卷积神经网络-池化汇总
Posted yanshw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了卷积神经网络-池化汇总相关的知识,希望对你有一定的参考价值。
池化的概念是在 AlexNet 网络中提出的,之前叫做降采样;
池化到底在做什么,不多解释;
池化的作用
首先需要明确一下池化发生在哪里:卷积后经过激活函数形成了 feature map,即 Relu(wx + b) ,后面接池化层
1. 池化可以形象化的理解为降维
2. 池化避免了局部位移或者微小位置偏差带来的影响,提高模型鲁棒性
3. 池化减少模型参数,提高训练速度
4. 池化使得模型关注典型特征,如 max,提高模型准确率,一定程度上避免过拟合
池化的方式
两种方式,max_pooling 和 mean_pooling,不多解释
padding
池化的 padding 不同于 卷积的 padding,所以单独说明以下
padding 取 same 时,可能会给平面进行边界填充,但不是保证大小一致,是在池化野扫描时,假如扫描到边界时,剩余的格数小于池化野的大小时,对边界填充,使得剩余格数等于池化野大小,否则不需要填充。
padding 取 valid 时,不填充,假如扫描到边界时,剩余格数小于池化野的大小,就放弃剩余的格数
为什么 max_pooling 优于 mean_pooling
max_pooling 也是在 AlexNet 中提出来的,它的效果明显好于 mean_pooling,已经被作为池化的首选方式
max_pooling 的优势在于:
1. mean_pooling 是线性变换【取均值-线性】,max_pooling 是非线性变换【取max-非线性】,模型表达能力强
2. max_pooling 相当于减少了被激活的神经元,类似于 dropout,既减少参数,又防止过拟合
3. 从感性的角度讲,max_pooling 只关注典型特征,放弃普通特征,有助于提高模型精度
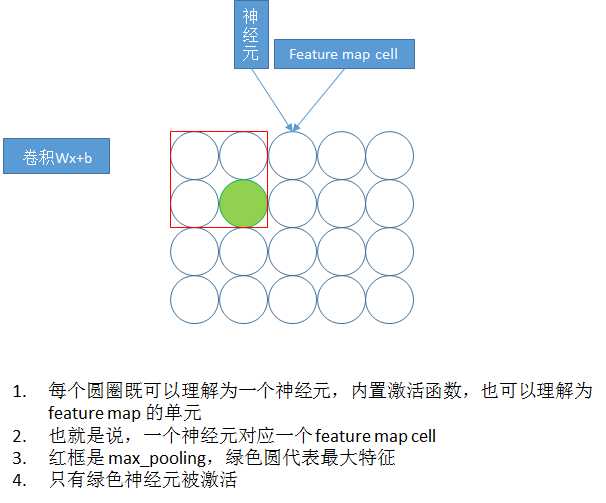
重叠池化
重叠池化也是在 AlexNet 中提出来的,其实很简单,
不重叠池化就是 上个池化野 和 下个池化野没有交集,也就是 池化野 的size 等于 stride,重叠池化就是 size > stride;
实践表明,重叠池化 + max_pooling 能很好的防止过拟合,提升模型性能
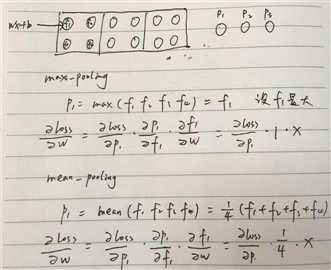
池化的反向传播
max_pooling 的反向传播 梯度恒为1,,mean_pooling 的反向传播梯度为 1/size,见下图
参考资料:
以上是关于卷积神经网络-池化汇总的主要内容,如果未能解决你的问题,请参考以下文章