ReID New page2
Posted warmchay
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ReID New page2相关的知识,希望对你有一定的参考价值。
拖了好久,选择的第一篇英语论文是2016年的,而这里面所涉及到的知识点大部分与之前的博客内容重合,这篇文章还是对之前的探讨的论文的一个补充,一节一节看下来,需要更得东西好像也不怎么多,就不发短的博客,而是总结节数,探讨一些节里面可能存在的问题。
英文论文的头疼之处在于翻译的地方,有一些逻辑不通的地方往往需要分析句子成分才能看懂,所以这几天也在认认真真地学英语了= =。
我在这篇文章里出现的概念和连接词理解的还不是很熟,只能说理解了一点点。
这次随笔没有链接,这些我认为有些问题的点我翻了很多个网页,总结概括了一些点加上了自己的一些东西,那个那个历史记录太多了,好难找┭┮﹏┭┮,对不起,米娜桑(>人<;)
废话不多说,我们开始吧。
这篇文章是在2016时对那个时候的一些方法的改进,相关的探讨的网络也是我们之前所说的所用的ID损失和属性损失,这里有意思的是在verification net这一处用的是pairwise dropout 共享同一种dropout,但与classification net的dropout使用是不同的,这个理由作者强调了,就不赘述了。
其次,也是对2016年之前的所用的手动标注特征、监督学习和无监督学习的一种对比改进,改进过程与2 3 4节,对比过程在5节,对比过程用了多种当时流行的模型来比较,用了直观的table使各个网络之间的优劣凸显出来。
文章是:Deep Transfer Learning for Person Re-identification
首先,先要对几个词进行翻译一下,在翻译软件上一般翻译都不太准确的几个词
metric learning 度量学习 co-training 联合训练 state-of-the-art 体现最高水平的 model drift模型环境漂流(模型环境漂移比模型漂移更贴切) Frobenious norm F-范数
接下来,是对文章中出现的一些概念进行一些阐述和一些小的个人总结,主要呈现的也是annotation的一些部分
(1)Transfer Learning(TL)
分类:
根据Domain: Source domain(源域)(后简称S) Target domain(目标领域)(后简称T)
根据Specific Space(特征空间) : 同构TL (Ds = Dt) 异构TL(Ds != Dt)
根据Transfer Circumstance:Iductive TL (归纳式)(Task S != Task T) Transductive TL (直推式)(S!=T && Task S = Task T)
Unsupervised TL(S 或 T都没有label)
Categorisation(分类):
· Instance based TL(基于样本) ------> 可人为提高S中关于T目标权重的大小
· Feature based TL(基于特征):① Ds = Dt 可以通过特征变换的方式来互相迁移进而减少S和T之间的discrepancy(差距)
②Ds != Dt --------> 常用办法 联合S和T (即 Aligning S and T)
·Parameter based TL(基于模型)--------> Find shared parameters(寻找可以共享的参数)
补充个概念,在一些介绍TL里都不会说,但在这篇文章用到的 fine-tune
Fine-tune(微调):
Concept:利用别人训练好的网络,依据Target进行调整(调整的是自己将要使用的网络)
Advantages:能够节省训练时间,提高学习精度
Disadvantags:不能处理Training dataset 和 Test dataset之间的discrepancies(即数据分布存在不同)
如何解决fine-tune带来的disadvantages呐? 我们有 深度网络自适应 ----> Use Adapatational Layer(自适应层)to manage T and S 的自适应,从而使S和T的数据分布更加接近。
(2)Model Drift(模型环境漂移)(我最懵的一点,感谢学长解答嗷嗷嗷!!)
概念:在ML中发现数据分布与原始训练集的数据分布有明显出入时,这个时候则需要重新训练模型,这个现象则称为model drift。
为什么不说为模型漂移呢? 因为是环境的变化违反了模型的假设,而这个则将导致模型的预测性能随时间而降低,所以变化的不是模型,而是模型的环境。因此称为模型环境漂移更为贴切。
(3)dictionary Learning(字典学习)
What: Target:提取事物最本质特征(类似字典中的字和词)
Why:如果能获取这本包括最本质特征的字典,即掌握了事物的最本质内涵。换言之,其将我们得到的信息进行了一个物体的信息降维,减少了噪音。
Theories: Model:
稀疏模型的effectiveness:去除冗余的vector,仅保留与响应vector最相关的解释vector。
这样做可以保留数据集中的重要信息,有效解决高维dataset建模中的问题
ps:稀不稀疏,实际上反映了特征提取的是否够关键,是否够本质,如何理解呢?我个人观点是,你的解释vector越多,其实越能限制你所要描述的
主体对象是什么,通过这个,也就可以逐渐地缩小范围获取到事物的最本质的特征。
Formula(公式):
x:输入的图像(维度为 )
D:字典模型(维度为*K)
α:疏松矩阵(维度为K)
Goal:
:
各分向量平方之后开方。
模型建立:

第一项是确保D和 能够很好地重构
(失真少),(这里的右小标2,应该是L2范数)
第二项是确保尽量稀疏(字典构建耦合性小,类似于在字典中我们解释一个字或词语尽可能的少用其他的词语)
Keypoint:如何计算呢?
·初始化 从样本集X中随机挑选n个样本,作为D的初始值;并且初始化α为0。
·求解xi 为了简单起见,我们抽出一个样本进行讨论,假定样本为x向量,稀疏代码为α向量。现在x和D算是已知的,求解α,同时满足α尽量的稀疏,也就是非零元素尽量的少。假设D为[d1,d2,d3,d4,d5],其中有5个原子。首先求出离x距离最近的原子,假设是d3。那么我们就可以求出一个初步的α为[0,0,c3,0,0],c3是一个未知系数,代表原子的权重。假定x=c3*d3。可求得c3的值。接着我们用求出的c3求残差向量x‘=x-c3*d3(此处),x‘是一个预设的阈值向量,当x‘小于阈值的话,则停止计算,如果不小于的话,转到下一步。 计算剩余的原子d1,d2,d4,d5中与残差向量x‘距离最近的,假设是d1,那么更新α为[c1,0,c3,0,0],假设x=c1*d1+c3*d3,求解出c1,然后更新残差向量x‘=x-c1*d1-c3*d3(此处
)。判断是否小于阈值,如果不满足,再继续求下一个最近的原子的系数。求解原子系数的数量也可以指定为一个常量,例如3,那就代表迭代3次。
·更新字典 通过上一个步骤可以求出所有的 ,接着就可以更新字典D了。保持α不变,使用相同步骤更新D。再保持D不变,使用相同步骤更新α。
(4)One Stage v.s. Two Stage (关于这个,我偷懒一下,我不会画图,所以直接把我的笔记放出来吧)


(5)Frobenius Norm(F-范数)(也称矩阵范数)
这个我找到了链接了!
https://www.cnblogs.com/BlameKidd/p/9734701.html
对这个链接进行一个补充:
argmax(argmin)函数:
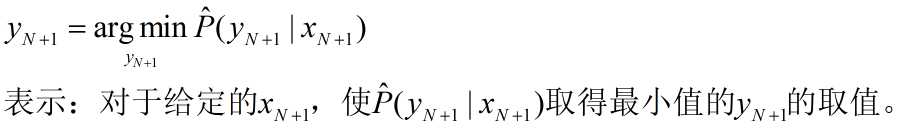
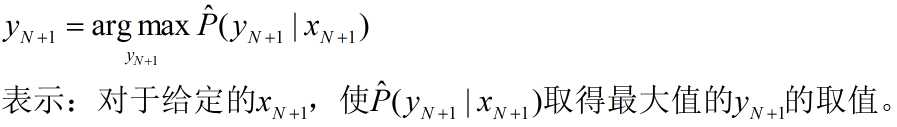
(6)CMC曲线(对rank1、rank5识别率的一个概述)
rank1识别率:当按照某种相似度匹配规则匹配后,第一次就能判断出正确的标签数目与总的测试样本数目之比,eg.10个球中有5个红球,第一次取出红球的概率是?
rank5识别率:值前五项(按照匹配程度从大到小排列后)里面有正确匹配的项数,那么如果一个样本按照匹配程度从大到小排列后,到最后一次才匹配到了正确标签,则说明分类器不太好,把最应该匹配的放到最后面了。
补充一个与CMC很像的ROC曲线(这个只是补充嗷嗷嗷,在这篇文章没有用到的):
就到这啦,这个拖得有点久,这篇文章我现在只过了一遍,因为英语不太好的原因,标注的和逻辑的一些打通需要一点时间(我在找借口QuQ)
好好学习,天天向上!
以上是关于ReID New page2的主要内容,如果未能解决你的问题,请参考以下文章