Elasticsearch 7.x 之节点集群分片及副本
Posted lgjava
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 7.x 之节点集群分片及副本相关的知识,希望对你有一定的参考价值。
从物理空间概念,Elasticsearch 分布式系统会有 3 个关键点需要学习。本次总结了下面相关内容:
- 分布式
- 节点 & 集群
- 主分片及副本
一、Elasticsearch 分布式
Elasticsearch 分布式特性包括如下几个点:
1.1 高可用
什么是高可用?CAP 定理是分布式系统的基础,也是分布式系统的 3 个指标:
- Consistency(一致性)
- Availability(可用性)
- Partition tolerance(分区容错性)
那高可用(High Availability)是什么?高可用,简称 HA,是系统一种特征或者指标,通常是指,提供一定性能上的服务运行时间,高于平均正常时间段。反之,消除系统服务不可用的时间。
衡量系统是否满足高可用,就是当一台或者多台服务器宕机的时候,系统整体和服务依然正常可用。举个例子,一些知名的网站保证 4 个 9 以上的可用性,也就是可用性超过 99.99%。那 0.01% 就是所谓故障时间的百分比。
Elasticsearch 在高可用性上,体现如下两点:
- 服务可用性:允许部分节点停止服务,整体服务没有影响
- 数据可用性:允许部分节点丢失,最终不会丢失数据
1.2 可扩展
随着公司业务发展,Elasticsearch 也面临两个挑战:
- 搜索数据量从百万到亿量级
- 搜索请求 QPS 也猛增
那么需要将原来节点和增量数据重新从 10 个节点分布到 100 个节点。Elasticsearch 可以横向扩展至数百(甚至数千)的服务器节点,同时可以处理PB级数据。Elasticsearch 为了可扩展性而生,由小规模集群增长为大规模集群的过程几乎完全自动化,这是水平扩展的体现。
1.3 Elasticsearch 分布式特性
上面通过可扩展性,可以看出 Elasticsearch 分布式的好处明显:
- 存储可以水平扩容,水平空间换时间
- 部分节点停止服务,整个集群服务不受影响,照样正常提供服务
Elasticsearch 在后台自动完成了分布式相关工作,如下:
- 自动分配文档到不同分片或者多节点上
- 均衡分配分片到集群节点上,index 和 search 操作时进行负载均衡
- 复制每个分片,支持数据冗余,防止硬件故障数据丢失
- 集群扩容时,无缝整合新节点,并且重新分配分片
- 等等
Elasticsearch 集群知识点如下:
- 不同集群通过名字区分,默认集群名称为 “elasticsearch”
- 集群名 cluster name ,可以通过配置文件修改或者命令行 -E cluster.name=user-es-cluster 进行设置
- 一个集群由多个节点组成
二、Elasticsearch 节点 & 集群
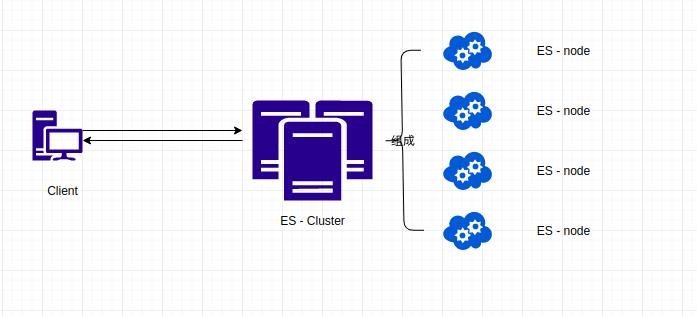
Elasticsearch 集群有多个节点组成,形成分布式集群。那么,什么是节点呢?
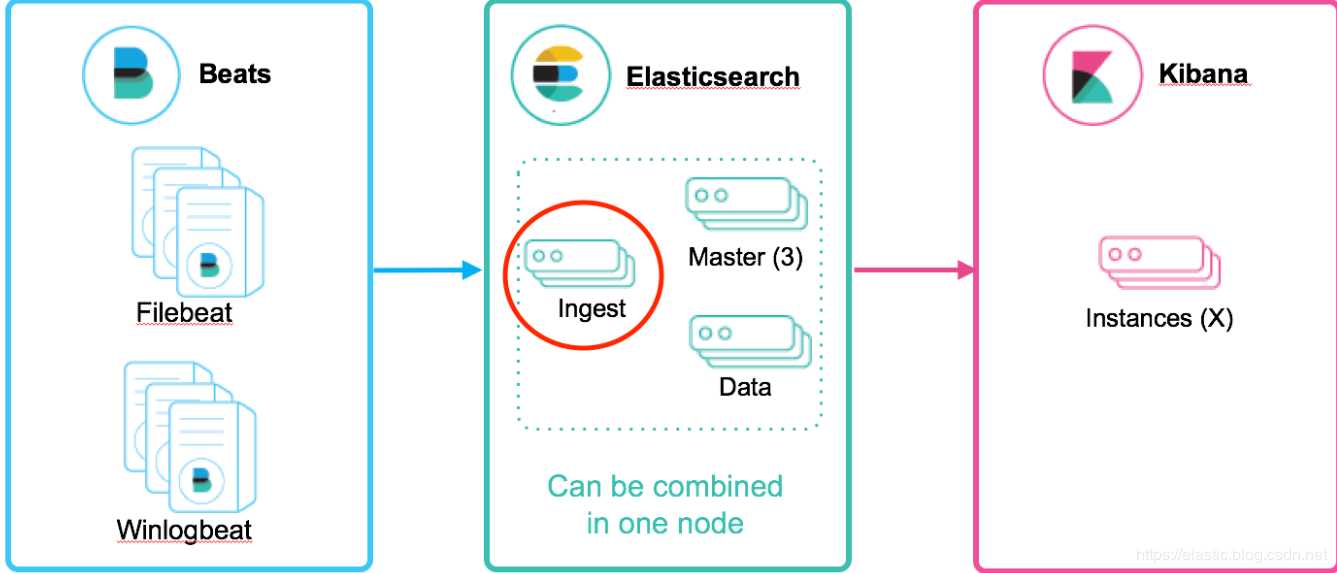
节点(Node),就是一个 Elasticsearch 应用实例。大家都知道 Elasticsearch 源代码是 Java 写的,那么节点就是一个 Java 进程。所以类似 Spring 应用一样,一台服务器或者本机可以运行多个节点,只要对应的端口不同即可。但生产服务器中,一般一台服务器运行一个 Elasticsearch 节点。还有需要注意:
- Elasticsearch 都会有 name ,通过 -E node.name=node01 指定或者配置文件中配置
- 每个节点启动成功,都会分配对应得一个 UID ,保存在 data 目录
可以通过命令 _cluster/health 查看集群的健康状态,如下:
- Green 主分片与副本分片都正常
- Yellow 主分片正常,副本分片不正常
- Red 有主分片不正常,可能某个分片容量超过了磁盘大小等
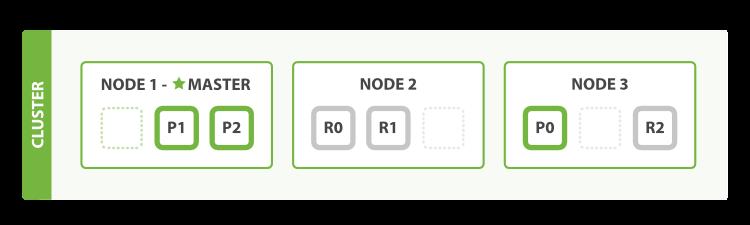
如图,有主(Master)节点和其他节点。那么节点有多少类型呢?
2.1 Master-eligible Node 和 Master Node
Elasticsearch 被启动后,默认就是 Master-eligible Node。然后通过参与选主过程,可以成为 Master Node。具体选主原理,后续单独写一篇文章。Master Node 有什么作用呢?
- Master Node 负责同步集群状态信息:
- 所有节点信息
- 所有索引即其 Mapping 和 Setting 信息
- 所有分片路由信息
- 主节点负责集群相关的操作,例如创建或删除索引,跟踪哪些节点是集群的一部分,以及决定将哪些分片分配给哪些节点。
- 只能 Master 节点可以修改信息,是因为这样就能保证数据得一致性
2.2 Data Node 和 Coordinating Node
Data Node,又称数据节点。用于保存数据,其在数据扩展上起至关重要的作用。
Coordinating Node,是负责接收任何 Client 的请求,包括 REST Client 等。该节点将请求分发到合适的节点,最终把结果汇集到一起。一般来说,每个节点默认起到了 Coordinating Node 的职责。
2.3 其他节点类型
还有其他节点类型,虽然不常见,但需要知道:
- Hot & Warm Node:不同硬件配置的 Data Node,用来实现冷热数据节点架构,降低运维部署的成本
- Machine Learning Node:负责机器学习的节点
- Tribe Node:负责连接不同的集群。支持跨集群搜索 Cross Cluster Search
一般在开发环境中,设置单一的角色节点:
- master node:通过 node.master 配置,默认 true
- data node:通过 node.data 配置,默认 true
- ingest node:通过 node.ingest 配置,默认 true
-
ingest 节点可以看作是数据前置处理转换的节点,支持 pipeline管道 设置,可以使用 ingest 对数据进行过滤、转换等操作,类似于 logstash 中 filter 的作用,功能相当强大。
我把Ingest节点的功能抽象为:大数据处理环节的“ETL”——抽取、转换、加载
-
- coordinating node:默认每个节点都是 coordinating 节点,设置其他类型全部为 false。
-
搜索请求在两个阶段中执行(query 和 fetch),这两个阶段由接收客户端请求的节点 - 协调节点协调。
在请求阶段,协调节点将请求转发到保存数据的数据节点。 每个数据节点在本地执行请求并将其结果返回给协调节点。
在收集fetch阶段,协调节点将每个数据节点的结果汇集为单个全局结果集。
-
- machine learning:通过 node.ml 配置,默认 true,需要通过 x-pack 开启。
三、主分片及副本
同样看这个图,3 个节点分别为 Node1、Node2、Node3。并且 Node3 上面有一个主分片 P0 和一个副本 R2。那什么是主分片呢?
主分片,用来解决数据水平扩展的问题。比如上图这个解决可以将数据分布到所有节点上:
- 节点上可以有主分片,也可以没有主分片
- 主分片在索引创建的时候确定,后续不允许修改。除非 Reindex 操作进行修改
副本,用来备份数据,提高数据的高可用性。副本分片是主分片的拷贝
- 副本分片数,可以动态调整
- 增加副本数,可以一定程度上提高服务读取的吞吐和可用性
如何查看 Elasticsearch 集群的分片配置呢?可以从 settings 从看出:
- number_of_shards 主分片数
- number_of_replicas 副本分片数
{
"my_index": {
"settings": {
"index": {
"number_of_shards": "8",
"number_of_replicas": "1"
}
}
}
}
实战建议:对生产环境中,分片设置很重要,需要最好容量评估与规划
- 根据数据容量评估分配数,设置过小,后续无法水平扩展;单分片数据量太大,也容易导致数据分片耗时严重
- 分片数设置如果太大,会导致资源浪费,性能降低;同时也会影响搜索结果打分和搜索准确性
索引评估,每个索引下面的单分片数不用太大。如何评估呢?比如这个索引 100 G 数据量,那设置 10 个分片,平均每个分片数据量就是 10G 。每个分片 10 G 数据量这么大,耗时肯定严重。所以根据评估的数据量合理安排分片数即可。如果需要调整主分片数,那么需要进行 reindex 等迁索引操作。
小结
从上一篇到这一篇:
- 一个节点,对应一个实例
- 一个节点,可以多个索引
- 一个索引,可以多个分片
- 一个分片,对应底层一个 lucene 分片
比如知道了搜索性能场景,例如多少数据量,多大的写入,是写为主还是查询为主等等,才可以确定:
- 磁盘,推荐 SSD,JVM最大 Xmx 不要超过30G。副本分片至少设置为1。主分片,单个存储不要超过 30 GB,按照这个你推算出分片数,进行设定。
- 集群中磁盘快满的时候,你再增加机器,确实可能导致新建的索引全部分配到新节点上去的可能性。最终导致数据分配不均。所以要记得监控集群,到70%就需要考虑删除数据或是增加节点
- 可以设置最大分片数缓解这个问题。
- 分片的尺寸如果过大,确实也没有快速恢复的办法,所以尽量保证分片的size在40G以下
Cooridnating Node是原来的Client node的,主要功能是来分发请求和合并结果的。新版本已经取消了Client node这种节点角色,在所有节点默认就是Coordinating node,且不能关闭该属性。
如果把node.master, node.data, node.ingest都设为false, 那个这个节点就纯粹是作为Coordinating node, 这种节点需要有足够多的内存和CPU来处理 合并数据集合。
Ingest node主要是通过使用ingest pipeline来对文档在索引之前进行转换或者增强。
Tribe node也是一类特殊的Coordinating node (Client node),这种节点可以连接多个集群,可以对多个集群进行搜索和其他操作。
Ingest 节点能解决什么问题?
上面的Ingest节点介绍太官方,看不大懂怎么办?来个实战场景例子吧。
思考问题1:线上写入数据改字段需求
如何在数据写入阶段修改字段名(不是修改字段值)?
思考问题2:线上业务数据添加特定字段需求
如何在批量写入数据的时候,每条document插入实时时间戳?
这时,脑海里开始对已有的知识点进行搜索。
针对思考问题1:字段值的修改无非:update,update_by_query?但是字段名呢?貌似没有相关接口或实现。
针对思考问题2:插入的时候,业务层面处理,读取当前时间并写入貌似可以,有没有不动业务层面的字段的方法呢?
答案是有的,这就是Ingest节点的妙处。
Ingest节点基本概念
在实际文档索引发生之前,使用Ingest节点预处理文档。Ingest节点拦截批量和索引请求,它应用转换,然后将文档传递回索引或Bulk API。
强调一下: Ingest节点处理时机——在数据被索引之前,通过预定义好的处理管道对数据进行预处理。
默认情况下,所有节点都启用Ingest,因此任何节点都可以处理Ingest任务。我们也可以创建专用的Ingest节点。
要禁用节点的Ingest功能,需要在elasticsearch.yml 设置如:node.ingest:false
这里就涉及几个知识点:
- 1、预处理 pre-process
要在数据索引化(indexing)之前预处理文档。 - 2、管道 pipeline
每个预处理过程可以指定包含一个或多个处理器的管道。
管道的实际组成:
{ "description" : "...", "processors" : [ ... ] }
description:管道功能描述。
processors:注意是数组,可以指定1个或多个处理器。
处理器 processors
每个处理器以某种特定方式转换文档。
例如,管道可能有一个从文档中删除字段的处理器,然后是另一个重命名字段的处理器。
这样,再反过来看第4部分就很好理解了。
Ingest API
Ingest API共分为4种操作,分别对应:
PUT(新增)、
GET(获取)、
DELETE(删除)、
Simulate (仿真模拟)。
模拟管道AP Simulate 针对请求正文中提供的文档集执行特定管道。
除此之外,高阶操作包括:
1、支持复杂条件的Nested类型的操作;
2、限定条件的管道操作;
3、限定条件的正则操作等。
详细内容,参见官网即可。
常见的处理器有如下28种,举例:
append处理器:添加1个或1组字段值;
convert处理器:支持类型转换。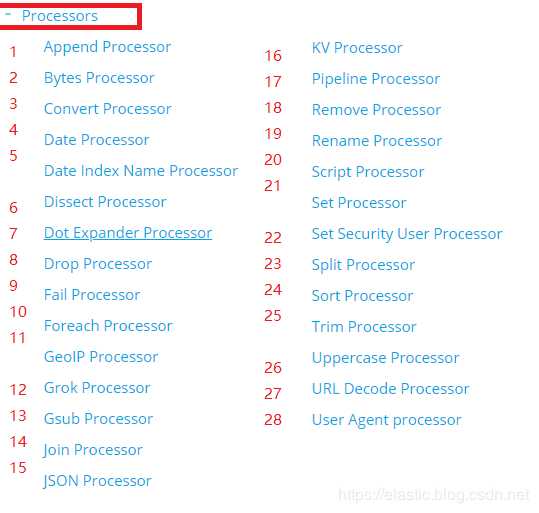
Ingest节点和Logstash Filter 啥区别?
业务选型中,肯定会问到这个问题。
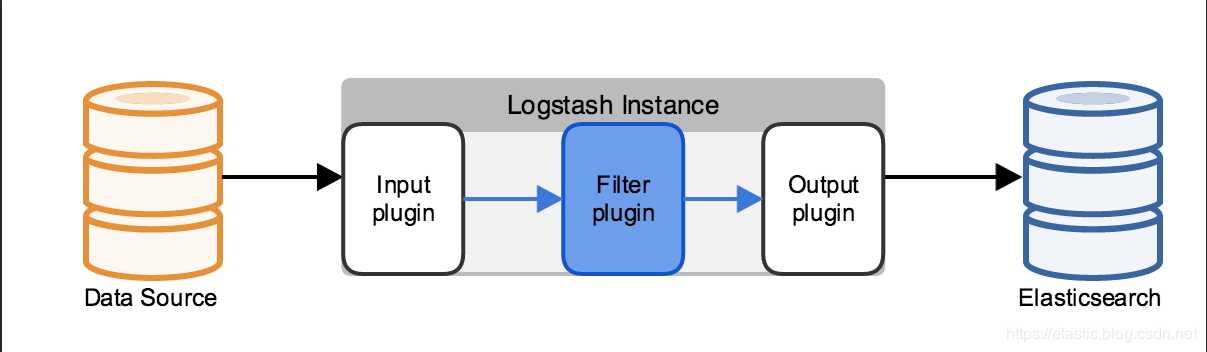
区别一:支持的数据源不同。
Logstash:大量的输入和输出插件(比如:kafka,redis等)可供使用,还可用来支持一系列不同的架构。
Ingest节点:不能从外部来源(例如消息队列或数据库)提取数据,必须批量bulk或索引index请求将数据推送到 Elasticsearch.
区别二:应对数据激增的能力不同。
Logstash:Logstash 可在本地对数据进行缓冲以应对采集骤升情况。如前所述,Logstash 同时还支持与大量不同的消息队列类型进行集成。
Ingest节点:极限情况下会出现:在长时间无法联系上 Elasticsearch 或者 Elasticsearch 无法接受数据的情况下,均有可能会丢失数据。
区别三:处理能力不同。
Logstash:支持的插件和功能点较Ingest节点多很多。
Ingest节点:支持28类处理器操作。Ingest节点管道只能在单一事件的上下文中运行。Ingest通常不能调用其他系统或者从磁盘中读取数据。
区别四:排他式功能支持不同。
Ingest节点:支持采集附件处理器插件,此插件可用来处理和索引常见格式(例如 PPT、XLS 和 PDF)的附件。
Logstash:不支持如上文件附件类型。
master节点
主要功能是维护元数据,管理集群各个节点的状态,数据的导入和查询都不会走master节点,所以master节点的压力相对较小,因此master节点的内存分配也可以相对少些;但是master节点是最重要的,如果master节点挂了或者发生脑裂了,你的元数据就会发生混乱,那样你集群里的全部数据可能会发生丢失,所以一定要保证master节点的稳定性。
data node
是负责数据的查询和导入的,它的压力会比较大,它需要分配多点的内存,选择服务器的时候最好选择配置较高的机器(大内存,双路CPU,SSD... 土豪~);data node要是坏了,可能会丢失一小份数据。
client node
是作为任务分发用的,它里面也会存元数据,但是它不会对元数据做任何修改。client node存在的好处是可以分担下data node的一部分压力;为什么client node能分担data node的一部分压力?因为es的查询是两层汇聚的结果,第一层是在data node上做查询结果汇聚,然后把结果发给client node,client node接收到data node发来的结果后再做第二次的汇聚,然后把最终的查询结果返回给用户;所以我们看到,client node帮忙把第二层的汇聚工作处理了,自然分担了data node的压力。
这里,我们可以举个例子,当你有个大数据查询的任务(比如上亿条查询任务量)丢给了es集群,要是没有client node,那么压力直接全丢给了data node,如果data node机器配置不足以接受这么大的查询,那么就很有可能挂掉,一旦挂掉,data node就要重新recover,重新reblance,这是一个异常恢复的过程,这个过程的结果就是导致es集群服务停止... 但是如果你有client node,任务会先丢给client node,client node要是处理不来,顶多就是client node停止了,不会影响到data node,es集群也不会走异常恢复。
对于es 集群为何要设计这三种角色的节点,也是从分层逻辑去考虑的,只有把相关功能和角色划分清楚了,每种node各尽其责,才能发挥出分布式集群的效果
一般地,ElasticSearch集群中每个节点都有成为主节点的资格,也都存储数据,还可以提供查询服务。这些功能是由两个属性控制的(node.master和node.data)。默认情况下这两个属性的值都是true。
在生产环境下,如果不修改ElasticSearch节点的角色信息,在高数据量,高并发的场景下集群容易出现脑裂等问题,下面详细介绍一下这两个属性的含义以及不同组合可以达到的效果。
一、node.master
这个属性表示节点是否具有成为主节点的资格。
注意:此属性的值为true,并不意味着这个节点就是主节点。因为真正的主节点,是由多个具有主节点资格的节点进行选举产生的。所以,这个属性只是代表这个节点是不是具有主节点选举资格。
二、node.data
这个属性表示节点是否存储数据。
三、四种组合配置方式
(1)node.master: true node.data: true
这种组合表示这个节点即有成为主节点的资格,又存储数据。
如果某个节点被选举成为了真正的主节点,那么他还要存储数据,这样对于这个节点的压力就比较大了。ElasticSearch默认每个节点都是这样的配置,在测试环境下这样做没问题。实际工作中建议不要这样设置,因为这样相当于主节点和数据节点的角色混合到一块了。
(2)node.master: false node.data: true
这种组合表示这个节点没有成为主节点的资格,也就不参与选举,只会存储数据。
这个节点我们称为data(数据)节点。在集群中需要单独设置几个这样的节点负责存储数据,后期提供存储和查询服务。
(3)node.master: true node.data: false
这种组合表示这个节点不会存储数据,有成为主节点的资格,可以参与选举,有可能成为真正的主节点,这个节点我们称为master节点。
(4)node.master: false node.data: false
这种组合表示这个节点即不会成为主节点,也不会存储数据,这个节点的意义是作为一个client(客户端)节点,主要是针对海量请求的时候可以进行负载均衡
ElasticSearch启动时,会占用两个端口9200和9300
9200作为Http协议,主要用于外部通讯
9300作为Tcp协议,jar之间就是通过tcp协议通讯
ES集群之间是通过9300进行通讯
以上是关于Elasticsearch 7.x 之节点集群分片及副本的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch Search API之(Request Body Search 查询主体