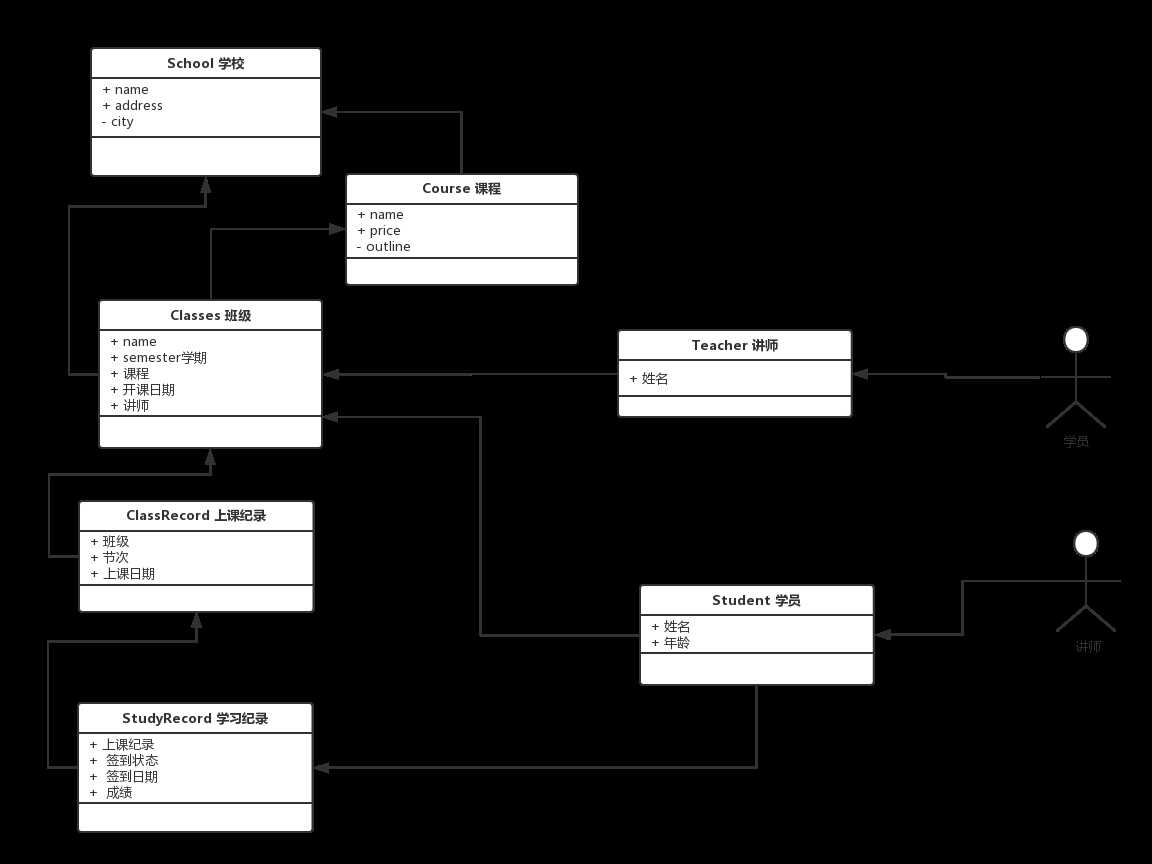
本节作业: 选课系统
角色:学校、学员、课程、讲师
要求:
1. 创建北京、上海 2 所学校
2. 创建linux , python , go 3个课程 , linuxpy 在北京开, go 在上海开
3. 课程包含,周期,价格,通过学校创建课程
4. 通过学校创建班级, 班级关联课程、讲师
5. 创建学员时,选择学校,关联班级
5. 创建讲师角色时要关联学校,
6. 提供两个角色接口
6.1 学员视图, 可以注册, 交学费, 选择班级,
6.2 讲师视图, 讲师可管理自己的班级, 上课时选择班级, 查看班级学员列表 , 修改所管理的学员的成绩
6.3 管理视图,创建讲师, 创建班级,创建课程
7. 上面的操作产生的数据都通过pickle序列化保存到文件里