协议文档里要求字符串要用GBK编码
Posted cnsend
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了协议文档里要求字符串要用GBK编码相关的知识,希望对你有一定的参考价值。
来自森大科技官方博客
http://www.cnsendblog.com/index.php/?p=328
GPS平台、网站建设、软件开发、系统运维,找森大网络科技!
http://cnsendnet.taobao.com
unicode指的是一种编码字符集,即所谓的万国码,而UTF-8,UTF-16(LE,BE)都只是针对这种字符集的一种编码方式。
为什么要采用Unicode字符集呢,因为它能表示的字符几乎包含了世界上所有的字符,这在需要国际化的应用场景中可以很方便使用,一种字符集就可以表示所有的字符。
那为什么它会有不同的编码方式呢?Unicode字符只是定义了一个码表,即字符与一组数字间的映射,具体这个字符的数字如何在计算机内编码则没有规定,所以人们根据实际的场景需要,使用了不同的编码字符集。
UTF-8,是可变长编码,是多字节编码,但它的编码不需要通过而外的BOM(Byte Order Marker)来说明(当然,也有使用BOM的UTF-8编码的),使用这种编码的好处就是节省了存储空间,但编码效率去降低了,这就是所谓的用时间换空间。
UTF-16,是定长编码,是双字节编码,所以两个字节保存时哪个在前,哪个在后关系到解析出字符的结果。至于会出现BE,和LE的编码,由于每个字符占用了两个字节,在Macintosh (Mac)机和PC机上,对字节顺序的理解是不一致的,这个是历史习惯造成的。如果一个文件不明确说明其UTF-16使用的是BE还是LE时,那么就需要通过BOM来指明了。使用这种编码的好处就是编码效率较高,但毕竟浪费存储空间,这就是所谓的用空间换时间。
2、协议文档里要求字符串要用GBK编码,其实就是汉字转UTF-16BE,C#代码如下所示
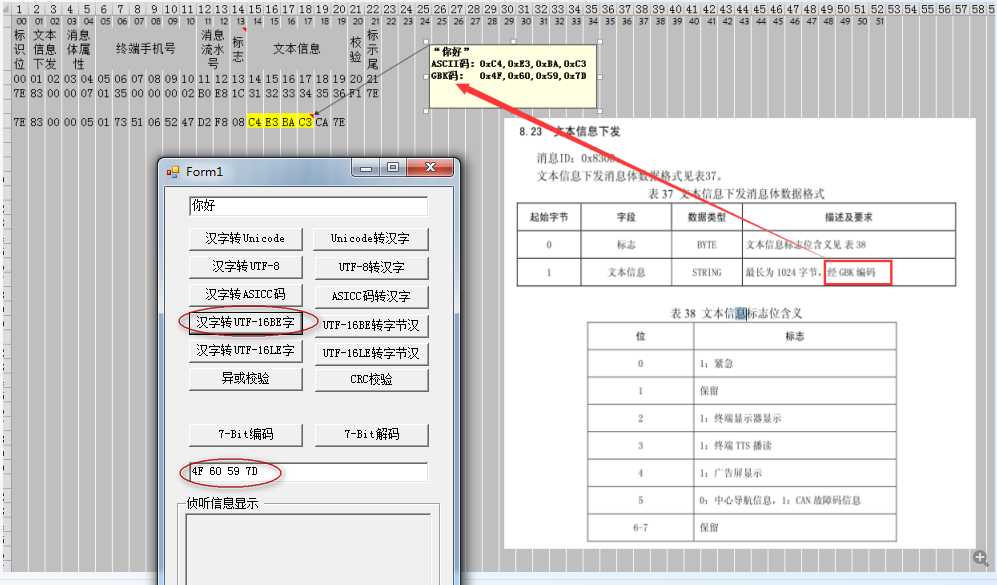
System.Text.Encoding.GetEncoding("UTF-16BE").GetBytes("你好"); //4F 60 59 7D
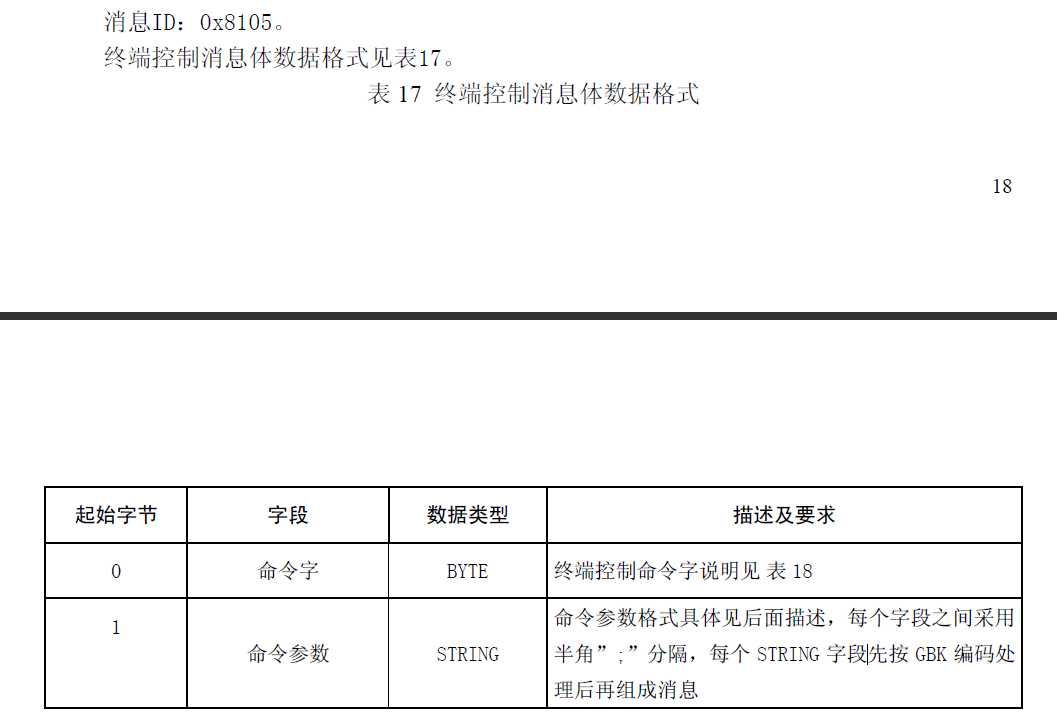
3、808协议文档中,有字符串GBK编码的地方
8105
来自森大科技官方博客
http://www.cnsendblog.com/index.php/?p=328
GPS平台、网站建设、软件开发、系统运维,找森大网络科技!
http://cnsendnet.taobao.com
以上是关于协议文档里要求字符串要用GBK编码的主要内容,如果未能解决你的问题,请参考以下文章