2020/1/18寒假自学——学习进度报告2
Posted limitcm
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2020/1/18寒假自学——学习进度报告2相关的知识,希望对你有一定的参考价值。
写博客是时隔两天,但学习并没有停止。
这一篇博客还是写一下关于Spark基础知识的,上次只是总体名词的理解。
Spark的核心是建立在统一的抽象RDD之上,使得Spark的各个组件可以无缝进行集成,在同一个应用程序中完成大数据计算任务
于是RDD——由DAG图帮助形成的分布式内存的数据集帮助Spark达成了能比Hadoop快100倍的成就。每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算——这个便是RDD能实现分布的原理。RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。
RDD运行于分布式内存中,这使得它拥有了相对的高速度,而它的高度受限使其保证了稳定性和可靠性。RDD的可靠性还包括了它极易恢复的特点,一系列RDD往往是具有生成的轨迹,记录下这个生产轨迹的就是DVG图,所以任何片段的遗失可以通过其“血缘关系(Lineage)”的前辈来重新生成。
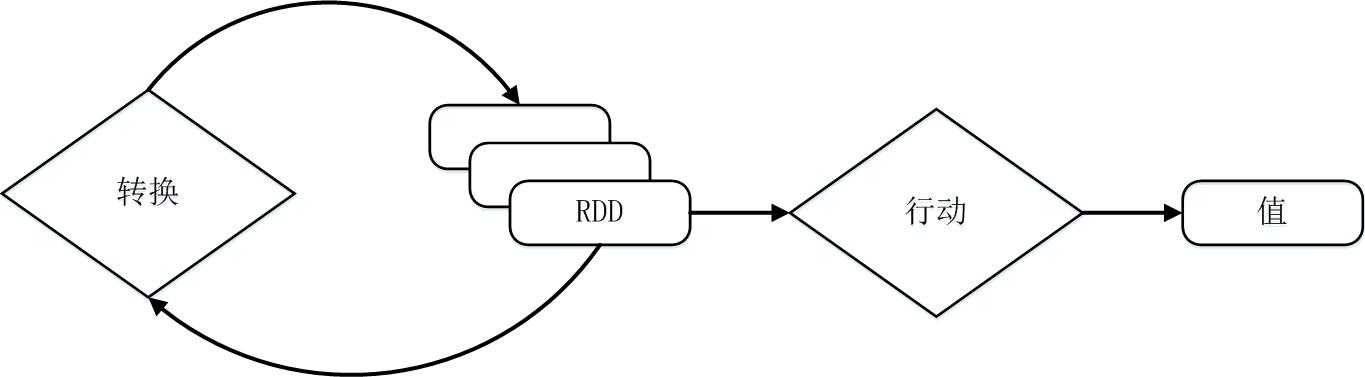
RDD典型的执行过程如下:
- RDD读入外部数据源(或者内存中的集合)进行创建;
- RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用;
- 最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala集合或标量)。
需要说明的是,RDD采用了惰性调用,即在RDD的执行过程中(如图9-8所示),真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
RDD之间的依赖关系
(1)对输入进行协同划分,属于窄依赖(如图a所示)。所谓协同划分(co-partitioned)是指多个父RDD的某一分区的所有“键(key)”,落在子RDD的同一个分区内,不会产生同一个父RDD的某一分区,落在子RDD的两个分区的情况。
(2)对输入做非协同划分,属于宽依赖(如图b所示)。
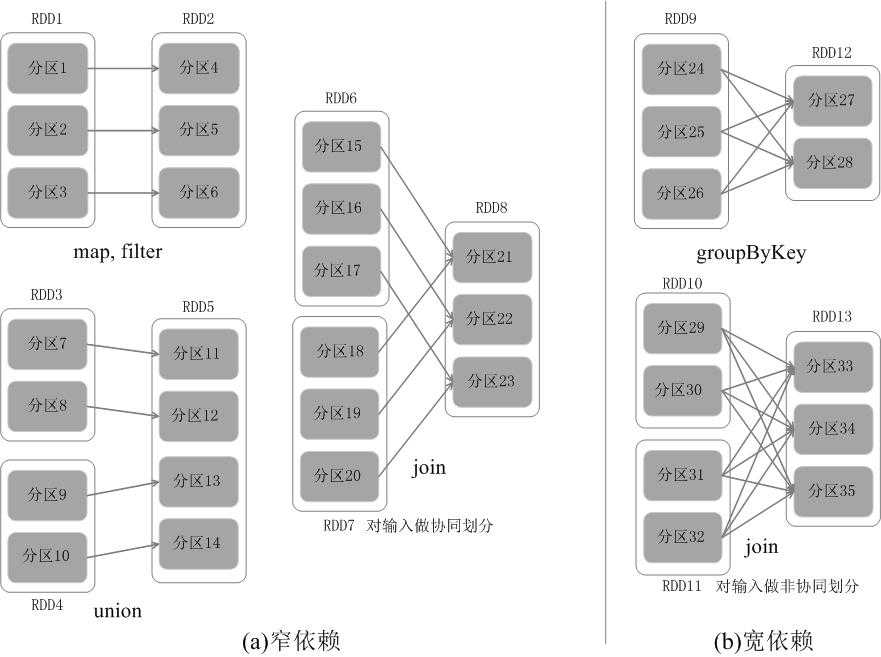
窄依赖往往用于流水线的操作,窄依赖的失败恢复更为高效,而对于宽依赖而言,单个节点失效通常意味着重新计算过程会涉及多个父RDD分区,开销较大,不过宽依赖的用途往往是一个计算阶段的结束时间,对于部分计算产生的小数据进行整合。
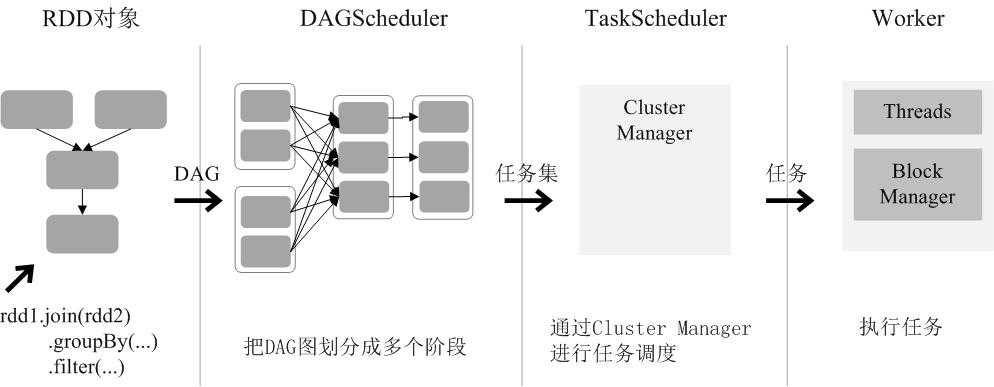
RDD运行过程
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发给各个工作节点(Worker Node)上的Executor去执行。
以上是关于2020/1/18寒假自学——学习进度报告2的主要内容,如果未能解决你的问题,请参考以下文章